A equipe Alibaba Tongyi Qianwen lançou a série Qwen2 de modelos de código aberto. Esta série inclui 5 tamanhos de modelos de pré-treinamento e ajuste fino de instrução. O número de parâmetros e desempenho foram significativamente melhorados em comparação com a geração anterior Qwen1.5. A série Qwen2 também fez um grande avanço em recursos multilíngues, suportando 27 idiomas além do inglês e do chinês. Em termos de compreensão da linguagem natural, codificação, capacidades matemáticas, etc., o modelo grande (70B+ parâmetros) tem um bom desempenho, especialmente o modelo Qwen2-72B, que supera a geração anterior em desempenho e número de parâmetros. Este lançamento marca um novo patamar na tecnologia de inteligência artificial, proporcionando possibilidades mais amplas para aplicação e comercialização global de IA.
Esta manhã, a equipe do Alibaba Tongyi Qianwen lançou a série Qwen2 de modelos de código aberto. Esta série de modelos inclui 5 tamanhos de modelos pré-treinados e ajustados por instrução: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B e Qwen2-72B. As principais informações mostram que o número de parâmetros e o desempenho desses modelos foram significativamente melhorados em comparação com a geração anterior Qwen1.5.
Para as capacidades multilíngues do modelo, a série Qwen2 investiu muito esforço no aumento da quantidade e qualidade do conjunto de dados, abrangendo outros 27 idiomas, exceto inglês e chinês. Após testes comparativos, o modelo grande (70B + parâmetros) teve um bom desempenho em compreensão de linguagem natural, codificação, capacidades matemáticas, etc. O modelo Qwen2-72B superou a geração anterior em termos de desempenho e número de parâmetros.
O modelo Qwen2 não apenas demonstra fortes capacidades na avaliação de modelos básicos de linguagem, mas também alcança resultados impressionantes na avaliação de modelos de ajuste de instruções. Seus recursos multilíngues apresentam bom desempenho em testes de benchmark como M-MMLU e MGSM, demonstrando o poderoso potencial do modelo de ajuste de instruções Qwen2.
Os modelos da série Qwen2 lançados desta vez marcam um novo patamar na tecnologia de inteligência artificial, oferecendo possibilidades mais amplas para aplicações e comercialização globais de IA. Olhando para o futuro, o Qwen2 expandirá ainda mais a escala do modelo e as capacidades multimodais para acelerar o desenvolvimento do campo de IA de código aberto.
Informações do modeloA série Qwen2 inclui 5 tamanhos de modelos básicos e ajustados por comando, incluindo Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B e Qwen2-72B. Explicamos as principais informações de cada modelo na tabela abaixo:
Modelo Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B # Parâmetro 049 milhões 154 milhões 707B57.41B72.71B # Parâmetro não-Emb 035 milhões 131B598 milhões 5632 milhões 7021B A garantia de qualidade é realmente realmente de verdadeiro laço incorporado verdadeiro verdadeiro falso falso falso falso comprimento do contexto 32 mil 32 mil 128 mil 64 mil 128 milEspecificamente, em Qwen1.5, apenas Qwen1.5-32B e Qwen1.5-110B usaram Group Query Attention (GQA). Desta vez, aplicamos GQA para todos os tamanhos de modelo para que eles aproveitem os benefícios de velocidades mais rápidas e menor consumo de memória na inferência de modelo. Para modelos pequenos, preferimos aplicar embeddings vinculados porque embeddings grandes e esparsos respondem por uma grande parte dos parâmetros totais do modelo.
Em termos de comprimento de contexto, todos os modelos de linguagem base foram pré-treinados em dados de comprimento de contexto de tokens de 32K, e observamos capacidades de extrapolação satisfatórias de até 128K na avaliação PPL. No entanto, para modelos ajustados à instrução, não estamos satisfeitos apenas com a avaliação do PPL; precisamos que o modelo seja capaz de compreender corretamente o longo contexto e completar a tarefa; Na tabela, listamos as capacidades de comprimento de contexto do modelo de ajuste de instrução, conforme avaliado pela avaliação na tarefa Needlein a Haystack. É importante notar que, quando aprimorados com YARN, os modelos Qwen2-7B-Instruct e Qwen2-72B-Instruct mostram capacidades impressionantes e podem lidar com comprimentos de contexto de até 128 mil tokens.
Fizemos esforços significativos para aumentar a quantidade e a qualidade dos conjuntos de dados de pré-treinamento e de instrução, abrangendo vários idiomas além do inglês e do chinês, para aprimorar suas capacidades multilíngues. Embora grandes modelos de linguagem tenham a capacidade inerente de generalização para outras línguas, enfatizamos explicitamente a inclusão de outras 27 línguas em nosso treinamento:
Idiomas Regionais Europeu Ocidental Alemão, Francês, Espanhol, Português, Italiano, Holandês Leste Europeu e Central Russo, Tcheco, Polonês Oriente Médio Árabe, Persa, Hebraico, Turco Leste Asiático Japonês, Coreano Sudeste Asiático Vietnamita, Tailandês, Indonésio, Malaio, Laos, birmanês, cebuano, khmer, tagalo, hindi do sul da Ásia, bengali, urduAlém disso, colocamos um esforço significativo para resolver os problemas de transcodificação que frequentemente surgem em avaliações multilíngues. Portanto, a capacidade do nosso modelo de lidar com esse fenômeno é significativamente melhorada. Avaliações usando dicas que normalmente provocam troca de código entre idiomas confirmaram uma redução significativa nos problemas relacionados.
DesempenhoOs resultados dos testes comparativos mostram que o desempenho do modelo em grande escala (parâmetros 70B+) foi significativamente melhorado em comparação com Qwen1.5. Este teste centrou-se no modelo de grande escala Qwen2-72B. Em termos de modelos de linguagem básica, comparamos o desempenho do Qwen2-72B e dos melhores modelos abertos atuais em termos de compreensão de linguagem natural, aquisição de conhecimento, capacidades de programação, capacidades matemáticas, capacidades multilíngues e outras capacidades. Graças a conjuntos de dados cuidadosamente selecionados e métodos de treinamento otimizados, o Qwen2-72B supera os modelos líderes como o Llama-3-70B e até supera a geração anterior Qwen1.5- com um número menor de parâmetros.
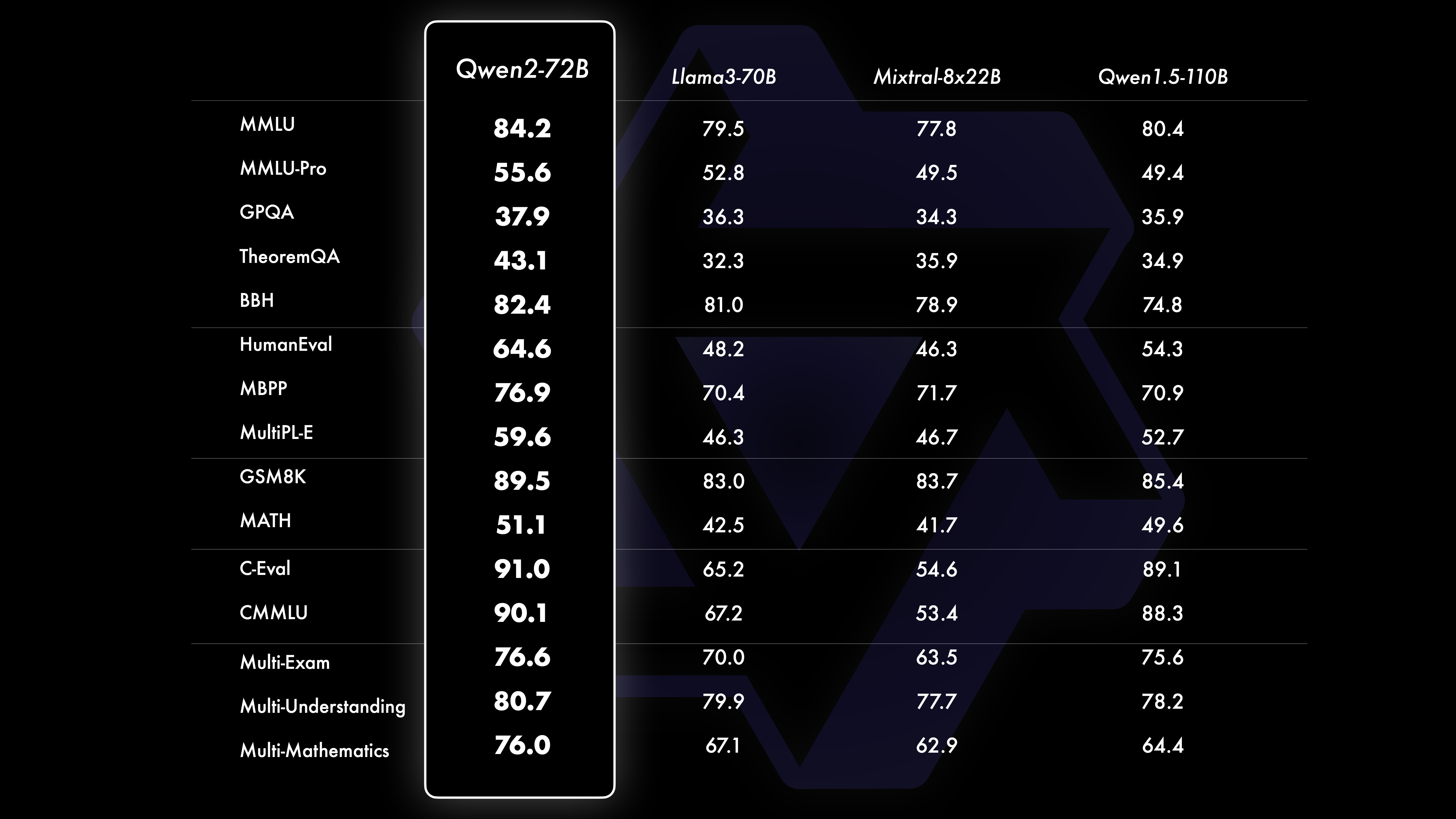
Após um extenso pré-treinamento em larga escala, realizamos um pós-treinamento para aprimorar ainda mais a inteligência de Qwen e torná-lo mais próximo dos humanos. Este processo melhora ainda mais as capacidades do modelo em áreas como codificação, matemática, raciocínio, seguimento de instruções e compreensão multilíngue. Além disso, alinha o resultado do modelo com os valores humanos, garantindo que seja útil, honesto e inofensivo. Nossa fase pós-treinamento é projetada com os princípios de treinamento escalonável e anotação humana mínima. Especificamente, estudamos como obter dados de apresentação e dados de preferência de alta qualidade, confiáveis, diversificados e criativos por meio de várias estratégias de alinhamento automático, como amostragem de rejeição para matemática, feedback de execução para codificação e acompanhamento de instruções e tradução reversa para escrita criativa. ., supervisão escalonável de dramatização e muito mais. Quanto ao treinamento, usamos uma combinação de ajuste fino supervisionado, treinamento em modelo de recompensa e treinamento on-line de DPO. Também empregamos um novo otimizador de mesclagem on-line para minimizar as taxas de alinhamento. Esses esforços combinados melhoram muito as capacidades e a inteligência dos nossos modelos, conforme mostrado na tabela abaixo.
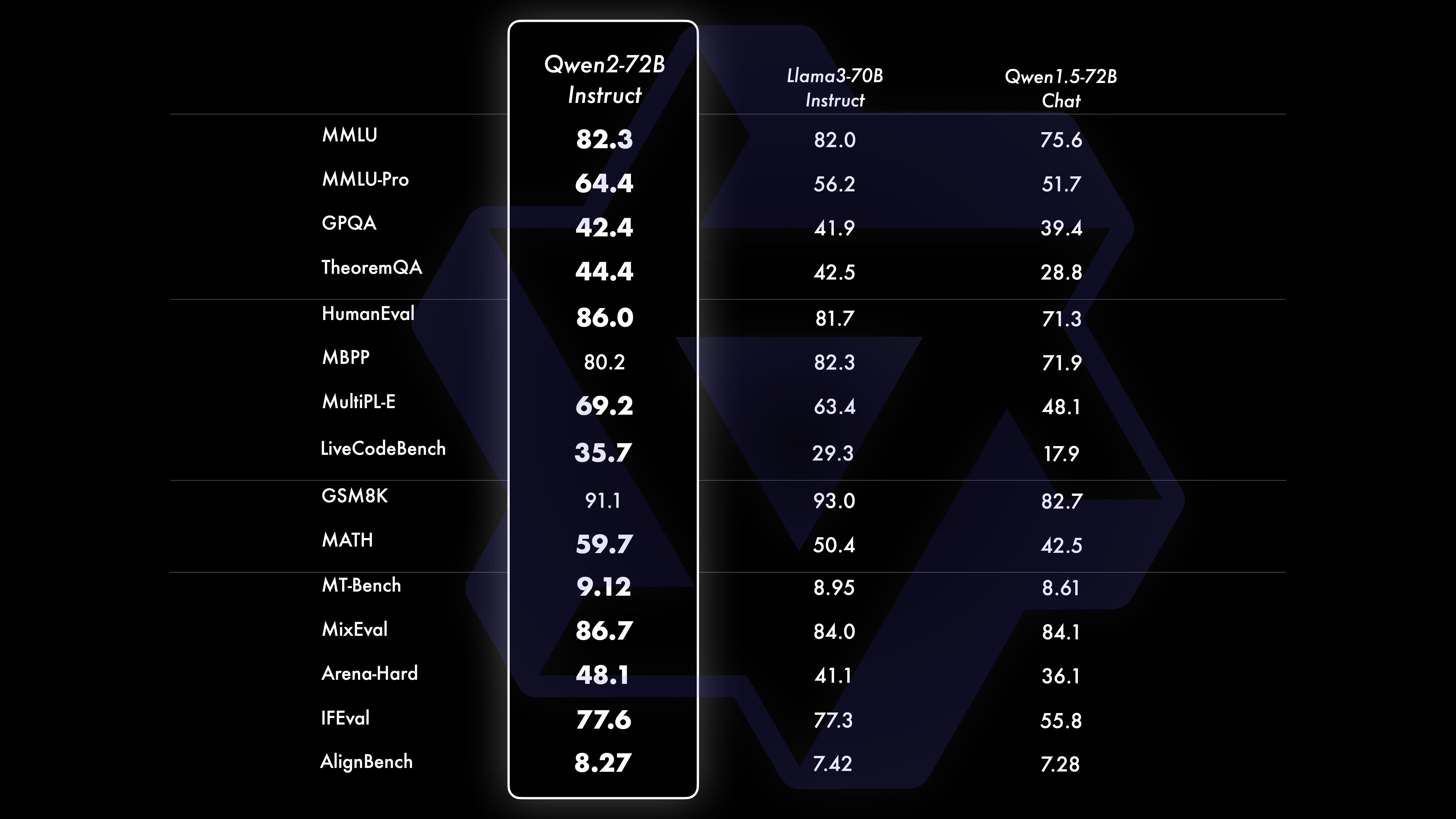
Conduzimos uma avaliação abrangente do Qwen2-72B-Instruct, abrangendo 16 benchmarks em vários campos. Qwen2-72B-Instruct encontra um equilíbrio entre obter melhores habilidades e ser consistente com os valores humanos. Especificamente, o Qwen2-72B-Instruct supera significativamente o Qwen1.5-72B-Chat em todos os benchmarks e também alcança desempenho competitivo em comparação com o Llama-3-70B-Instruct.
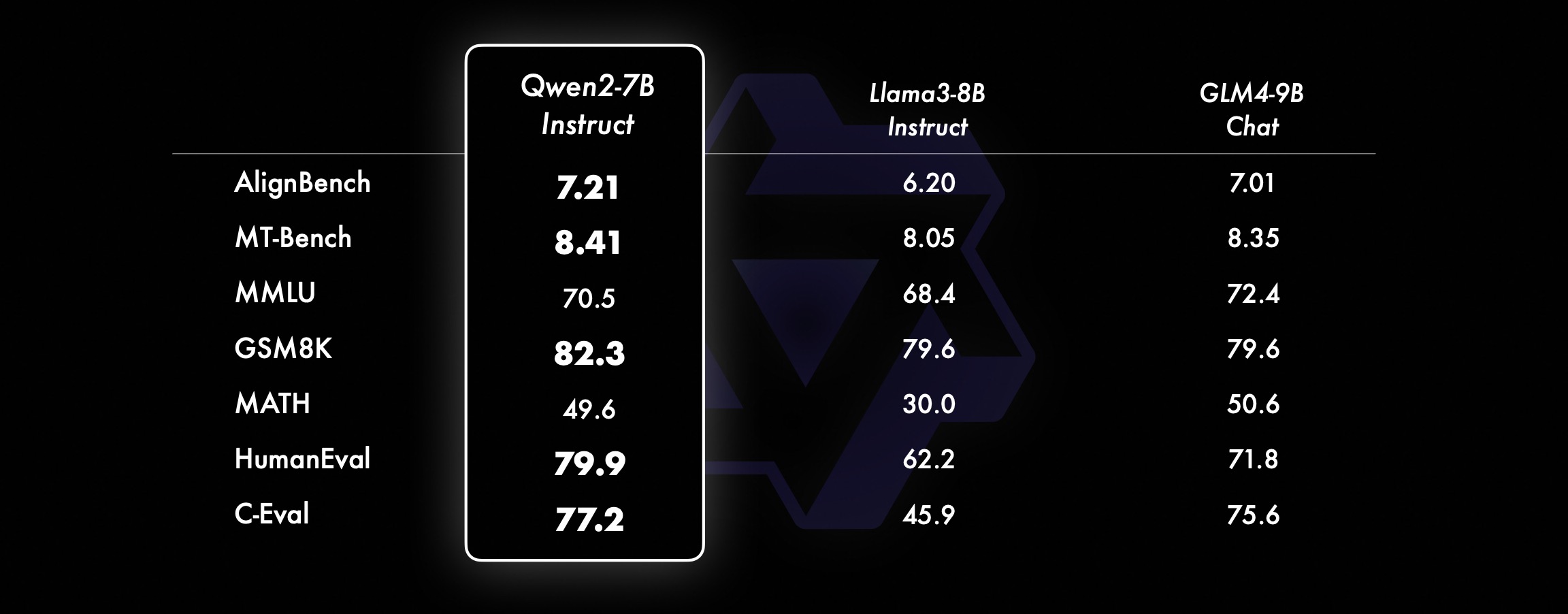
Em modelos menores, nossos modelos Qwen2 também superam modelos SOTA semelhantes e de tamanho ainda maior. Comparado com o modelo SOTA recém-lançado, o Qwen2-7B-Instruct ainda mostra vantagens em vários testes de benchmark, especialmente em codificação e indicadores relacionados à China.
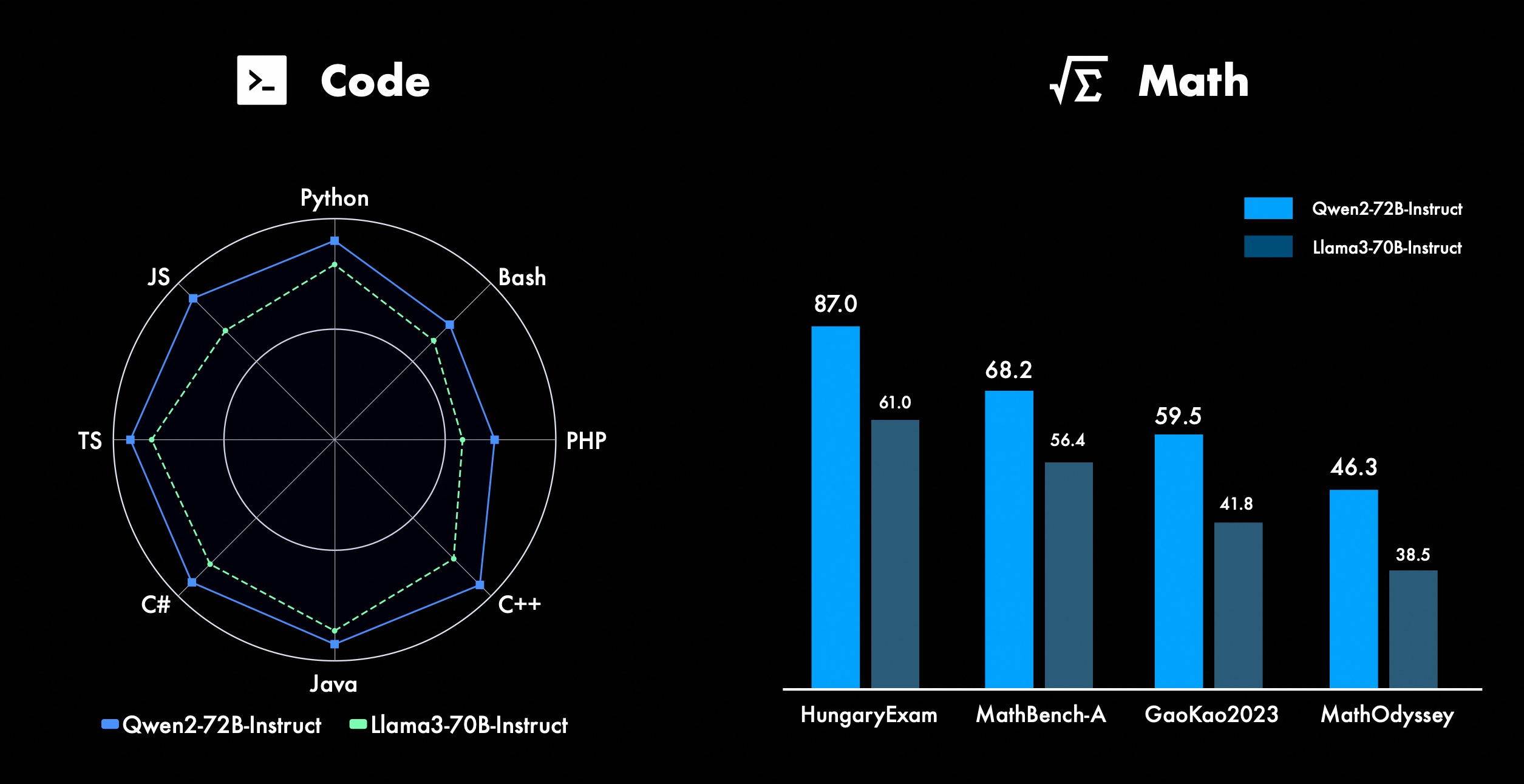
Estamos constantemente trabalhando para melhorar os recursos avançados do Qwen, especialmente em codificação e matemática. Em termos de codificação, integramos com sucesso a experiência de treinamento de código e os dados do CodeQwen1.5, resultando no Qwen2-72B-Instruct alcançando melhorias significativas em várias linguagens de programação. Em matemática, o Qwen2-72B-Instruct demonstra capacidades aprimoradas na resolução de problemas matemáticos, aproveitando um conjunto de dados extenso e de alta qualidade.
No Qwen2, todos os modelos de ajuste de instrução são treinados em contextos de comprimento de 32k e extrapolados para comprimentos de contexto mais longos usando técnicas como YARN ou Dual Chunk Attention.
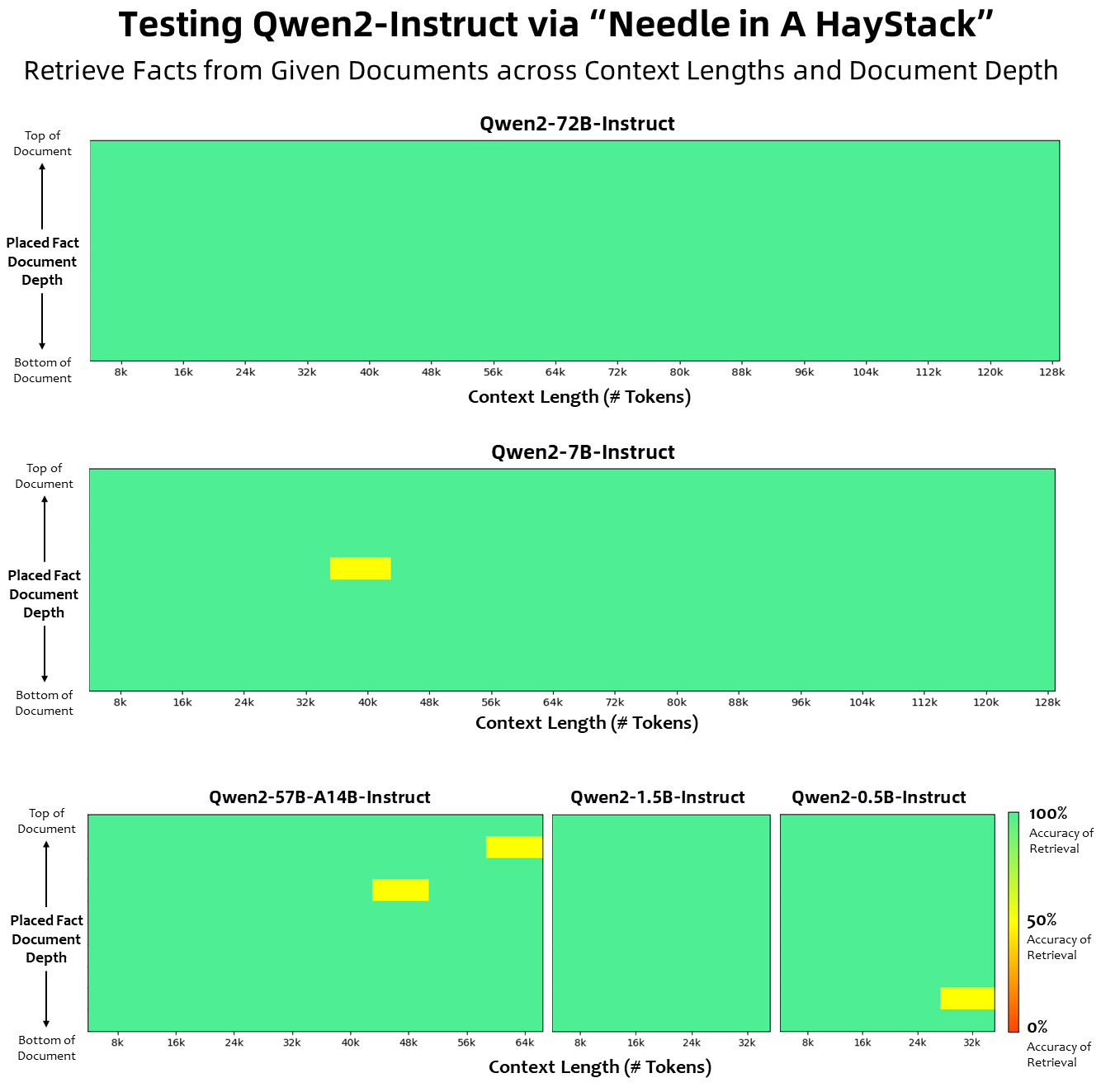
A imagem abaixo mostra os resultados do nosso teste em Needle in a Haystack. É importante notar que o Qwen2-72B-Instruct pode lidar perfeitamente com a tarefa de extração de informações no contexto de 128k. Nesse caso, torna-se a primeira escolha para processar tarefas de texto longo.
Além disso, vale destacar as capacidades impressionantes dos outros modelos da série: o Qwen2-7B-Instruct lida com contextos de até 128k quase perfeitamente, o Qwen2-57B-A14B-Instruct gerencia contextos de até 64k, e a série Os dois modelos menores suportam contextos de 32k.
Além do modelo de contexto longo, abrimos o código-fonte de uma solução de proxy para processamento eficiente de documentos contendo até 1 milhão de tags. Para obter mais detalhes, consulte nossa postagem de blog dedicada a este tópico.
A tabela abaixo mostra a proporção de respostas prejudiciais geradas por um grande modelo para quatro categorias de consultas multilíngues inseguras (atividade ilegal, fraude, pornografia, violência privada). Os dados de teste vêm do Jailbreak e são traduzidos em vários idiomas para avaliação. Descobrimos que o Llama-3 não lida com dicas multilíngues de forma eficiente e, portanto, não as incluiu na comparação. Através do teste de significância (P_value), descobrimos que o desempenho de segurança do modelo Qwen2-72B-Instruct é equivalente ao do GPT-4 e significativamente melhor que o modelo Mistral-8x22B.
Idioma Atividade ilegal Fraude Pornografia Privacidade Violência GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Chinês0%13%0 %0%17%0%43%47%53%0%10%0%Inglês0%7%0%0%23% 0%37%67%63%0%27%3%Contas a receber0%13%0% 0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%França0%3%0% 3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%ponto0%7%0%3% 7%3%47%57%47%4%26%4%日0%10%0%7%23%3%13%17%10%13%7%7%六0%4%0%4% 11%0%22%26%22%0%0%0%média0%8%0% 3%11%2%27%39%31%3%16%2% usam Qwen2 para desenvolvimentoAtualmente, todos os modelos foram lançados em Hugging Face e ModelScope. Você pode visitar o cartão do modelo para ver os métodos de uso detalhados e aprender mais sobre as características, desempenho e outras informações de cada modelo.
Por muito tempo, muitos amigos apoiaram o desenvolvimento do Qwen, incluindo ajuste fino (Axolotl, Llama-Factory, Firefly, Swift, XTuner), quantificação (AutoGPTQ, AutoAWQ, Compressor Neural), implantação (vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), plataforma API (Together, Fireworks, OpenRouter), execução local (MLX, Llama.cpp, Ollama, LM Studio), agente e estrutura RAG (LlamaIndex, CrewAI, OpenDevin), avaliação (LMSys, OpenCompass, Open LLM Leaderboard), treinamento de modelo (Dolphin, Openbuddy), etc. Sobre como usar Qwen2 com estruturas de terceiros, consulte a respectiva documentação, bem como nossa documentação oficial.

Existem muitas equipes e indivíduos que contribuíram para Qwen que não mencionamos. Agradecemos sinceramente o seu apoio e esperamos que a nossa colaboração promova a investigação e o desenvolvimento na comunidade de IA de código aberto.
licençaDesta vez, alteramos a permissão do modelo para uma diferente. Qwen2-72B e seu modelo de ajuste de instrução ainda usam a licença Qianwen original, enquanto todos os outros modelos, incluindo Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B e Qwen2-57B-A14B, mudaram para Apache2.0!Acreditamos que a maior abertura do nosso modelo à comunidade pode acelerar a aplicação e comercialização do Qwen2 em todo o mundo.
O que vem por aí para Qwen2?Estamos treinando um modelo Qwen2 maior para explorar ainda mais as extensões do modelo, bem como nossas extensões de dados recentes. Além disso, estendemos o modelo de linguagem Qwen2 para ser multimodal, capaz de compreender informações visuais e auditivas. Num futuro próximo, continuaremos a abrir novos modelos de código aberto para acelerar a IA de código aberto. Fique atento!
CitarEm breve divulgaremos um relatório técnico sobre o Qwen2. Citações são bem-vindas!
@article{qwen2, Apêndice Avaliação Básica do Modelo de LinguagemA avaliação de modelos básicos concentra-se principalmente no desempenho do modelo, como compreensão da linguagem natural, resposta a perguntas gerais, codificação, matemática, conhecimento científico, raciocínio e capacidades multilíngues.
Os conjuntos de dados avaliados incluem:
Tarefas de inglês: MMLU (5 vezes), MMLU-Pro (5 vezes), GPQA (5 vezes), Teorema QA (5 vezes), BBH (3 vezes), HellaSwag (10 vezes), Winogrande (5 vezes), TruthfulQA ( 0 vezes), ARC-C (25 vezes)
Tarefas de codificação: EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
Tarefas de matemática: GSM8K (4 vezes), MATEMÁTICA (4 vezes)
Tarefas chinesas: C-Eval (5 tiros), CMMLU (5 tiros)
Tarefas multilíngues: vários exames (M3Exam 5 vezes, IndoMMLU 3 vezes, ruMMLU 5 vezes, mmMLU 5 vezes), vários entendimentos (BELEBELE 5 vezes, XCOPA 5 vezes, XWinograd 5 vezes, XStoryCloze 0 vezes, PAWS-X 5 vezes) , matemática múltipla (MGSM 8 vezes), traduções múltiplas (Flores-1015 vezes)
Conjunto de dados de desempenho Qwen2-72B DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArchitectureMinistério da EducaçãoDenseDenseDenseDense#Parâmetros ativados 21B39B70B72B110B72B#Parâmetros 236B140B70B72B1 10B72B Inglês Mohrman ·Lu 78.577.879.577.580.484.2MMLU-Professional Edition-49.552. 845.849.455.6Garantia de qualidade-34.336.336.335.937.9Teorema Perguntas e respostas-35.932.329.334.943.1Baibihei 78.978.981.065.574.88 2.4 Shiraswag 87.888.788.086. 7.6 Janelas grandes 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668,9 Perguntas e respostas honestas 42.251.045.659.649.654.8 Avaliação de recursos humanos de codificação 45.746.348.246.354.364.6 Departamento de serviço público da Malásia 73 .971.770.466.970.976.9 Avaliação 55.054.154.852.957.765.4 Vários 44.446.746.341.852.759.6 Matemática GSM8K79. 283.783.079.585.489.5 Matemática 43.641.742.534.149.651.1 Chinês C-Assessment 81.754.665.1 Vários idiomas e vários exames 6 7.563.570.066.475.676.6Múltiplos entendimentos 77.077.779.978.278.280.7Múltipla matemática 58.862.967.161.764.476.0Múltiplas traduções 36.023.338.035.636.2 37.8Qwen2-57B-A14B Conjunto de dados Jabba Mixtral-8x7B Instrument-1.5-34BQwen1.5-32B Qwen2-57B-A14B Arquitetura MoE MoE Denso Denso MoE #Parâmetros ativados 12B12B34B32B14B #Parâmetros 52B47B34B32B57B Inglês Moleman Lu 67.471.877.174.376.5MMLU - Professional Edition - 41.048.344.043.0 Garantia de qualidade - 29.2 - 30.834.3 Teorema Q&A - 2 - 28.833.5 Baibei Preto 45.450.376.466.867.0 Shiela Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 Perguntas e respostas honestas 46.451.153.957.457.7 Codificação de avaliação de mão de obra 29.337.246.343.35 3.0 Serviço Público Malásia - 63.965.564.271.9 Avaliação - 46.451 .950.457.2 Vários - 39.03 9.538.549 .8 Matemática GSM8K59.962.582.776.880.7 Matemática-30.841.736.143.0 Chinês C-Avaliação --- 83.587.7 Universidade de Montreal, Canadá -- 84.882.388.5 Vários idiomas e vários exames-56.158.361.665.5 Compreensão multipartidária -70.773.976.577.0Matemática Múltipla -45.049.356.162.3Tradução Múltipla -29.830.033.534.5Qwen2-7B Conjunto de dados Mistral -7B Jemma -7B Camelo -3-8BQwen1.5 -7BQwen2-7B # Parâmetros 7,2B850 milhões 8,0B7.7B7.6B # Parâmetros não incorporados 7,0B780 milhões 7,0B650 milhões 650 milhões Inglês Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 Garantia de qualidade 24,72 5.725.826. 731.8 Perguntas e respostas sobre o teorema 19.221.522.114.231.1 Baibei Black 56.155.157.740.262.6 Shiraswager 83.282.282.178.580.7 Winogrand 78.479.077.471.377.0ARC-C60.061.159 . 354.260.6 Perguntas e respostas honestas 42.244 .844.051.154.2 Avaliação de recursos humanos de codificação 29.337.233.536 .051.2 Serviço Público Malásia 51.150.653.951.665.9 Avaliação 36.439.640.340.054.2 Múltipla 29.429.722.628.146.3 Matemática GSM8K52.246.456.0 62.579.9 Matemática 13.124.320.520. 344.2 Avaliação C Humana da China 47.443.649.574.183.2 Universidade de Montreal , Canadá - 50.873.183.9 Exame Múltiplo Multilíngue 47.142.752.347.759.2 Compreensão Múltipla 63.358.368.667.672.0 Matemática Multivariada 26.339.136.337.357.5 Tradução Múltipla 23.331.231 .928.431.5Qwen2 - Conjunto de dados 0,5B e Qwen2-1,5B Phi-2Gemma -2B CPM mínimo Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B # Parâmetros não Emb 250 milhões 2.0B2.4B1.3B035 milhões 1,3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 Teorema Perguntas e respostas ---- 8.915.0 Avaliação de mão de obra 47.622.050.020.122.031.1 Departamento de serviço público da Malásia 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 Matemática 3.511.810.210.110.72 1.7 Baibi Preto 43.435.236.924.228.437. 2 Shiela Swag 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 Perguntas e respostas honestas 44.533.1-39.439.745.9C - Avaliação 23.428.051 .159.758.270.6 Universidade de Montreal, Canadá 24.2 - 51.157.855.170.3 Avaliação do modelo de ajuste de instrução Qwen2-72B - Conjunto de dados guiado Camelo - 3-70B - Orientação Qwen1.5-72B - Chat Qwen2-72B - Orientação Inglês Mohr Man Lu 82.075.682.3MMLU - Professional Edition 56.251. 82 .371.980.2 Avaliação múltipla 63.448.169.2 75.266.979.0 Teste de código ao vivo 29.317.935.7 Matemática GSM 8K93.082.7 91. 1 Matemática 50.442.559.7 Avaliação C chinesa 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Instruction DatasetMixtral -8x7B-Instruir-v0.1Yi-1.5 -34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - Arquitetura de Orientação Ministério da Educação Densa Densa Ministério da Educação # Parâmetro ativado 12B34B32B14B # Parâmetro 47B34B32B57B Inglês Mohr Man Lu 71.476.874.875.4MMLU - Professional Edition 43.352.346.452.8 Qualidade Garantia - 30.834.3 Perguntas e respostas do teorema - -30.933.1MT-Bench8.308.508.308.55 Avaliação de recursos humanos de codificação 45.175.268.379.9 Serviço público Malásia 59.574.667.970.9 Vários --50.766.4 Avaliação 48.5-63.671.6 Ao vivo Teste de código 12.3-15.225.5 Matemática GSM8K65.790.283.679.6 Matemática 30.750.142.449.1 Chinês C-Avaliação - 76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide Conjunto de dados Camel-3-8B-Guide Yi-1.5-9 B -Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide Inglês Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 Garantia de qualidade 34.2--27.825.3 Teorema Q&A 23.0- -14.125 .3MT-Bench8.058.208.357.608.41 Codificação Humanitária 62.266.571.846.379.9 Serviço Público Malásia 67,9--48.967.2 Múltiplo 48,5--27.259.1 Avaliação 60,9--44.870.3 Teste de código ao vivo 17.3-- 26. 6 Matemática GSM8K79.684.879.660.382.3 Matemática 30.047.750.623.249.6 Avaliação C chinesa 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct e Qwen2-1.5B-Instruct Conjunto de dados Qwen1.5- 0.5B-Chat Qwen2-0.5B-Guide Qwen1.5-1.8B-Chat Qwen2-1.5B-Guide Morman Lu35.037.943.752.4 Avaliação de mão de obra 9.117.125.037.8GSM8K11.340.135.361.6C-Avaliação 37.245.255.363 .8IFEval ( solicitar acesso estrito) O comando 14.620.016.829.0 ajusta os recursos multilíngues do modeloComparamos o modelo de ajuste de instrução Qwen2 com outros LLMs recentes em vários benchmarks abertos entre idiomas, bem como na avaliação humana. Para a linha de base, apresentamos resultados em 2 conjuntos de dados de avaliação:
M-MMLU da Okapi: avaliação de conhecimentos gerais multilíngues (usamos subconjuntos de ar, de, es, fr, it, nl, ru, uk, vi, zh para avaliação) MGSM: para avaliações de alemão, inglês, espanhol, francês, matemática em Idiomas japonês, russo, tailandês, chinês e brasileiroOs resultados são calculados em média entre os idiomas para cada benchmark e são os seguintes:
M-MMLU exemplar (5 tiros) MGSM (0 tiros, CoT) LLM proprietário GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 comando LL.M de código aberto-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -Guia 60.057.0Qwen2-57B-A14B-Guia 68.074.0Qwen2-72B-Guia 78.086.6Para avaliação manual, comparamos Qwen2-72B-Instruct com GPT3.5, GPT4 e Claude-3-Opus usando um conjunto de avaliação interno, que inclui 10 idiomas ar, es, fr, ko, th, vi, pt, id, ja e ru (pontuação de 1 a 5):
Modelo Contas a Receber Espanhol Francês Corri Seis Pontos ID Jiaru Média Claude-3-Works-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 93. 724.324.09 GPT-4-Turbo- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-Guia 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 53.923 .943.873.833.953.553.773.063.633.71GPT-3.5-Turbo-11062.524. 073.472.373.382.903.373.562.753.243.16Agrupados por tipo de tarefa, os resultados são os seguintes:
Conhecimento do modelo Compreensão da criação de matemática Claude-3-Works-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-Guide3.414.074.363.61GPT- 4-06133.424.094.103. 32GPT-3.5-Turbo-11063.373.673.892.97Esses resultados demonstram os poderosos recursos multilíngues do modelo de ajuste de instruções Qwen2.
Os modelos da série Qwen2 de código aberto do Alibaba melhoraram significativamente o desempenho e os recursos multilíngues, fazendo uma contribuição importante para a comunidade de IA de código aberto. No futuro, Qwen2 continuará a desenvolver e expandir ainda mais a escala do modelo e as capacidades multimodais, o que vale a pena esperar.