A Apple, juntamente com a Universidade de Washington e outras instituições, lançou um poderoso modelo de linguagem chamado DCLM como código aberto, com um tamanho de parâmetro de 700 milhões e uma quantidade surpreendente de dados de treinamento atingindo 2,5 trilhões de tokens de dados. DCLM não é apenas um modelo de linguagem eficiente, mas, mais importante, fornece uma ferramenta chamada "Dataset Competition" (DataComp) para otimizar o conjunto de dados do modelo de linguagem. Esta inovação não só melhora o desempenho do modelo, mas também fornece novos métodos e padrões para a pesquisa de modelos de linguagem, o que merece atenção.
Recentemente, a equipe de inteligência artificial da Apple cooperou com muitas instituições, como a Universidade de Washington, para lançar um modelo de linguagem de código aberto chamado DCLM. Este modelo possui 700 milhões de parâmetros e usa até 2,5 trilhões de tokens de dados durante o treinamento para nos ajudar a compreender e gerar melhor a linguagem.
Então, o que é um modelo de linguagem? Simplificando, é um programa que pode analisar e gerar linguagem, ajudando-nos a realizar diversas tarefas como tradução, geração de texto e análise de sentimento. Para que esses modelos tenham um melhor desempenho, precisamos de conjuntos de dados de qualidade. Porém, obter e organizar esses dados não é uma tarefa fácil, pois precisamos filtrar conteúdos irrelevantes ou prejudiciais e remover informações duplicadas.
Para enfrentar esse desafio, a equipe de pesquisa da Apple lançou o DataComp for Language Models (DCLM), uma ferramenta de otimização de conjuntos de dados para modelos de linguagem. Recentemente, eles abriram o código-fonte do modelo DCIM e do conjunto de dados na plataforma Hugging Face. As versões de código aberto incluem DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 e dclm-baseline-1.0-parquet. Os pesquisadores podem conduzir um grande número de experimentos por meio desta plataforma. e encontre a melhor solução.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
O principal ponto forte do DCLM é seu fluxo de trabalho estruturado. Os pesquisadores podem escolher modelos de diferentes tamanhos dependendo de suas necessidades, variando de 412 milhões a 700 milhões de parâmetros, e também podem experimentar diferentes métodos de curadoria de dados, como desduplicação e filtragem. Através destas experiências sistemáticas, os investigadores podem avaliar claramente a qualidade de diferentes conjuntos de dados. Isto não só estabelece as bases para pesquisas futuras, mas também nos ajuda a compreender como melhorar o desempenho do modelo, melhorando o conjunto de dados.
Por exemplo, usando o conjunto de dados de benchmark estabelecido pelo DCLM, a equipe de pesquisa treinou um modelo de linguagem com 700 milhões de parâmetros e alcançou uma precisão de 5 disparos de 64% no teste de benchmark MMLU. Esta é uma melhoria de 6,6 em comparação com o anterior! nível mais alto em pontos percentuais e usa 40% menos recursos de computação. O desempenho do modelo básico DCLM também é comparável ao Mistral-7B-v0.3 e Llama38B, que requerem muito mais recursos computacionais.
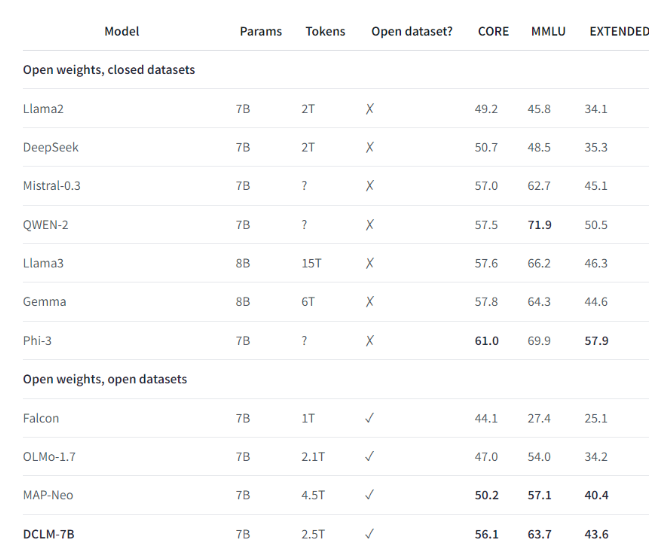
O lançamento do DCLM fornece uma nova referência para a pesquisa de modelos de linguagem, ajudando os cientistas a melhorar sistematicamente o desempenho do modelo e, ao mesmo tempo, reduzindo os recursos computacionais necessários.
Destaques:
1️⃣ A Apple AI cooperou com várias instituições para lançar o DCLM, criando um poderoso modelo de linguagem de código aberto.
2️⃣ O DCLM fornece ferramentas padronizadas de otimização de conjuntos de dados para ajudar os pesquisadores a conduzir experimentos eficazes.
3️⃣ O novo modelo faz progressos significativos em testes importantes, ao mesmo tempo que reduz os requisitos de recursos computacionais.
Em suma, o código aberto do DCLM injetou nova vitalidade no campo da pesquisa de modelos de linguagem, e espera-se que seu modelo eficiente e ferramentas de otimização de conjuntos de dados promovam um desenvolvimento mais rápido no campo e promovam o nascimento de modelos de linguagem mais poderosos e eficientes. No futuro, esperamos que o DCLM traga resultados de pesquisa mais surpreendentes.