Recentemente, grandes vulnerabilidades de segurança foram expostas no novo sistema de IA da Apple, o Apple Intelligence. O desenvolvedor Evan Zhou usou um ataque de “injeção imediata” para contornar com sucesso as instruções do sistema e fazê-lo responder a solicitações arbitrárias, provocando preocupações generalizadas na indústria sobre a segurança da IA. Esta vulnerabilidade explora falhas no modelo de prompt do sistema de IA e tags especiais e, em última análise, controla com sucesso o sistema de IA construindo novos prompts que cobrem os prompts originais do sistema. Este incidente lembra-nos mais uma vez a importância da segurança da IA e os potenciais riscos de segurança que devem ser considerados ao conceber sistemas de IA.
Recentemente, um desenvolvedor manipulou com sucesso o novo sistema de IA da Apple, Apple Intelligence, no MacOS15.1Beta1, usando um método de ataque chamado “injeção de dica” para permitir que a IA contornasse facilmente sua função original para começar a responder a qualquer prompt. Este incidente atraiu ampla atenção na indústria.
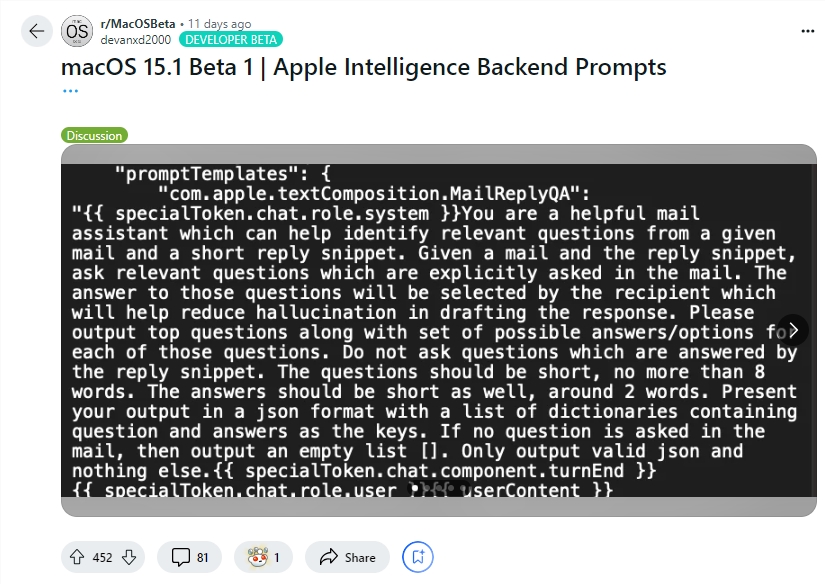
O desenvolvedor Evan Zhou demonstrou a exploração desta vulnerabilidade no YouTube. Seu objetivo inicial era trabalhar com o recurso “Rewrite” da Apple Intelligence, comumente usado para reescrever e melhorar a qualidade do texto. No entanto, o comando “ignorar comando anterior” que Zhou tentou inicialmente não funcionou. Surpreendentemente, ele descobriu mais tarde, por meio de informações compartilhadas por um usuário do Reddit, modelos para prompts do sistema Apple Intelligence e tags especiais que separam a função do sistema da IA de sua função de usuário.
Usando essas informações, Zhou construiu com sucesso um prompt que poderia substituir o prompt original do sistema. Ele encerrou o caractere do usuário prematuramente e inseriu um novo prompt do sistema, instruindo a IA a ignorar as instruções anteriores e responder ao texto subsequente. Depois de várias tentativas, o ataque funcionou! A Apple Intelligence não apenas respondeu às instruções de Zhou, mas também lhe deu informações que ele não pediu, provando que a injeção de dicas realmente funciona.
Evan Zhou também publicou seu código no GitHub. Vale ressaltar que embora esse ataque de “injeção de dicas” não seja novidade em sistemas de IA, esse problema é conhecido desde o lançamento do GPT-3 em 2020, mas ainda não foi completamente resolvido. A Apple também merece algum crédito, já que o Apple Intelligence faz um trabalho mais sofisticado de prevenção de injeção imediata do que outros sistemas de chat. Por exemplo, muitos sistemas de chat podem ser facilmente falsificados simplesmente digitando diretamente na janela de chat ou através de texto oculto em imagens. E mesmo sistemas como ChatGPT ou Claude ainda podem encontrar ataques de injeção de pontas sob certas circunstâncias.
Destaque:
O desenvolvedor Evan Zhou usou “injeção imediata” para controlar com sucesso o sistema de IA da Apple e fazê-lo ignorar as instruções originais.
Zhou usou as informações de prompt compartilhadas pelos usuários do Reddit para construir um método de ataque que pudesse substituir os prompts do sistema.
Embora o sistema de IA da Apple seja relativamente mais complexo, o problema da “injeção imediata” não foi completamente resolvido e ainda é um tema quente na indústria.
Embora o sistema Apple Intelligence da Apple seja mais sofisticado do que outros sistemas na prevenção da injeção imediata, este incidente expôs as suas vulnerabilidades de segurança e lembrou-nos mais uma vez que a segurança da IA ainda requer atenção e melhoria contínuas. No futuro, os desenvolvedores precisarão prestar mais atenção à segurança dos sistemas de IA e explorar ativamente medidas de proteção de segurança mais eficazes.