A equipe OpenDataLab de grande modelo de banco de dados do Laboratório de Inteligência Artificial de Xangai (Laboratório de IA de Xangai) lançou uma nova ferramenta inteligente de extração de dados MinerU no 2024 WAIC Science Frontier Main Forum. Esta ferramenta de código aberto visa simplificar o processo de processamento de dados de IA e ajudar os pesquisadores a extrair dados de alta qualidade de documentos massivos com mais eficiência. MinerU suporta uma variedade de formatos de documentos, incluindo PDF, páginas da web, epub, mobi e docx, etc., e os converte no formato Markdown que é fácil de analisar. Seus principais módulos funcionais Magic-PDF e Magic-Doc concentram-se na extração de documentos PDF e páginas da web/e-books, respectivamente, e usam modelos como LayoutLMv3, YOLOv8, UniMERNet e PaddleOCR para obter extração de dados de alta qualidade, melhorando significativamente os dados. eficiência de processamento.
No Fórum Principal WAIC Science Frontier de 2024, a equipe do grande modelo de banco de dados OpenDataLab do Laboratório de Inteligência Artificial de Xangai (Shanghai AI Laboratory) lançou uma nova ferramenta inteligente de extração de dados chamada MinerU. Esta ferramenta foi projetada para simplificar o processo de processamento de dados de IA e ajudar os pesquisadores de IA a extrair dados de alta qualidade de documentos massivos.
MinerU é uma ferramenta completa de extração de dados de documentos e páginas da web de código aberto que pode converter documentos PDF multimodais, incluindo imagens, tabelas, fórmulas, etc. Ele também pode analisar e extrair rapidamente conteúdo formal de páginas da web contendo informações de interferência, como anúncios, e oferece suporte à conversão em lote de vários formatos, como epub, mobi, docx, etc., em Markdown.
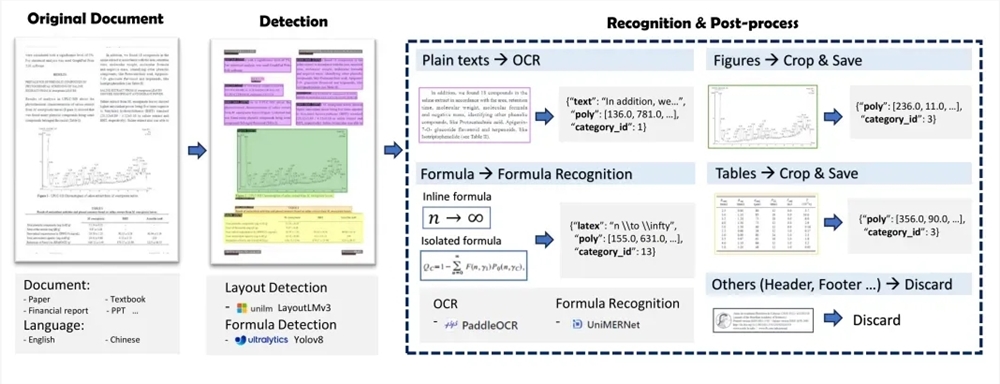
MinerU consiste em duas partes principais: Magic-PDF e Magic-Doc. Magic-PDF concentra-se na extração de documentos PDF e converte PDF no formato Markdown. Ele pode identificar rapidamente elementos de layout de PDF, excluir automaticamente conteúdo não textual e manter a estrutura e o formato do documento original. Magic-Doc é responsável pela extração de páginas web e e-books, apoiando a extração de informações comuns de páginas web como artigos, fóruns, músicas, vídeos, etc., bem como a conversão de formatos de e-books.
A nível técnico, o processo de extração de documentos PDF da MinerU inclui pré-processamento de classificação de documentos PDF, análise de modelo, processamento de pipeline e inspeção de qualidade dos resultados de extração de PDF. Ele utiliza uma série de modelos, como LayoutLMv3, YOLOv8, UniMERNet e PaddleOCR, para obter extração de dados de documentos de alta qualidade.
O lançamento do MinerU não apenas fornece aos pesquisadores de IA uma poderosa ferramenta de processamento de dados, mas também promove a atualização de todo o sistema de ferramentas da cadeia para desenvolvimento e aplicação de grandes modelos.
Link da experiência da comunidade mágica:
https://modelscope.cn/studios/OpenDataLab/MinerU
Link de código aberto do código:
https://github.com/opendatalab/MinerU/
Modelo de código aberto MinerU (PDF-Extract-Kit):
https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit
O código aberto e a facilidade de uso do MinerU facilitarão muito os pesquisadores e desenvolvedores de IA, acelerarão a eficiência do processamento de dados no campo da IA e fornecerão forte suporte para o desenvolvimento de grandes modelos. Bem-vindo a visitar o link para experimentar e usar o MinerU.