O ajuste de instruções de modelos grandes é a chave para melhorar seu desempenho. O Tencent Youtu Labs, em colaboração com a Shanghai Jiao Tong University, publicou uma análise detalhada que fornece uma visão aprofundada da avaliação e seleção de conjuntos de dados de ajuste de instruções. Este artigo de 10.000 palavras, baseado em mais de 400 documentos relacionados, fornece orientação abrangente para o ajuste de instruções de grandes modelos nas três dimensões de qualidade, diversidade e importância dos dados, e aponta os desafios da pesquisa existente e das perspectivas de desenvolvimento futuro. direção. O artigo cobre uma variedade de métodos de avaliação, incluindo indicadores desenhados manualmente, indicadores baseados em modelos, pontuação automática GPT e avaliação manual, com o objetivo de ajudar os pesquisadores a selecionar o conjunto de dados ideal e melhorar o desempenho e a estabilidade de grandes modelos.
Com atualizações iterativas contínuas, os modelos grandes estão se tornando mais inteligentes, mas para que eles realmente entendam nossas necessidades, o ajuste de instruções é a chave. Especialistas do Tencent Youtu Lab e da Shanghai Jiao Tong University publicaram conjuntamente uma revisão de 10.000 palavras que discute profundamente a avaliação e seleção de conjuntos de dados de ajuste de instruções, desvendando o mistério de como melhorar o desempenho de grandes modelos.
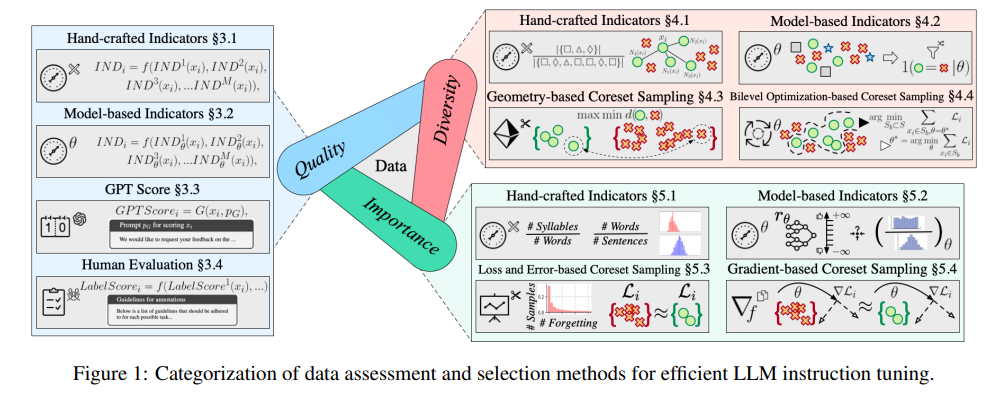
O objetivo dos grandes modelos é dominar a essência do processamento da linguagem natural, e o ajuste das instruções é uma etapa importante no processo de aprendizagem. Os especialistas fornecem uma análise aprofundada sobre como avaliar e selecionar conjuntos de dados para garantir que modelos grandes tenham um bom desempenho em diversas tarefas.
Esta revisão não é apenas surpreendente em extensão, mas também abrange mais de 400 documentos relevantes, fornecendo-nos um guia detalhado das três dimensões da qualidade, diversidade e importância dos dados.
A qualidade dos dados afeta diretamente a eficácia do ajuste das instruções. Os especialistas propuseram uma variedade de métodos de avaliação, incluindo indicadores desenhados à mão, indicadores baseados em modelos, pontuação automática GPT e avaliação manual indispensável.
A avaliação da diversidade centra-se na riqueza do conjunto de dados, incluindo a diversidade de vocabulário, semântica e distribuição geral dos dados. Com diversos conjuntos de dados, os modelos podem generalizar melhor para vários cenários.
A avaliação de importância consiste em selecionar as amostras que são mais críticas para o treinamento do modelo. Isto não só melhora a eficiência do treinamento, mas também garante a estabilidade e precisão do modelo ao enfrentar tarefas complexas.
Embora a investigação actual tenha alcançado alguns resultados, os especialistas também apontaram os desafios existentes, tais como a fraca correlação entre a selecção de dados e o desempenho do modelo, e a falta de padrões unificados para avaliar a qualidade das instruções.
No futuro, os especialistas pedem o estabelecimento de benchmarks especializados para avaliar modelos de ajuste de instruções, melhorando ao mesmo tempo a interpretabilidade dos pipelines de seleção para se adaptarem a diferentes tarefas posteriores.
Esta pesquisa do Tencent Youtu Lab e da Shanghai Jiao Tong University não apenas nos fornece um recurso valioso, mas também aponta a direção para o desenvolvimento de grandes modelos. À medida que a tecnologia continua a avançar, temos razões para acreditar que os grandes modelos se tornarão mais inteligentes e servirão melhor os seres humanos.
Endereço do artigo: https://arxiv.org/pdf/2408.02085
Esta pesquisa fornece orientação valiosa para o ajuste de instruções de modelos grandes e estabelece uma base sólida para o desenvolvimento futuro de modelos grandes. Esperamos resultados de pesquisas mais semelhantes no futuro, que promoverão o progresso contínuo da tecnologia de grandes modelos e servirão melhor a humanidade.