O editor do Downcodes aprendeu que Groq lançou recentemente um incrível mecanismo LLM, cuja velocidade de processamento excede em muito as expectativas da indústria, proporcionando aos desenvolvedores uma experiência interativa de modelo de linguagem em grande escala sem precedentes. Este mecanismo é baseado no código aberto LLama3-8b-8192LLM da Meta e suporta outros modelos. Sua velocidade de processamento chega a 1.256,54 marcos por segundo, o que está significativamente à frente dos chips GPU de empresas como a Nvidia. Esse desenvolvimento inovador não apenas atraiu a atenção generalizada dos desenvolvedores, mas também trouxe uma experiência de aplicação LLM mais rápida e flexível para usuários comuns.
Groq lançou recentemente um mecanismo LLM extremamente rápido em seu site, permitindo que os desenvolvedores executem consultas rápidas e execução de tarefas diretamente em modelos de linguagem grandes.
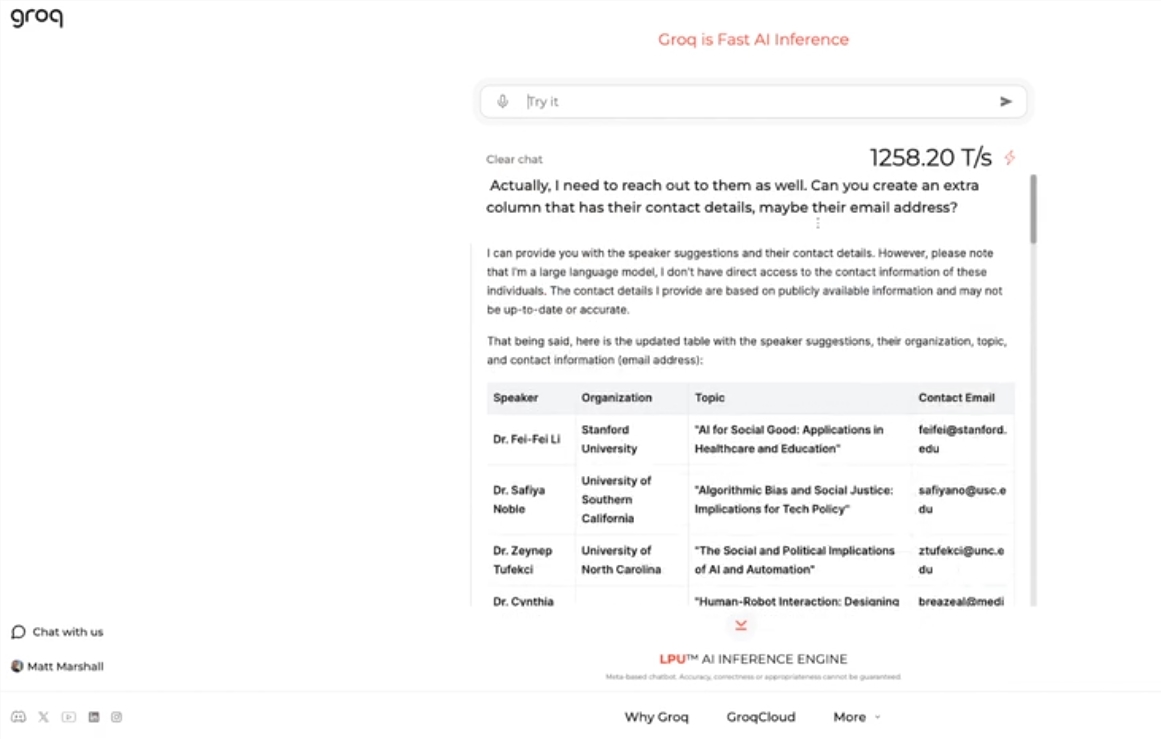
Este mecanismo usa o código aberto LLama3-8b-8192LLM do Meta, suporta outros modelos por padrão e é incrivelmente rápido. De acordo com os resultados dos testes, o mecanismo da Groq pode suportar 1.256,54 marcos por segundo, superando em muito os chips GPU de empresas como a Nvidia. A mudança atraiu ampla atenção de desenvolvedores e não desenvolvedores, demonstrando a velocidade e flexibilidade do chatbot LLM.
O CEO da Groq, Jonathan Ross, disse que o uso de LLMs aumentará ainda mais à medida que as pessoas descobrirem como é fácil usá-los no mecanismo rápido da Groq. Através da demonstração, as pessoas podem perceber que diversas tarefas podem ser facilmente realizadas nessa velocidade, como gerar anúncios de emprego, modificar o conteúdo de artigos, etc. O mecanismo do Groq pode até realizar consultas baseadas em comandos de voz, demonstrando seu poder e facilidade de uso.
Além de oferecer serviços gratuitos de carga de trabalho LLM, Groq também fornece aos desenvolvedores um console que lhes permite alternar facilmente aplicativos desenvolvidos em OpenAI para Groq.
Este método simples de troca atraiu um grande número de desenvolvedores e, atualmente, mais de 280.000 pessoas usaram os serviços da Groq. O CEO Ross disse que até o próximo ano, mais da metade dos cálculos de inferência do mundo serão executados nos chips da Groq, demonstrando o potencial e as perspectivas da empresa no campo da IA.
Destaque:
Groq lança mecanismo LLM ultrarrápido, processando 1.256,54 marcos por segundo, muito mais rápido que a velocidade da GPU
O mecanismo do Groq demonstra a velocidade e flexibilidade dos chatbots LLM, atraindo a atenção de desenvolvedores e não desenvolvedores
?Groq fornece um serviço gratuito de carga de trabalho LLM que tem sido usado por mais de 280.000 desenvolvedores. Espera-se que metade dos cálculos de inferência do mundo sejam executados em seus chips no próximo ano.
O rápido mecanismo LLM da Groq, sem dúvida, traz novas possibilidades para o campo de IA, e seu alto desempenho e facilidade de uso promoverão uma aplicação mais ampla da tecnologia LLM. O editor do Downcodes acredita que vale a pena esperar pelo desenvolvimento futuro do Groq!