ai toolkit
1.0.0
Это мой репозиторий исследований. Я провожу в нем много экспериментов и не исключено, что что-нибудь сломаю. Если что-то сломалось, проверьте более ранний коммит. Этот репозиторий может обучать многим вещам, и за ними сложно уследить.
Моя работа над этим проектом была бы невозможна без потрясающей поддержки Глифа и всех членов команды. Если вы хотите поддержать меня, поддержите Глифа. Присоединяйтесь к сайту, присоединяйтесь к нам в Discord, подписывайтесь на нас в Твиттере и делайте вместе с нами что-нибудь классное.
Требования:
Линукс:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv venv
source venv/bin/activate
# .venvScriptsactivate on windows
# install torch first
pip3 install torch
pip3 install -r requirements.txtОкна:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
. v env S cripts a ctivate
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txtЧтобы быстро начать работу, ознакомьтесь с руководством @araminta_k по точной настройке Flux Dev на 3090 с 24 ГБ видеопамяти.
В настоящее время для обучения FLUX.1 вам необходим графический процессор с объемом видеопамяти не менее 24 ГБ . Если вы используете его в качестве графического процессора для управления мониторами, вам, вероятно, потребуется установить флаг low_vram: true в файле конфигурации в разделе model: Это приведет к квантованию модели на ЦП и позволит ей обучаться с подключенными мониторами. Пользователи заставили его работать в Windows с WSL, но есть сообщения об ошибке при работе в Windows. Я пока тестировал только на Linux. Это все еще очень экспериментальный вариант, и пришлось прибегнуть к множеству квантований и трюков, чтобы вообще уместить его на 24 ГБ.
FLUX.1-dev имеет некоммерческую лицензию. Это означает, что все, что вы обучаете, унаследует некоммерческую лицензию. Это также закрытая модель, поэтому перед ее использованием необходимо принять лицензию на ВЧ. В противном случае это не удастся. Ниже приведены необходимые шаги для установки лицензии.
.env в корне этой папки..env например: HF_TOKEN=your_key_hereFLUX.1-schnell — это Apache 2.0. Все, что на нем обучено, может быть лицензировано по вашему желанию, и для обучения не требуется HF_TOKEN. Однако для обучения с ним требуется специальный адаптер: ostris/FLUX.1-schnell-training-adapter. Это также очень экспериментальный вариант. Для достижения наилучшего общего качества рекомендуется пройти обучение на FLUX.1-dev.
Чтобы использовать его, вам просто нужно добавить помощника в раздел model вашего файла конфигурации следующим образом:
model :
name_or_path : " black-forest-labs/FLUX.1-schnell "
assistant_lora_path : " ostris/FLUX.1-schnell-training-adapter "
is_flux : true
quantize : trueВам также необходимо скорректировать шаги выборки, поскольку Шнеллю не требуется так много шагов.
sample :
guidance_scale : 1 # schnell does not do guidance
sample_steps : 4 # 1 - 4 works wellconfig/examples/train_lora_flux_24gb.yaml ( config/examples/train_lora_flux_schnell_24gb.yaml для schnell) в папку config и переименуйте его whatever_you_want.ymlpython run.py config/whatever_you_want.ymlПри запуске будет создана папка с именем и папка обучения из конфигурационного файла. В нем будут все контрольные точки и изображения. Вы можете остановить обучение в любой момент, нажав Ctrl+C, и когда вы возобновите его, оно возобновится с последней контрольной точки.
ВАЖНЫЙ. Если вы нажмете Ctrl+C во время сохранения, это, скорее всего, повредит эту контрольную точку. Так что подождите, пока это не будет сделано, сохраняя
Пожалуйста, не открывайте отчет об ошибке, если это не ошибка в коде. Вы можете присоединиться к моему Discord и попросить помощи там. Однако, пожалуйста, воздержитесь от отправки мне в личку вопросов общего характера или поддержки. Спрашивайте в дискорде и я отвечу, когда смогу.
Чтобы начать локальное обучение с помощью специального пользовательского интерфейса, выполните описанные выше действия и установите ai-toolkit :
cd ai-toolkit # in case you are not yet in the ai-toolkit folder
huggingface-cli login # provide a `write` token to publish your LoRA at the end
python flux_train_ui.py Вы создадите экземпляр пользовательского интерфейса, который позволит вам загружать изображения, подписывать их, обучать и публиковать LoRA. 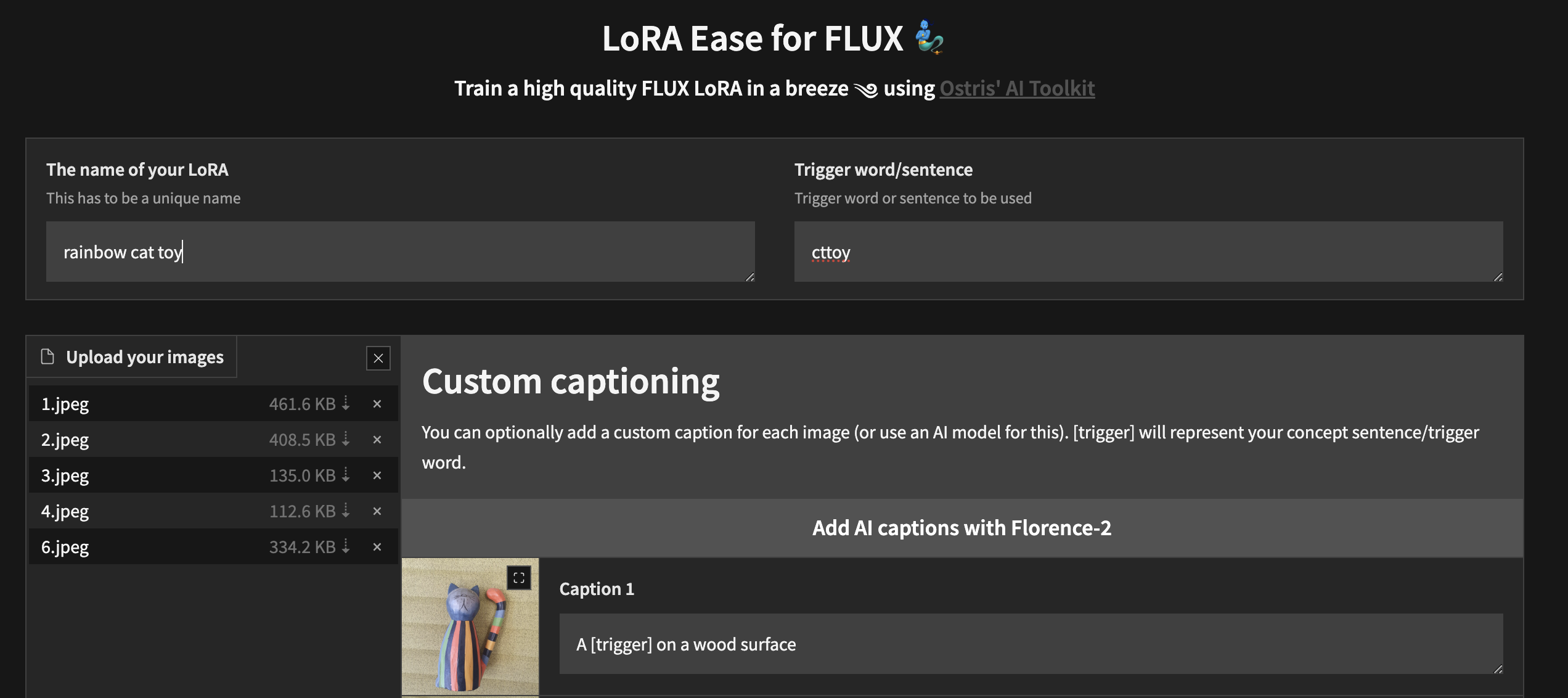
Пример шаблона RunPod: runpod/pytorch:2.2.0-py3.10-cuda12.1.1-devel-ubuntu22.04
Вам нужно минимум 24 ГБ видеопамяти, выберите графический процессор по своему вкусу.
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
dataset или как вам угодно.huggingface-cli login и вставьте свой токен.config/examples в папку config и переименуйте его whatever_you_want.yml .folder_path: "/path/to/images/folder" на путь к вашему набору данных, например, folder_path: "/workspace/ai-toolkit/your-dataset" .python run.py config/whatever_you_want.yml .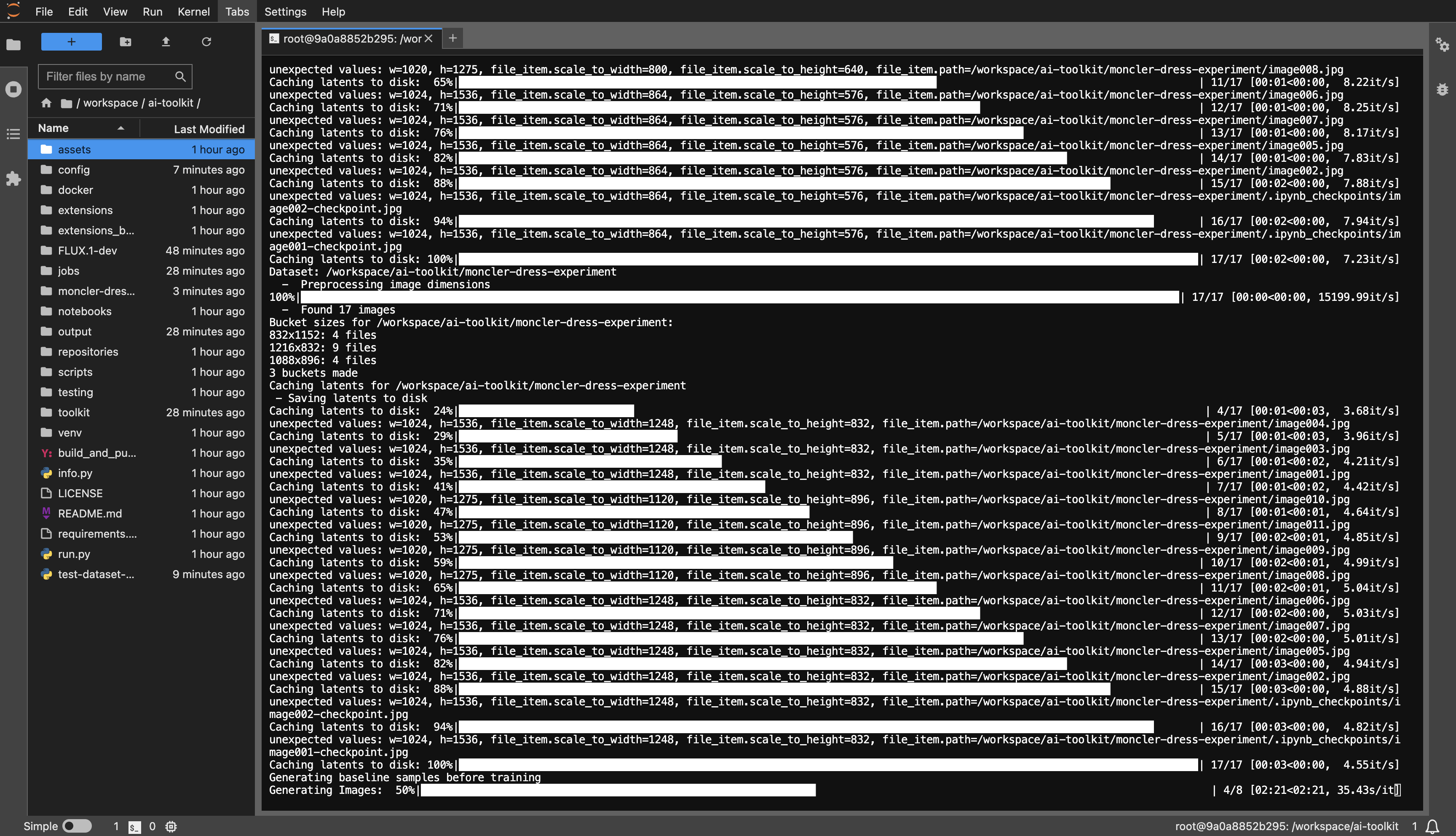
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
pip install modal , чтобы установить модальный пакет Python.modal setup для аутентификации (если это не сработает, попробуйте python -m modal setup ). huggingface-cli login и вставьте свой токен.ai-toolkit .config/examples/modal , в папку config и переименуйте его whatever_you_want.yml ./root/ai-toolkit . Установите весь локальный путь ai-toolkit по адресу code_mount = modal.Mount.from_local_dir например:
code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit")
Выберите GPU и Timeout в @app.function (по умолчанию — A100 40 ГБ и тайм-аут 2 часа) .
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml .Storage > flux-lora-models .modal volume ls flux-lora-models .modal volume get flux-lora-models your-model-name .modal volume get flux-lora-models my_first_flux_lora_v1 .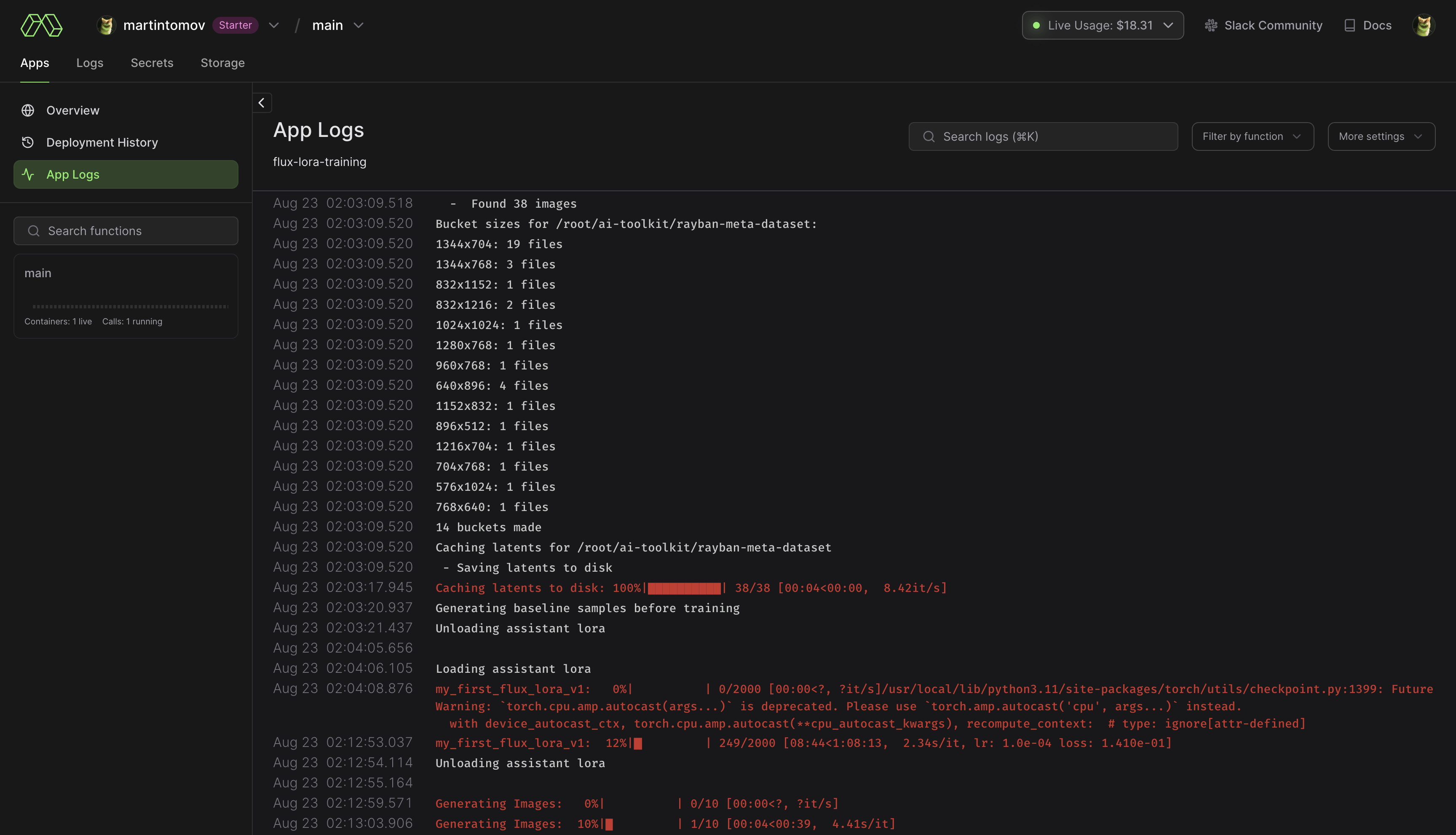
Наборы данных обычно должны представлять собой папку, содержащую изображения и связанные с ними текстовые файлы. В настоящее время поддерживаются только форматы jpg, jpeg и png. У Webp в настоящее время есть проблемы. Текстовые файлы должны называться так же, как изображения, но с расширением .txt . Например, image2.jpg и image2.txt . Текстовый файл должен содержать только заголовок. Вы можете добавить слово [trigger] в файл подписи, и если у вас есть trigger_word в вашей конфигурации, оно будет автоматически заменено.
Изображения никогда не масштабируются, а уменьшаются и помещаются в сегменты для пакетной обработки. Вам не нужно обрезать/изменять размер изображений . Загрузчик автоматически изменит их размер и может обрабатывать различные соотношения сторон.
Для обучения определенных слоев с помощью LoRA вы можете использовать сетевые kwargs only_if_contains . Например, если вы хотите обучить только два слоя, используемые «Последним Беном», упомянутыми в этом посте, вы можете настроить свои сетевые кварги следующим образом:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks.7.proj_out "
- " transformer.single_transformer_blocks.20.proj_out " Соглашения об именах слоев указаны в формате диффузоров, поэтому проверка состояния модели покажет суффикс имени слоев, которые вы хотите обучить. Вы также можете использовать этот метод для тренировки только определенных групп весов. Например, чтобы обучить single_transformer только для FLUX.1, вы можете использовать следующее:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks. " Вы также можете исключить слои по их именам, используя ignore_if_contains network kwarg. Итак, чтобы исключить все отдельные трансформаторные блоки,
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
ignore_if_contains :
- " transformer.single_transformer_blocks. " ignore_if_contains имеет приоритет над only_if_contains . Поэтому, если вес покрывается обоими, if будет игнорироваться.
Возможно, это все еще работает, но я давно это не проверял.
Генератор изображений, который может брать точки из файла конфигурации или формировать текстовый файл и генерировать их в папку. В основном мне это нужно было для теста SDXL, который я провожу, но я добавил к нему немного доработки, чтобы его можно было использовать для генерации пакетного изображения. Все это запускается из файла конфигурации, пример которого вы можете найти в config/examples/generate.example.yaml . Вся информация в комментариях к примеру.
Он основан на экстракторе инструмента LyCORIS, но с добавлением некоторых функций QOL и поддержки LoRA (lierla). Он может выполнять несколько типов экстракции за один проход. Все это запускается из файла конфигурации, пример которого вы можете найти в config/examples/extract.example.yml . Просто скопируйте этот файл в папку config и переименуйте его whatever_you_want.yml . Затем вы можете отредактировать файл по своему вкусу. и назовите это так:
python3 run.py config/whatever_you_want.ymlВы также можете указать полный путь к файлу конфигурации, если хотите сохранить его где-то еще.
python3 run.py " /home/user/whatever_you_want.yml "Дополнительные примечания о том, как это работает, доступны в самом примере файла конфигурации. LoRA и LoCON поддерживают извлечение «фиксированных», «пороговых», «отношений», «квантилей». Я расскажу, что они делают и означают позже. Большинство людей использовали фиксированный размер, который является традиционным извлечением фиксированных размеров.
process — это массив различных процессов, которые нужно запустить. Вы можете добавить несколько и комбинировать. Один LoRA, один LyCON и т. д.
Измените <lora:my_lora:4.6> на <lora:my_lora:1.0> или что угодно с тем же эффектом. Инструмент для изменения масштаба весов LoRA. Должно быть и с LoCON, но я не проверял. Все это запускается из файла конфигурации, пример которого вы можете найти в config/examples/mod_lora_scale.yml . Просто скопируйте этот файл в папку config и переименуйте его whatever_you_want.yml . Затем вы можете отредактировать файл по своему вкусу. и назовите это так:
python3 run.py config/whatever_you_want.ymlВы также можете указать полный путь к файлу конфигурации, если хотите сохранить его где-то еще.
python3 run.py " /home/user/whatever_you_want.yml "Дополнительные примечания о том, как это работает, доступны в самом примере файла конфигурации. Это полезно при создании всех LoRA, поскольку идеальный вес редко равен 1,0, но теперь вы можете это исправить. Что касается ползунков, они могут иметь странные шкалы от -2 до 2 или даже от -15 до 15. Это позволит вам увеличить их, чтобы все они имели желаемый масштаб.
Именно так я тренирую большинство последних слайдеров, которые у меня есть на Civitai, вы можете проверить их в моем профиле Civitai. Он основан на работе p1atdev/LECO и rohitgandikota/erasing, но был сильно модифицирован для создания ползунков, а не для удаления концепций. У меня еще много планов на этот счет, но он и так очень функционален. Он также очень прост в использовании. Просто скопируйте пример файла конфигурации в config/examples/train_slider.example.yml в папку config и переименуйте его whatever_you_want.yml . Затем вы можете отредактировать файл по своему вкусу. и назовите это так:
python3 run.py config/whatever_you_want.ymlВ этом примере файла содержится гораздо больше информации. Вы даже можете запустить пример как есть, без каких-либо изменений, чтобы увидеть, как он работает. Он создаст ползунок, который превратит всех животных в собак (отрицательный) или кошек (поз.). Просто запустите его так:
python3 run.py config/examples/train_slider.example.ymlИ вы сможете увидеть, как это работает, ничего не настраивая. Для этого метода не требуются наборы данных. Скоро я опубликую лучший урок.
Теперь вы можете создавать собственные расширения и делиться ими. Они работают в рамках этой структуры и имеют все доступные встроенные инструменты. Я, вероятно, буду использовать это в качестве основного метода разработки в будущем, поэтому я не буду добавлять и добавлять все больше и больше функций в этот базовый репозиторий. Вероятно, я также перенесу большую часть существующего функционала, чтобы сделать все модульным. В папке extensions есть пример расширения, показывающий, как создать расширение для слияния моделей. Весь код тщательно документирован, и, надеюсь, этого будет достаточно, чтобы вы могли начать работу. Чтобы создать расширение, просто скопируйте этот пример и замените все, что вам нужно.
Он находится в папке extensions . Это полностью функциональное объединение моделей, которое позволяет объединить столько моделей, сколько вы захотите. Это хороший пример того, как сделать расширение, но это также и довольно полезная функция, поскольку большинство слияний могут выполнять только одну модель за раз, а для этой потребуется столько, сколько вы захотите. Там есть пример файла конфигурации, просто скопируйте его в папку config и переименуйте его whatever_you_want.yml . и используйте его как любой другой файл конфигурации.
Это работает, но не готово для использования другими и поэтому не имеет примера конфигурации. Я все еще работаю над этим. Я обновлю это, когда оно будет готово. Я добавляю множество функций для критериев, которые использовал в своей работе по увеличению изображений. Критик (дискриминатор), потеря контента, потеря стиля и еще несколько. Если вы не знаете, VAE для стабильной диффузии (да, даже MSE и SDXL) ужасны для меньших лиц и сдерживают SD. Я исправлю это. Я напишу об этом подробнее с более подробными примерами позже, а вот быстрый тест работы с различными VAE. Просто вошел и вышел. На меньших лицах ситуация намного хуже, чем показано здесь.
extensions . Подробнее об этом читайте выше.Еще один большой рефакторинг, призванный сделать SD более модульным.
Сделал скрипт пакетной генерации изображений
Основные изменения и обновления. Новый инструмент масштабирования LoRA, подробности см. выше. Добавлены улучшенные метаданные, чтобы Автоматический1111 знал, что такое базовая модель. Добавлено несколько экспериментов и масса обновлений. На данный момент эта штука все еще нестабильна, так что, надеюсь, серьезных изменений не произойдет.
К сожалению, мне лень писать полный список изменений со всеми изменениями.
Я добавил обучение SDXL к ползункам... но... оно не работает должным образом. Обучение ползунку основано на способности модели понимать, что безусловное (отрицательное приглашение) означает, что вы не хотите, чтобы эта концепция присутствовала на выходе. SDXL по какой-то причине этого не понимает, что затрудняет разделение концепций внутри модели. Я уверен, что сообщество со временем найдет способ исправить это, но на данный момент это не будет работать должным образом. И если кто-нибудь из вас думает: «Можем ли мы исправить это, добавив в модель еще 1 или 2 текстовых кодировщика, а также еще несколько совершенно отдельных диффузионных сетей?» Нет. Боже, нет. Ему просто нужно немного потренироваться, не добавляя к нему каждую новую экспериментальную статью. Директор KISS.
Добавлены «якоря» в трейнер слайдера. Это позволяет вам установить подсказку, которая будет использоваться в качестве регуляризатора. Вы можете установить сетевой множитель, чтобы обеспечить согласованность распространения при больших весах.


