Nos últimos anos, o rápido desenvolvimento da tecnologia de inteligência artificial depende fortemente do treinamento de dados massivos. No entanto, o editor do Downcodes descobriu que as pesquisas mais recentes do MIT e de outras instituições apontaram que a dificuldade de obtenção de dados está aumentando dramaticamente. Os dados de rede que antes estavam facilmente disponíveis estão agora sujeitos a restrições cada vez mais rigorosas, o que coloca enormes desafios à formação e ao desenvolvimento da IA. O estudo, que analisou vários conjuntos de dados de código aberto, revela esta dura realidade.
Por trás do rápido desenvolvimento da inteligência artificial, está a surgir um problema sério: a dificuldade de aquisição de dados está a aumentar. A investigação mais recente do MIT e de outras instituições descobriu que os dados da Web que antes eram facilmente acessíveis estão agora a tornar-se cada vez mais difíceis de aceder, o que representa um grande desafio para a formação e investigação em IA.
Os pesquisadores descobriram que os sites rastreados por vários conjuntos de dados de código aberto, como C4, RefineWeb, Dolma, etc., estão estreitando rapidamente seus contratos de licença. Isto não só afecta a formação de modelos comerciais de IA, mas também dificulta a investigação por parte de organizações académicas e sem fins lucrativos.

Esta pesquisa foi conduzida por quatro líderes de equipe do MIT Media Lab, do Wellesley College, da startup de IA Raive e de outras instituições. Observam que as restrições de dados estão a proliferar e as assimetrias e inconsistências de licenciamento estão a tornar-se cada vez mais evidentes.
A equipe de pesquisa usou o Protocolo de Exclusão de Robôs (REP) e os Termos de Serviço (ToS) do site como métodos de pesquisa. Eles descobriram que mesmo rastreadores de grandes empresas de IA como a OpenAI enfrentavam restrições cada vez mais rígidas.
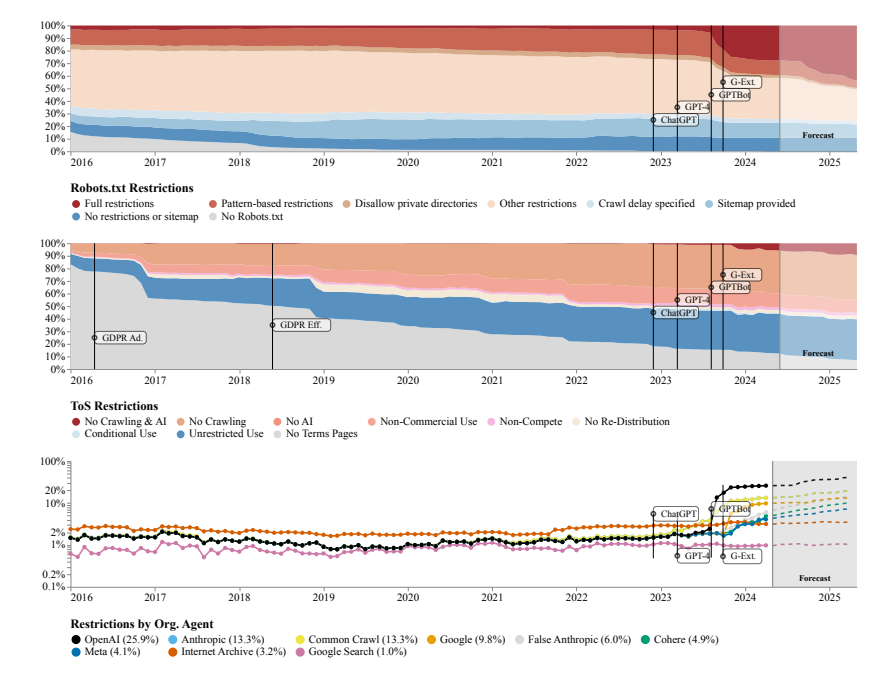
O modelo SARIMA prevê que no futuro, seja através de robots.txt ou ToS, as restrições de dados de sites continuarão a aumentar. Isto sugere que o acesso aos dados da rede aberta se tornará mais difícil.
O estudo também descobriu que os dados rastreados da Internet não são consistentes com o propósito de treinamento do modelo de IA, o que pode ter impacto no alinhamento do modelo, nas práticas de coleta de dados e nos direitos autorais.
A equipe de pesquisa defende a necessidade de acordos mais flexíveis que reflitam os desejos dos proprietários de sites, separem os casos de uso permitidos e não permitidos e sincronizem com os termos de serviço. Ao mesmo tempo, eles querem que os desenvolvedores de IA possam usar dados na web aberta para treinamento e esperam que leis futuras apoiem isso.
Endereço do artigo: https://www.dataprovenance.org/Consent_in_Crisis.pdf
Esta investigação fez soar o alarme sobre o problema da aquisição de dados no domínio da inteligência artificial e também levantou novos desafios para a formação e desenvolvimento de futuros modelos de IA. Como equilibrar a aquisição de dados e os direitos e interesses dos proprietários de websites tornar-se-á uma questão fundamental que precisa de ser seriamente considerada e resolvida no domínio da inteligência artificial. O editor do Downcodes recomenda prestar atenção ao artigo para saber mais detalhes.