Moore Thread abriu o código-fonte de seu grande modelo de compreensão de áudio MooER, que é o primeiro grande modelo de fala de código aberto da indústria baseado em treinamento e inferência de GPU com recursos completos, o que é um marco. MooER oferece suporte ao reconhecimento de fala em chinês e inglês e à tradução fonética chinês-inglês, demonstrando poderosas capacidades de processamento multilíngue. Sua inovadora estrutura de modelo de três partes (codificador, adaptador e decodificador) permite que o modelo processe áudio com eficiência e execute tarefas posteriores. Atualmente, o código de inferência e o modelo treinado com base em 5.000 horas de dados são de código aberto. No futuro, o código de treinamento e o modelo aprimorado treinado com base em 80.000 horas de dados serão de código aberto, o que promoverá muito o desenvolvimento. da tecnologia de IA de áudio em casa e no exterior.
MooER teve um bom desempenho em testes comparativos de vários modelos grandes de compreensão de áudio de código aberto bem conhecidos, com uma taxa de erro de palavras chinesas (CER) tão baixa quanto 4,21% e uma taxa de erro de palavras inglesas (WER) de 17,98%, especialmente BLEU no chinês -Conjunto de testes de tradução em inglês A pontuação chega a 25,2, liderando outros modelos de código aberto. O modelo MooER-80k treinado com base em 80.000 horas de dados tem desempenho mais forte, com CER e WER reduzidos para 3,50% e 12,66% respectivamente, mostrando grande potencial. Este movimento da Moore Thread não apenas demonstra a forte força das GPUs domésticas no campo da IA, mas também injeta uma nova vitalidade no desenvolvimento da tecnologia global de IA de áudio. Espera-se que o MooER traga mais avanços no futuro.
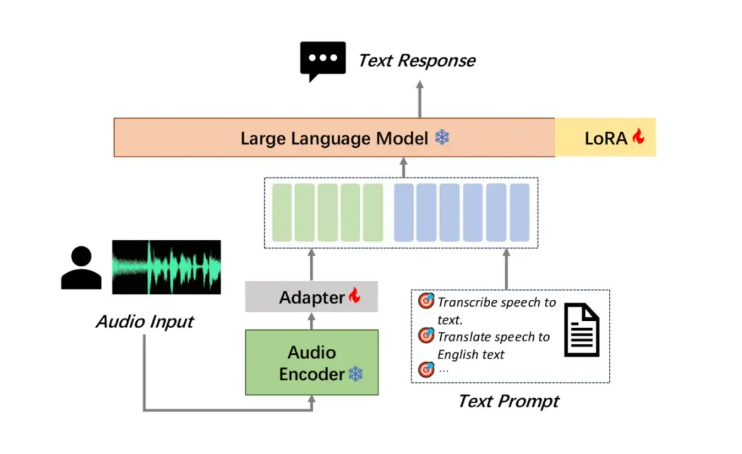
Em testes comparativos com vários modelos grandes de compreensão de áudio de código aberto bem conhecidos, o MooER-5K teve um desempenho excelente. No teste de chinês, sua taxa de erro de palavras (CER) atingiu 4,21%; no teste de inglês, sua taxa de erro de palavras (WER) foi de 17,98%, o que é melhor ou equivalente a outros modelos top. Vale a pena mencionar especialmente que no conjunto de testes de tradução chinês-inglês Covost2zh2en, a pontuação BLEU do MooER chega a 25,2, significativamente à frente de outros modelos de código aberto e atingindo um nível comparável a aplicações de nível industrial.
O que é ainda mais interessante é que o modelo MooER-80k treinado com base em 80.000 horas de dados mostra um desempenho mais poderoso. O CER no conjunto de testes chinês caiu ainda mais para 3,50%, e o WER no conjunto de testes inglês também foi otimizado para 12,66. %. Apresenta um enorme potencial de desenvolvimento.
O MooER de código aberto da Moore Thread não apenas demonstra a força da aplicação das GPUs domésticas no campo de IA, mas também injeta uma nova vitalidade no desenvolvimento da tecnologia global de IA de áudio. À medida que mais dados e códigos de treinamento se tornam de código aberto, a indústria espera que o MooER traga mais avanços em reconhecimento de fala, tradução e outros campos, e promova a popularização e aplicação inovadora da tecnologia de IA de áudio.
Endereço: https://arxiv.org/pdf/2408.05101
O código aberto do MooER marca que as GPUs nacionais fizeram progressos significativos no campo de grandes modelos de IA, fornecendo recursos e plataformas valiosas para desenvolvedores nacionais e estrangeiros. Espera-se que o MooER possa desempenhar um papel em mais cenários de aplicação no futuro e promover a inovação e o desenvolvimento contínuos da tecnologia de IA de áudio.