O editor de Downcodes lhe dará uma compreensão aprofundada dos segredos do modelo Transformer! Recentemente, um artigo intitulado "Transformer Layers as Painters" explicou vividamente o mecanismo de funcionamento da camada intermediária do modelo Transformer a partir da perspectiva de um "pintor". Através de metáforas e experimentos inteligentes, este artigo revela como funciona a hierarquia do Transformer, fornecendo novas ideias para compreendermos as operações internas de grandes modelos de linguagem. No artigo, o autor compara cada camada do Transformer a um pintor, trabalhando em conjunto para criar uma imagem em grande linguagem, e verifica essa visão através de uma série de experimentos.
No mundo da inteligência artificial, existe um grupo especial de pintores - a estrutura hierárquica no modelo Transformer. São como pincéis mágicos, pintando um mundo colorido na tela da linguagem. Recentemente, um artigo chamado Transformer Layers as Painters fornece uma nova perspectiva para entendermos o mecanismo de funcionamento da camada intermediária do Transformer.
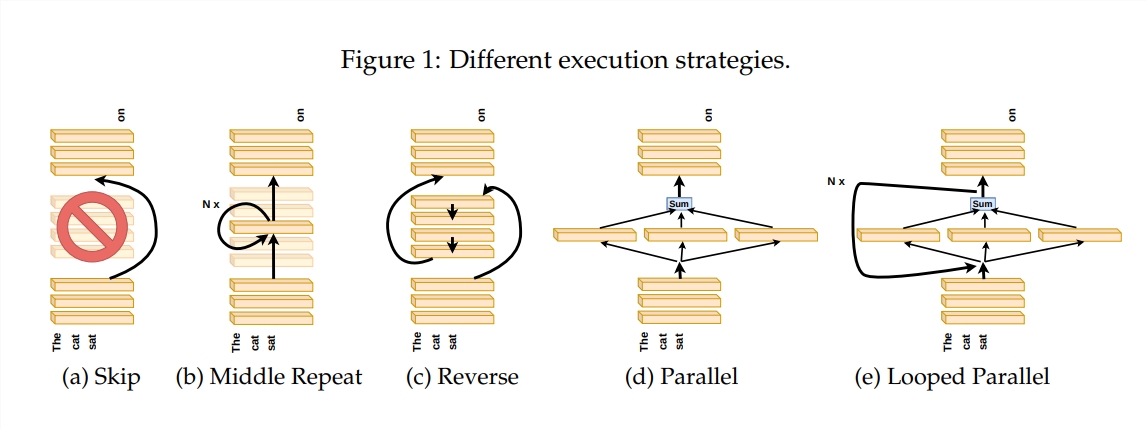
O modelo Transformer, como o modelo de linguagem em larga escala mais popular atualmente, possui bilhões de parâmetros. Cada camada é como um pintor, trabalhando em conjunto para completar uma grande imagem linguística. Mas como esses pintores trabalharam juntos? Como os pincéis e as tintas que usaram diferem? Este artigo tenta responder a essas perguntas.
Para explorar como funciona a camada Transformer, o autor projetou uma série de experimentos, incluindo pular certas camadas, alterar a ordem das camadas ou executar camadas em paralelo. Esses experimentos são como estabelecer regras de pintura diferentes para os pintores verem se eles conseguem se adaptar.
Na metáfora do “pipeline do pintor”, a entrada é vista como uma tela, e o processo de passagem pelas camadas intermediárias é como a passagem da tela na linha de montagem. Cada “pintor”, ou seja, cada camada do Transformador, irá modificar a pintura de acordo com sua expertise. Essa analogia nos ajuda a compreender o paralelismo e a escalabilidade da camada Transformer.
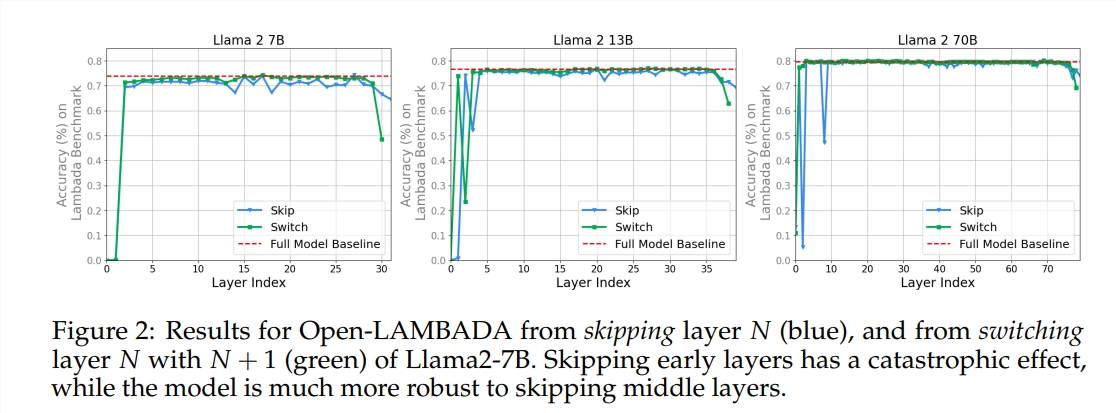
O experimento utilizou dois modelos de linguagem grande (LLM) pré-treinados: Llama2-7B e BERT. O estudo descobriu que os pintores dos níveis intermediários pareciam compartilhar uma caixa de pintura comum – representando o espaço – diferente daqueles dos primeiros e últimos níveis. Os pintores que pulam certas camadas intermediárias têm pouco impacto em toda a pintura, indicando que nem todos os pintores são necessários.
Embora os pintores da camada intermediária usem a mesma caixa de tinta, eles usam suas próprias habilidades para pintar diferentes padrões na tela. Se você simplesmente reutilizar a técnica de um determinado pintor, a pintura perderá seu encanto original.
A ordem em que você desenha é particularmente importante para tarefas matemáticas e de raciocínio que exigem lógica estrita. Para tarefas que dependem da compreensão semântica, o impacto da ordem é relativamente pequeno.
Os resultados da pesquisa mostram que a camada intermediária do Transformer tem um certo grau de consistência, mas não é redundante. Para tarefas matemáticas e de raciocínio, a ordem das camadas é mais importante do que para tarefas semânticas.
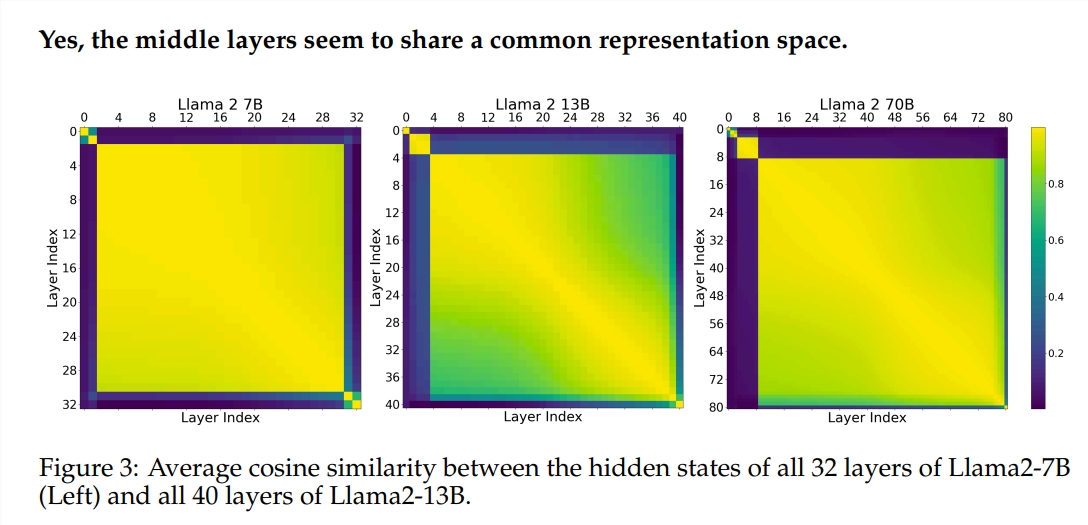
O estudo também descobriu que nem todas as camadas são necessárias e que as camadas intermediárias podem ser ignoradas sem afetar catastroficamente o desempenho do modelo. Além disso, embora as camadas intermediárias compartilhem o mesmo espaço de representação, elas desempenham funções diferentes. A alteração da ordem de execução das camadas resultou na degradação do desempenho, indicando que a ordem tem um impacto importante no desempenho do modelo.
No caminho para explorar o modelo Transformer, muitos pesquisadores estão tentando otimizá-lo, incluindo poda, redução de parâmetros, etc. Esses trabalhos fornecem experiência valiosa e inspiração para a compreensão do modelo Transformer.
Endereço do artigo: https://arxiv.org/pdf/2407.09298v1
Resumindo, este artigo fornece uma nova perspectiva para compreendermos o mecanismo interno do modelo Transformer e fornece novas ideias para otimização futura do modelo. O editor do Downcodes recomenda que os leitores interessados leiam o artigo completo para compreender a fundo os mistérios do modelo Transformer!