O campo do processamento de linguagem natural (PNL) está mudando a cada dia que passa, e o rápido desenvolvimento de grandes modelos de linguagem (LLMs) nos trouxe oportunidades e desafios sem precedentes. Entre eles, a dependência da avaliação do modelo em dados anotados por humanos é um gargalo. O alto custo e o trabalho demorado de coleta de dados limitam a avaliação eficaz e a melhoria contínua do modelo. O editor de Downcodes irá apresentar a você uma nova solução proposta pelos pesquisadores da Meta FAIR - “Auto-learning Evaluator”, que fornece uma nova ideia para resolver este problema.
Na era atual, o campo do processamento de linguagem natural (PNL) está se desenvolvendo rapidamente, e grandes modelos de linguagem (LLMs) podem executar tarefas complexas relacionadas à linguagem com alta precisão, trazendo mais possibilidades para a interação humano-computador. No entanto, um problema significativo na PNL é a dependência de anotações humanas para avaliação de modelos.
Os dados gerados por humanos são essenciais para o treinamento e validação do modelo, mas a coleta desses dados é cara e demorada. Além disso, à medida que os modelos continuam a melhorar, as anotações anteriormente recolhidas podem necessitar de ser atualizadas, tornando-as menos úteis na avaliação de novos modelos. Isto resulta na necessidade de adquirir continuamente novos dados, colocando desafios à escala e à sustentabilidade da avaliação eficaz do modelo.
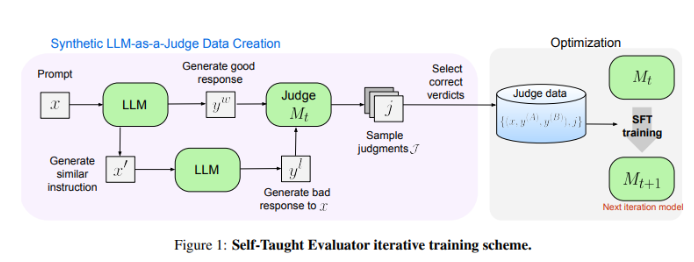
Pesquisadores da Meta FAIR criaram uma nova solução - o "Avaliador Autodidata". Esta abordagem não requer anotações humanas e é treinada em dados gerados sinteticamente. Primeiro, um modelo inicial gera pares de preferências sintéticas contrastantes e, em seguida, o modelo avalia esses pares e os melhora iterativamente, usando seu próprio julgamento para melhorar o desempenho nas iterações subsequentes, reduzindo bastante a dependência de anotações geradas por humanos.
Os pesquisadores testaram o desempenho do “avaliador de autoaprendizagem” usando o modelo Llama-3-70B-Instruct. Este método melhora a precisão do modelo no benchmark RewardBench de 75,4 para 88,7, igualando ou até mesmo excedendo o desempenho de modelos treinados com anotações humanas. Após múltiplas iterações, o modelo final alcançou uma precisão de 88,3 em uma única inferência e 88,7 em uma votação majoritária, demonstrando sua forte estabilidade e confiabilidade.
O "avaliador de autoaprendizagem" fornece uma solução escalável e eficiente para avaliação de modelos de PNL, aproveitando dados sintéticos e autoaperfeiçoamento iterativo, enfrentando os desafios de depender de anotações humanas e avançando no desenvolvimento de modelos de linguagem.
Endereço do artigo: https://arxiv.org/abs/2408.02666
O "avaliador de autoaprendizagem" do Meta FAIR trouxe mudanças revolucionárias na avaliação do modelo de PNL, e seus recursos eficientes e escalonáveis promoverão efetivamente o progresso contínuo dos modelos de linguagem futuros. O resultado desta pesquisa não apenas reduz a dependência de dados anotados por humanos, mas, mais importante ainda, abre caminho para a construção de modelos de PNL mais poderosos e confiáveis. Esperamos mais inovações semelhantes no futuro!