O Tencent Youtu Lab e outras instituições abriram o código aberto do primeiro modelo multimodal de grande linguagem VITA, que pode processar vídeos, imagens, texto e áudio ao mesmo tempo e fornecer uma experiência interativa suave. O surgimento do VITA visa compensar as deficiências dos modelos de linguagem de grande escala existentes no processamento do dialeto chinês. Com base no modelo Mixtral8×7B, o vocabulário chinês é expandido e as instruções bilíngues são aprimoradas, tornando-o proficiente em inglês. e fluente em chinês. Isto marca um progresso significativo para a comunidade de código aberto na compreensão e interação multimodal.
Recentemente, pesquisadores do Tencent Youtu Lab e de outras instituições lançaram o primeiro modelo de linguagem grande multimodal de código aberto VITA, que pode processar vídeos, imagens, texto e áudio ao mesmo tempo, e sua experiência interativa também é de primeira classe.
O modelo VITA nasceu para preencher as deficiências dos grandes modelos de linguagem no processamento de dialetos chineses. É baseado no poderoso modelo Mixtral8×7B, vocabulário chinês expandido e instruções bilíngues aprimoradas, tornando VITA não apenas proficiente em inglês, mas também fluente em chinês.
Principais características:
Compreensão multimodal: a capacidade do VITA de processar vídeo, imagens, texto e áudio não tem precedentes entre os modelos de código aberto.
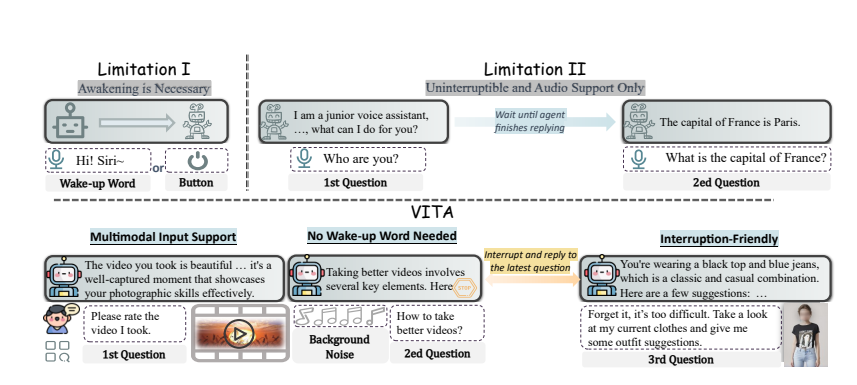
Interação natural: Não há necessidade de dizer “Ei, VITA” todas as vezes, ele pode responder a qualquer momento quando você fala, e mesmo quando você está conversando com outras pessoas, pode ser educado e não interromper à vontade.
Pioneiro de código aberto: VITA é um passo importante para a comunidade de código aberto na compreensão e interação multimodal, estabelecendo as bases para pesquisas subsequentes.
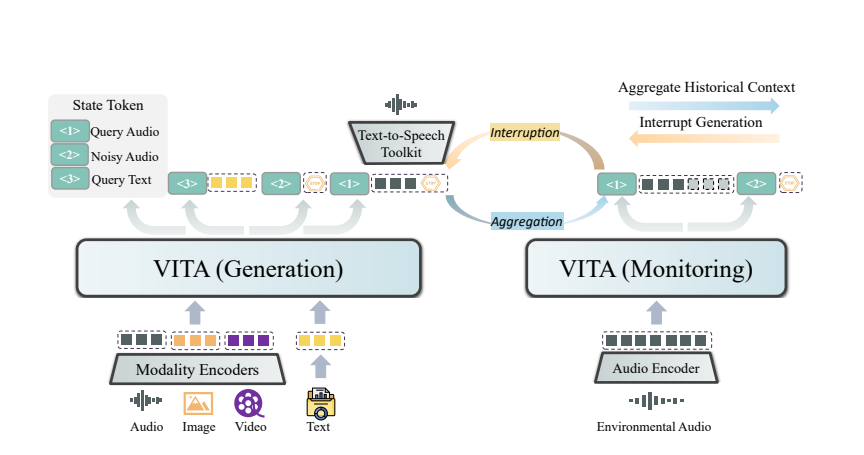
A magia da VITA vem da implantação do seu modelo duplo. Um modelo é responsável por gerar respostas às consultas dos usuários, e o outro modelo rastreia continuamente as informações ambientais para garantir que cada interação seja precisa e oportuna.
VITA pode não apenas conversar, mas também atuar como parceiro de bate-papo quando você se exercita e até mesmo aconselhar quando você viaja. Ele também pode responder perguntas com base nas fotos ou no conteúdo de vídeo que você fornece, mostrando sua poderosa praticidade.
Embora VITA tenha demonstrado grande potencial, ainda está evoluindo em termos de síntese emocional de fala e suporte multimodal. Os pesquisadores planejam permitir que a próxima geração do VITA gere áudio de alta qualidade a partir de entrada de vídeo e texto, e até mesmo explorar a possibilidade de gerar áudio e vídeo de alta qualidade simultaneamente.
O código aberto do modelo VITA não é apenas uma vitória técnica, mas também uma profunda inovação na forma de interação inteligente. Com o aprofundamento das pesquisas, temos motivos para acreditar que VITA nos trará uma experiência interativa mais inteligente e humana.
Endereço do artigo: https://arxiv.org/pdf/2408.05211
O código aberto do VITA fornece uma nova direção para o desenvolvimento de grandes modelos de linguagem multimodais. Suas funções poderosas e experiência interativa conveniente indicam que a interação humano-computador será mais inteligente e humana. Esperamos que a VITA faça maiores avanços no futuro e traga mais conveniência à vida das pessoas.