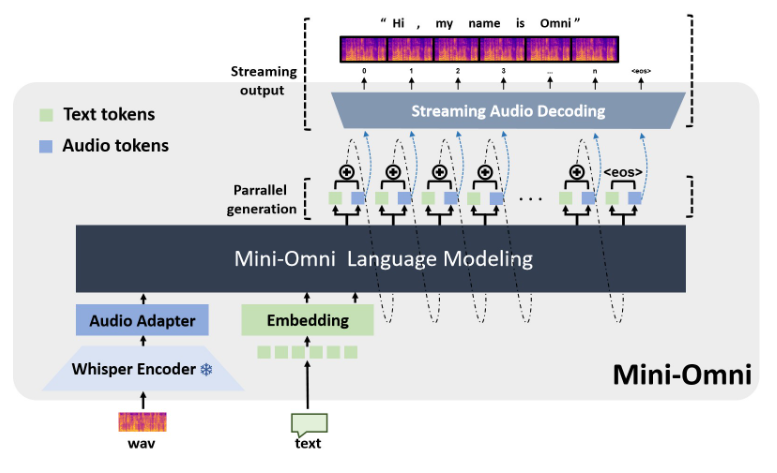
Mini-Omni, um modelo de linguagem multimodal de código aberto em grande escala, está revolucionando a tecnologia de interação por voz. Ele integra tecnologia avançada para realizar entrada e saída de voz em tempo real e tem a capacidade de pensar e falar ao mesmo tempo, proporcionando uma experiência de interação humano-computador mais natural e suave. A principal vantagem do Mini-Omni reside em seus recursos completos de processamento de voz em tempo real. Nenhuma configuração adicional de modelos ASR ou TTS é necessária para desfrutar de conversas tranquilas. Ele suporta múltiplas entradas modais e as converte de forma flexível para se adaptarem a vários cenários complexos e atenderem a diversas necessidades.
Hoje, com o rápido desenvolvimento da inteligência artificial, um modelo de linguagem multimodal de código aberto em grande escala chamado Mini-Omni está liderando a inovação da tecnologia de interação por voz. Este sistema de IA integrado com múltiplas tecnologias avançadas não só permite entrada e saída de voz em tempo real, mas também tem a capacidade única de pensar e falar ao mesmo tempo, proporcionando aos usuários uma experiência de interação natural sem precedentes.
A principal vantagem do Mini-Omni reside em seus recursos completos de processamento de voz em tempo real. Os usuários podem desfrutar de conversas de voz tranquilas sem configuração adicional de modelos de reconhecimento automático de fala (ASR) ou conversão de texto em fala (TTS). Esse design perfeito melhora muito a experiência do usuário e torna a interação humano-computador mais natural e intuitiva.
Além da função de voz, o Mini-Omni também suporta entrada em vários modos, como texto, e pode alternar com flexibilidade entre diferentes modos. Esta capacidade de processamento multimodal permite que o modelo se adapte a vários cenários complexos de interação e atenda às diversas necessidades dos usuários.
Particularmente digna de menção é a função Any Model Can Talk do Mini-Omni. Esta inovação permite que outros modelos de IA integrem facilmente os recursos de voz em tempo real do Mini-Omni, expandindo enormemente as possibilidades de aplicações de IA. Isso não apenas oferece aos desenvolvedores mais opções, mas também abre caminho para a aplicação interdisciplinar da tecnologia de IA.
Em termos de desempenho, o Mini-Omni mostra a sua força abrangente. Ele não apenas funciona bem em tarefas de fala tradicionais, como reconhecimento de fala (ASR) e geração de fala (TTS), mas também mostra forte potencial em tarefas multimodais que exigem capacidades de raciocínio complexas, como TextQA e SpeechQA. Esse recurso abrangente permite que o Mini-Omni lide com uma variedade de cenários de interação complexos, desde simples comandos de voz até tarefas de perguntas e respostas que exigem reflexão aprofundada.
A implementação técnica do Mini-Omni incorpora vários modelos e tecnologias avançadas de IA. Ele usa Qwen2 como base para um grande modelo de linguagem, usa litGPT para treinamento e inferência, usa sussurro para codificação de áudio e snac é responsável pela decodificação de áudio. Este método de fusão multitecnologia não só melhora o desempenho geral do modelo, mas também aumenta a sua adaptabilidade em diferentes cenários.
Para desenvolvedores e pesquisadores, o Mini-Omni oferece uso conveniente. Com etapas simples de instalação, os usuários podem iniciar o Mini-Omni em seu ambiente local e realizar demonstrações interativas por meio de ferramentas como Streamlit e Gradio. Este recurso aberto e fácil de usar oferece forte suporte para a popularização e aplicação inovadora da tecnologia de IA.
Endereço do projeto: https://github.com/gpt-omni/mini-omni
Com suas funções poderosas, uso conveniente e recursos de código aberto, o Mini-Omni traz novas possibilidades para o campo da interação por voz com IA e merece a atenção e exploração de desenvolvedores e pesquisadores. Também vale a pena esperar pelo seu desenvolvimento futuro.