Grandes modelos de linguagem (LLMs) enfrentam desafios na compreensão de textos longos, e o tamanho da janela de contexto limita suas capacidades de processamento. Para resolver este problema, os pesquisadores desenvolveram o teste de benchmark LooGLE para avaliar a capacidade de compreensão de contexto longo dos LLMs. LooGLE contém 776 documentos ultralongos (média de 19,3 mil palavras) lançados após 2022 e 6.448 instâncias de teste, abrangendo diversos campos, com o objetivo de avaliar de forma mais abrangente a capacidade do modelo de compreender e processar textos longos. Este benchmark avalia o desempenho dos LLMs existentes e fornece uma referência valiosa para o desenvolvimento de modelos futuros.
No campo do processamento de linguagem natural, a compreensão de contextos longos sempre foi um desafio. Embora os grandes modelos de linguagem (LLMs) tenham um bom desempenho em uma variedade de tarefas linguísticas, eles geralmente são limitados ao processar texto que excede o tamanho de sua janela de contexto. Para superar esta limitação, os pesquisadores têm trabalhado arduamente para melhorar a capacidade dos LLMs de compreender textos longos, o que é importante não apenas para a pesquisa acadêmica, mas também para cenários de aplicação do mundo real, como compreensão de conhecimento específico de domínio, longos geração de diálogo e longas histórias ou geração de código, etc., também são cruciais.
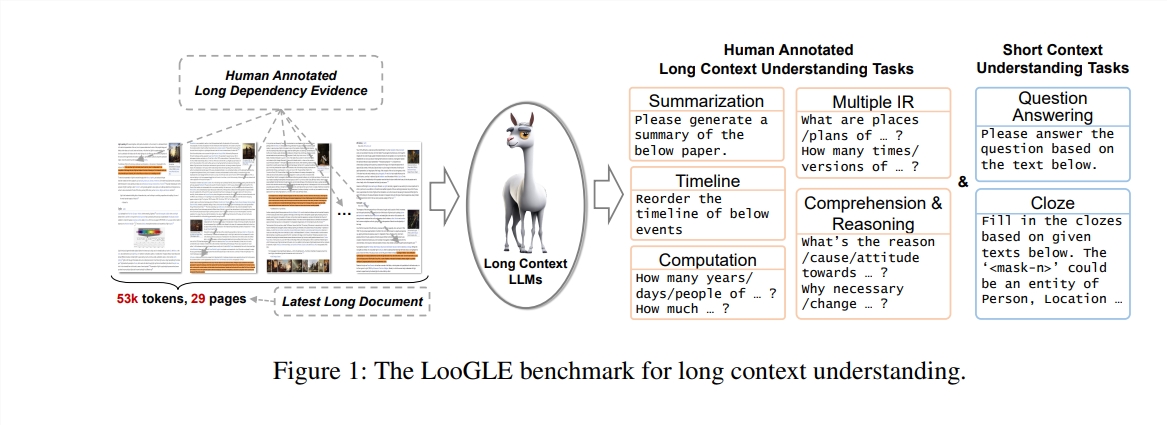
Neste estudo, os autores propõem um novo teste de benchmark - LooGLE (Long Context Generic Language Evaluation), que é especialmente projetado para avaliar a capacidade de compreensão de contexto longo dos LLMs. Este benchmark contém 776 documentos ultralongos após 2022, cada documento contém uma média de 19,3 mil palavras e tem 6.448 instâncias de teste, cobrindo vários campos, como acadêmico, história, esportes, política, arte, eventos e entretenimento, etc.
Recursos do LooGLE
Documentos reais ultralongos: o comprimento dos documentos no ooGLE excede em muito o tamanho da janela de contexto dos LLMs, o que exige que o modelo seja capaz de lembrar e compreender textos mais longos.
Tarefas de dependência longa e curta projetadas manualmente: O teste de benchmark contém 7 tarefas principais, incluindo tarefas de dependência curta e tarefas de dependência longa, para avaliar a capacidade dos LLMs de compreender o conteúdo de dependências longas e curtas.
Documentos relativamente novos: Todos os documentos foram lançados após 2022, o que garante que a maioria dos LLMs modernos não foram expostos a estes documentos durante a pré-formação, permitindo uma avaliação mais precisa das suas capacidades de aprendizagem contextual.
Dados comuns entre domínios: os dados de referência vêm de documentos populares de código aberto, como artigos arXiv, artigos da Wikipedia, roteiros de filmes e TV, etc.
Os pesquisadores conduziram uma avaliação abrangente de oito LLMs de última geração, e os resultados revelaram as seguintes descobertas principais:
O modelo comercial supera o modelo de código aberto em desempenho.
Os LLMs têm um bom desempenho em tarefas de curta dependência, mas apresentam desafios em tarefas mais complexas de longa dependência.
Os métodos baseados na aprendizagem do contexto e nas cadeias de pensamento fornecem apenas melhorias limitadas na compreensão do contexto a longo prazo.
Técnicas baseadas em recuperação mostram vantagens significativas na resposta a perguntas curtas, enquanto estratégias para estender o comprimento da janela de contexto por meio de arquitetura Transformer otimizada ou codificação posicional têm impacto limitado na compreensão de contexto longo.
O benchmark LooGLE não apenas fornece um esquema de avaliação sistemático e abrangente para avaliar LLMs de contexto longo, mas também fornece orientação para o desenvolvimento futuro de modelos com capacidades de “verdadeira compreensão de contexto longo”. Todo o código de avaliação foi publicado no GitHub para referência e uso pela comunidade de pesquisa.
Endereço do artigo: https://arxiv.org/pdf/2311.04939
Endereço do código: https://github.com/bigai-nlco/LooGLE
O benchmark LooGLE fornece uma ferramenta importante para avaliar e melhorar as capacidades de compreensão de textos longos dos LLMs, e os resultados de sua pesquisa são de grande importância na promoção do desenvolvimento do campo do processamento de linguagem natural. As direções de melhoria propostas pelos pesquisadores merecem atenção. Acredito que no futuro surgirão LLMs cada vez mais poderosos para lidar melhor com textos longos.