A Apple e a Meta AI lançaram em conjunto uma nova tecnologia chamada LazyLLM, que foi projetada para melhorar significativamente a eficiência de modelos de linguagem grandes (LLM) no processamento de raciocínio de textos longos. Quando o LLM atual processa prompts longos, a complexidade computacional do mecanismo de atenção aumenta com o quadrado do número de tokens, resultando em velocidade lenta, especialmente no estágio de pré-carregamento. LazyLLM seleciona dinamicamente tokens importantes para cálculo, reduzindo efetivamente a quantidade de cálculos, e introduz o mecanismo Aux Cache para restaurar com eficiência tokens removidos, aumentando significativamente a velocidade e garantindo a precisão.
Recentemente, a equipe de pesquisa da Apple e os pesquisadores da Meta AI lançaram em conjunto uma nova tecnologia chamada LazyLLM, que melhora a eficiência de modelos de linguagem grandes (LLM) no raciocínio de textos longos.
Como todos sabemos, o LLM atual frequentemente enfrenta problemas de lentidão ao processar prompts longos, especialmente durante o estágio de pré-carga. Isso ocorre principalmente porque a complexidade computacional das arquiteturas de transformadores modernas ao calcular a atenção cresce quadraticamente com o número de tokens na dica. Portanto, ao usar o modelo Llama2, o tempo de cálculo do primeiro token é frequentemente 21 vezes maior que o das etapas de decodificação subsequentes, representando 23% do tempo de geração.
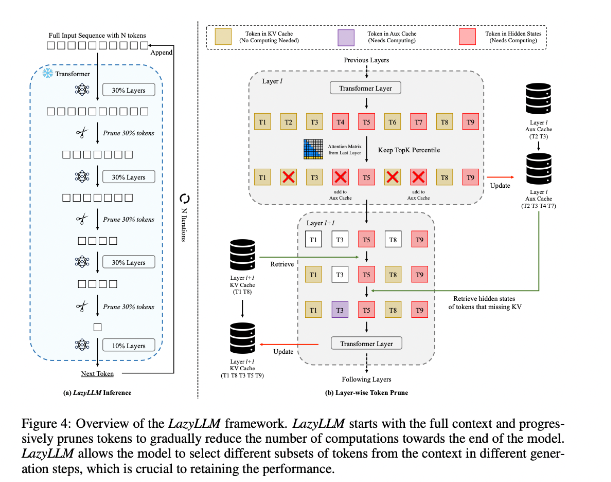
Para melhorar esta situação, os pesquisadores propuseram o LazyLLM, que é um novo método para acelerar a inferência do LLM selecionando dinamicamente o método de cálculo de tokens importantes. O núcleo do LazyLLM é avaliar a importância de cada token com base na pontuação de atenção da camada anterior, reduzindo gradualmente a quantidade de cálculo. Ao contrário da compactação permanente, o LazyLLM pode restaurar tokens removidos quando necessário para garantir a precisão do modelo. Além disso, o LazyLLM introduz um mecanismo chamado Aux Cache, que pode armazenar o estado implícito de tokens removidos para restaurar esses tokens com eficiência e evitar a degradação do desempenho.
O LazyLLM se destaca na velocidade de inferência, principalmente nas etapas de pré-preenchimento e decodificação. As três principais vantagens desta técnica são que ela é compatível com qualquer LLM baseado em transformador, não requer retreinamento do modelo durante a implementação e tem um desempenho muito eficaz em uma variedade de tarefas de linguagem. A estratégia de poda dinâmica do LazyLLM permite reduzir significativamente a quantidade de cálculo, ao mesmo tempo que retém os tokens mais importantes, aumentando assim a velocidade de geração.
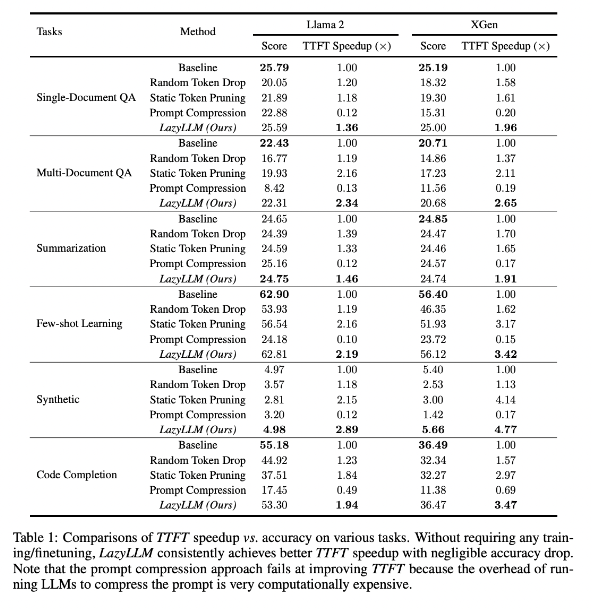
Os resultados da pesquisa mostram que o LazyLLM tem um bom desempenho em tarefas de vários idiomas, com a velocidade do TTFT aumentada em 2,89 vezes (para Llama2) e 4,77 vezes (para XGen), enquanto a precisão é quase a mesma da linha de base. Quer se trate de respostas a perguntas, geração de resumos ou tarefas de conclusão de código, o LazyLLM pode atingir uma velocidade de geração mais rápida e um bom equilíbrio entre desempenho e velocidade. Sua estratégia de poda progressiva aliada à análise camada por camada estabelece a base para o sucesso do LazyLLM.
Endereço do artigo: https://arxiv.org/abs/2407.14057
Destaques:
LazyLLM acelera o processo de raciocínio LLM selecionando dinamicamente tokens importantes, especialmente em cenários de texto longo.
Esta tecnologia pode melhorar significativamente a velocidade de inferência, e a velocidade do TTFT pode ser aumentada em até 4,77 vezes, mantendo alta precisão.
LazyLLM não requer modificações nos modelos existentes, é compatível com qualquer LLM baseado em conversor e é fácil de implementar.
Em suma, o surgimento do LazyLLM fornece novas ideias e soluções eficazes para resolver o problema da eficiência do raciocínio de textos longos do LLM. Seu excelente desempenho em velocidade e precisão indica que ele desempenhará um papel importante em futuras aplicações de grandes modelos. Esta tecnologia tem amplas perspectivas de aplicação e vale a pena aguardar seu desenvolvimento e aplicação.