В сфере ИИ лауреат премии Тьюринга Ян Лекун является типичным исключением.
В то время как многие технические эксперты твердо уверены, что реализация AGI на нынешнем техническом пути является лишь вопросом времени, Янн Лекун неоднократно высказывал возражения.
В жарких дебатах со своими коллегами он не раз говорил, что нынешний путь основных технологий не может привести нас к AGI, и даже нынешний уровень ИИ не так хорош, как кошка.
Лауреат премии Тьюринга, главный ученый Meta по искусственному интеллекту, профессор Нью-Йоркского университета и т. д. Эти блестящие звания и огромный практический опыт не позволяют никому из нас игнорировать идеи этого эксперта по искусственному интеллекту.

Итак, что Янн ЛеКун думает о будущем искусственного интеллекта? В недавнем публичном выступлении он еще раз развил свою точку зрения: ИИ никогда не сможет достичь уровня интеллекта, близкого к человеческому, полагаясь исключительно на текстовое обучение.
Некоторые мнения заключаются в следующем:
1. В будущем люди, как правило, будут носить умные очки или другие типы интеллектуальных устройств. Эти устройства будут иметь встроенные системы-помощники для формирования личных интеллектуальных виртуальных команд для повышения личного творчества и эффективности.
2. Цель интеллектуальных систем — не заменить людей, а улучшить человеческий интеллект, чтобы люди могли работать более эффективно.
3. Даже домашняя кошка имеет в мозгу модель, более сложную, чем может построить любая система искусственного интеллекта.
4. FAIR по сути больше не фокусируется на языковых моделях, а движется к долгосрочной цели — созданию систем искусственного интеллекта следующего поколения.
5. Системы искусственного интеллекта не могут достичь уровня интеллекта, близкого к человеческому, обучаясь только на текстовых данных.
6. Янн Лекун предложил отказаться от генеративных моделей, вероятностных моделей, контрастного обучения и обучения с подкреплением и вместо этого принять архитектуру JEPA и модели, основанные на энергии, полагая, что эти методы с большей вероятностью будут способствовать развитию ИИ.
7. Хотя машины в конечном итоге превзойдут человеческий интеллект, ими можно будет управлять, поскольку они руководствуются целями.
Интересно, что перед началом выступления был эпизод.
Когда ведущий представил Лекуна, он назвал его главным ученым в области искусственного интеллекта Исследовательского института искусственного интеллекта Facebook (FAIR) .
В связи с этим ЛеКун перед выступлением уточнил, что буква «F» в слове FAIR больше не представляет Facebook, а означает « Фундаментальный ».
Исходный текст выступления, представленного ниже, был составлен APPSO и отредактирован. Наконец, прилагается исходная ссылка на видео: https://www.youtube.com/watch?v=4DsCtgtQlZU.
ИИ не понимает мир так хорошо, как ваша кошка
Хорошо, я собираюсь поговорить об ИИ человеческого уровня, о том, как мы этого достигнем и почему мы этого не добьемся.
Во-первых, нам действительно нужен ИИ человеческого уровня.
Потому что в будущем большинство из нас будут носить умные очки или другие типы устройств. Мы будем общаться с этими устройствами, и в этих системах будут помощники, может быть, не один, а может быть, целый набор помощников.
Это приведет к тому, что на каждого из нас будет работать интеллектуальная виртуальная команда.
Поэтому каждый станет «боссом», но эти «сотрудники» не являются настоящими людьми. Нам необходимо создавать подобные системы, в основном для того, чтобы расширить человеческий интеллект и сделать людей более творческими и эффективными.

Но для этого нам нужны машины, которые могут понимать мир, запоминать вещи, обладать интуицией и здравым смыслом, а также рассуждать и планировать на том же уровне, что и люди.
Хотя вы, возможно, слышали, как некоторые сторонники говорят, что нынешние системы ИИ не обладают такими возможностями. Поэтому нам нужно потратить время на то, чтобы научиться моделировать мир, иметь мысленные модели того, как мир устроен.
Практически у каждого животного есть такая модель. У вашей кошки должна быть более сложная модель, чем любая система искусственного интеллекта может построить или спроектировать.

Нам нужна система, обладающая постоянной памятью, которой нет у нынешних языковых моделей (LLM) , система, которая может планировать сложные последовательности действий, которые не могут выполнять современные системы, и система, которая является управляемой и безопасной.
Поэтому я предложу архитектуру под названием «целенаправленный ИИ». Около двух лет назад я написал концептуальный документ по этому поводу и опубликовал его. Многие сотрудники FAIR усердно работают над тем, чтобы этот план стал реальностью.
В прошлом FAIR работала над большим количеством прикладных проектов, но полтора года назад Meta создала продуктовое подразделение под названием Generative AI (Gen AI) , чтобы сосредоточиться на продуктах искусственного интеллекта.
Они занимаются прикладными исследованиями и разработками, поэтому теперь FAIR переориентирована на достижение долгосрочной цели — создание систем искусственного интеллекта следующего поколения. Мы практически больше не фокусируемся на языковых моделях.
Успех ИИ, включая большие языковые модели (LLM) , и особенно успех многих других систем за последние 5 или 6 лет, зависит от ряда методов, включая, конечно же, самообучение.

Суть самостоятельного обучения заключается в том, чтобы обучить систему не какой-то конкретной задаче, а попытаться правильно представить входные данные. Одним из способов достижения этой цели является восстановление после повреждений и восстановление.
Таким образом, вы можете взять кусок текста и испортить его, удалив некоторые слова или изменив другие слова. Этот процесс можно использовать для текста, последовательностей ДНК, белков или чего-либо еще, и даже в некоторой степени изображений. Затем вы тренируете огромную нейронную сеть, чтобы восстановить полную входную информацию, неповрежденную версию.
Это генеративная модель, поскольку она пытается восстановить исходный сигнал.
Итак, красный квадрат — это функция стоимости, верно? Он вычисляет расстояние между входом Y и восстановленным выходом y, и это параметр, который необходимо минимизировать в процессе обучения. В этом процессе система изучает внутреннее представление входных данных, которое можно использовать для различных последующих задач.
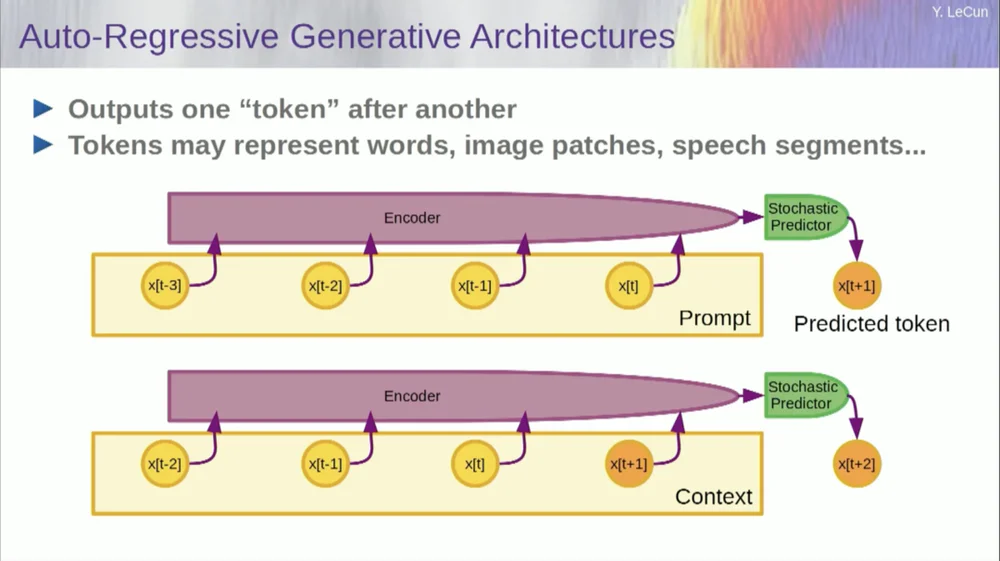
Конечно, это можно использовать для прогнозирования слов в тексте, что и делает авторегрессионное прогнозирование .
Языковые модели представляют собой особый случай, когда архитектура спроектирована таким образом, что при прогнозировании элемента, токена или слова она может смотреть только на другие токены слева от себя.
Он не может заглянуть в будущее. Если вы правильно обучите систему, покажете ей текст и попросите предсказать следующее слово или следующий токен в тексте, то вы сможете использовать систему для прогнозирования следующего слова. Затем вы добавляете следующее слово к входным данным, прогнозируете второе слово и добавляете его к входным данным, прогнозируете третье слово.
Это авторегрессионное предсказание .
Это то, чем занимаются студенты LLM, это не новая концепция, она существует со времен Шеннона , начиная с 50-х годов, то есть очень давно, но изменение в том, что теперь у нас есть эти массивные архитектуры нейронных сетей. Вы можете обучать на больших объемах данных и из них появятся новые функции.
Но этот вид авторегрессионного прогнозирования имеет некоторые серьезные ограничения, и здесь нет никаких реальных рассуждений в обычном смысле этого слова.
Еще одним ограничением является то, что это работает только для данных в форме дискретных объектов, символов, токенов, слов и т. д., то есть, по сути, для вещей, которые можно дискретизировать.
Нам все еще не хватает чего-то важного, когда дело доходит до достижения интеллекта человеческого уровня.
Я не обязательно говорю здесь об интеллекте человеческого уровня, но даже ваша кошка или собака могут совершать удивительные подвиги, которые недоступны современным системам искусственного интеллекта.

Любой 10-летний ребенок может научиться убирать со стола и наполнять посудомоечную машину за один присест, верно? Нет необходимости практиковаться или что-то в этом роде, верно?
Чтобы научиться водить машину, 17-летнему подростку требуется около 20 часов практики.
У нас до сих пор нет беспилотных автомобилей 5-го уровня, и уж точно нет домашних роботов, способных убирать со столов и наполнять посудомоечные машины.
ИИ никогда не достигнет интеллекта, близкого к человеческому уровню, обучаясь только на тексте
Итак, мы действительно упускаем что-то важное, что в противном случае мы могли бы делать эти вещи с помощью систем искусственного интеллекта.
Мы продолжаем сталкиваться с чем-то, называемым парадоксом Моравеца , который заключается в том, что вещи, которые кажутся нам тривиальными и даже не считаются разумными, на самом деле очень трудно сделать с помощью машин, и такие вещи, как манипуляция. Сложное абстрактное мышление высокого уровня, такое как язык, кажется очень просто для машин, и то же самое верно для таких вещей, как игра в шахматы и го.
Возможно, одна из причин в этом.
Модель большого языка (LLM) обычно обучается на 20 триллионах токенов.
Токен в среднем состоит из трех четвертей слова. Таким образом, всего слов 1,5 × 10 ^ 13. Каждый токен имеет размер около 3B, обычно для этого требуется 6×1013 байт.
Каждому из нас потребовалось бы около нескольких сотен тысяч лет, чтобы прочитать это, не так ли? По сути, это весь общедоступный текст в Интернете, вместе взятый.

Но подумайте о ребенке. Четырехлетний ребенок бодрствует в общей сложности 16 000 часов. В наш мозг входит 2 миллиона волокон зрительного нерва. Каждое нервное волокно передает данные со скоростью около 1Б в секунду, возможно, полбайта в секунду. По некоторым оценкам, это может составлять 3 миллиарда в секунду.
Это не важно, это все равно на порядок.
Этот объем данных составляет примерно 10 байт в 14-й степени, что почти того же порядка, что и LLM. Итак, за четыре года четырехлетний ребенок увидел столько же визуальных данных, сколько крупнейшие языковые модели, обученные на общедоступном тексте во всем Интернете.
Используя данные в качестве отправной точки, это говорит нам о нескольких вещах.
Во-первых, это говорит нам о том, что мы никогда не достигнем интеллекта, близкого к человеческому уровню, просто тренируясь на тексте. Этого просто не произойдет.
Во-вторых, зрительная информация очень избыточна. Каждое волокно зрительного нерва передает 1Б информации в секунду, что уже сжато 100 к 1 по сравнению с фоторецепторами в вашей сетчатке.
В нашей сетчатке имеется примерно от 60 до 100 миллионов фоторецепторов. Эти фоторецепторы сжимаются нейронами передней части сетчатки в 1 миллион нервных волокон. Так что уже компрессия 100 к 1. Затем к моменту, когда она достигает мозга, информация увеличивается примерно в 50 раз.
Итак, я измеряю сжатую информацию, но она все еще очень избыточна. А избыточность — это на самом деле то, что требуется для самостоятельного обучения. Самостоятельное обучение позволит узнать только полезные вещи из избыточных данных. Если данные сильно сжаты, что означает, что данные становятся случайным шумом, вы не сможете ничему научиться.
Вам нужна избыточность, чтобы чему-то научиться. Вам необходимо изучить основную структуру данных. Поэтому нам нужно научить систему изучать здравый смысл и физику, просматривая видео или живя в реальном мире.
Порядок моих слов может быть немного запутанным. В основном я хочу рассказать вам, что представляет собой эта целенаправленная архитектура искусственного интеллекта. Он сильно отличается от LLM или нейронов прямого распространения тем, что процесс вывода не просто проходит через ряд слоев нейронной сети, но фактически запускает алгоритм оптимизации.
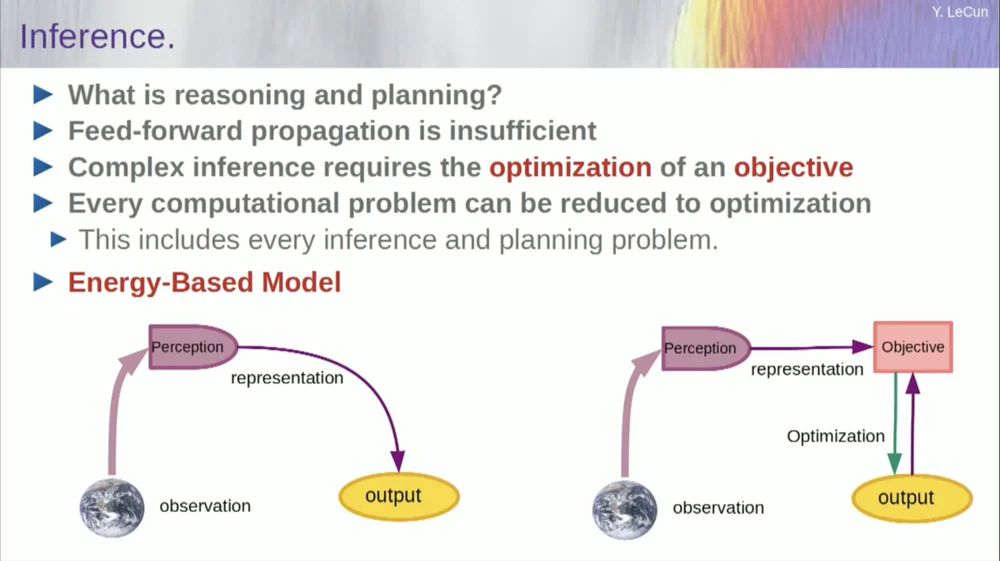
Концептуально это выглядит так.
Процесс прямой связи — это процесс, в котором наблюдения проходят через систему восприятия. Например, если у вас есть ряд слоев нейронной сети и вы создаете выходные данные, то для любого отдельного входного сигнала вы можете иметь только один выходной сигнал, но во многих случаях для восприятия может быть несколько возможных интерпретаций выходного сигнала. Вам нужен процесс сопоставления, который не просто вычисляет функциональность, но и обеспечивает несколько выходных данных для одного входного. Единственный способ добиться этого — использовать неявные функции.
По сути, красный прямоугольник в правой части этой структуры целей представляет собой функцию, которая в основном измеряет совместимость между входными данными и предлагаемыми выходными данными, а затем вычисляет выходные данные, находя выходное значение, которое наиболее совместимо с входными данными. Вы можете представить, что эта цель — это некая энергетическая функция, и вы минимизируете эту энергию, используя выход в качестве переменной.
У вас может быть несколько решений, и у вас может быть какой-то способ обработки этих множества решений. Это верно для системы восприятия человека. Если у вас есть несколько интерпретаций определенного восприятия, ваш мозг автоматически переключается между этими интерпретациями. Итак, есть некоторые доказательства того, что подобные вещи действительно случаются.
Но вернемся к архитектуре. Так что воспользуйтесь этим принципом рассуждения путем оптимизации. Вот предположения, если хотите, о том, как работает человеческий разум. Вы делаете наблюдения в мире. Система восприятия дает вам представление о текущем состоянии мира. Но, конечно, это лишь дает вам представление о том состоянии мира, которое вы можете воспринимать в данный момент.
Возможно, у вас остались какие-то запомнившиеся идеи о состоянии остального мира. Это можно объединить с содержимым памяти и ввести в модель мира.
Что такое модель? Модель мира — это мысленная модель того, как вы ведете себя в мире, поэтому вы можете представить последовательность действий, которые вы можете предпринять, и ваша модель мира позволит вам предсказать влияние этой последовательности действий на мир.
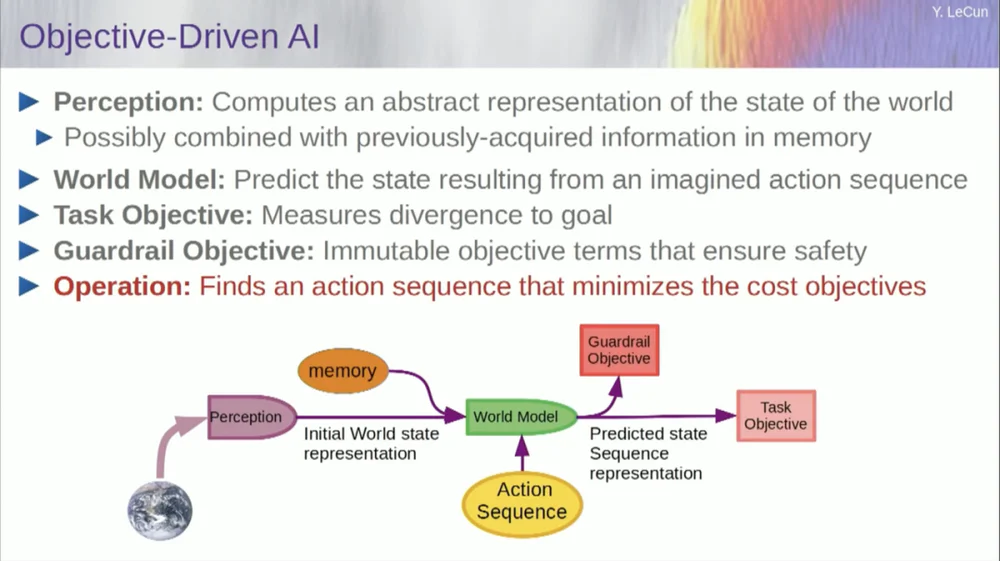
Таким образом, зеленый прямоугольник представляет собой модель мира, в которую вы вводите гипотетическую последовательность действий, предсказывающую, каким будет конечное состояние мира, или всю траекторию, которую вы прогнозируете, которая произойдет в мире.
Вы объединяете это с набором целевых функций. Одна из целей — измерить, насколько хорошо достигается цель, выполнена ли задача, и, возможно, набор других целей, которые служат запасами безопасности, в основном измеряя степень, в которой пройденная траектория или предпринятое действие не представляют опасности для робота. или люди вокруг машины и т. д. подождите.
Итак, теперь процесс рассуждения (об обучении я еще не говорил) — это просто рассуждение и состоит из поиска последовательностей действий, которые минимизируют эти цели, поиска последовательностей действий, которые минимизируют эти цели. Это процесс рассуждения.
Так что это не просто процесс прямой связи. Вы могли бы сделать это, ища отдельные варианты, но это неэффективно. Лучший подход — убедиться, что все эти блоки дифференцируемы, вы можете провести обратное распространение градиента через них, а затем обновить последовательность действий с помощью градиентного спуска.

Эта идея на самом деле не нова и существует уже более 60 лет, а может быть, и дольше. Во-первых, позвольте мне поговорить о преимуществах использования модели мира для такого рода рассуждений. Преимущество в том, что вы можете выполнять новые задачи, не требуя никакого обучения.
Мы делаем это время от времени. Когда мы сталкиваемся с новой ситуацией, мы думаем о ней, представляем себе последствия наших действий, а затем предпринимаем последовательность действий, которая приведет к достижению нашей цели (какой бы она ни была) . Нам не нужно учиться выполнять эту задачу. , мы можем планировать. Так что это в основном планирование.
Большинство рассуждений можно свести к оптимизации. Следовательно, процесс вывода посредством оптимизации по своей сути более эффективен, чем просто прохождение нескольких слоев нейронной сети. Как я уже сказал, идея рассуждения посредством оптимизации существует уже более 60 лет.
В области теории оптимального управления это называется управлением с прогнозированием модели.
У вас есть модель системы, которой вы хотите управлять, например ракета, самолет или робот. Вы можете представить себе, как используете свою модель мира для расчета эффектов серии команд управления.
Затем вы оптимизируете эту последовательность, чтобы движение достигло желаемых результатов. Все планирование движений в классической робототехнике осуществляется таким образом, и в этом нет ничего нового. Новизна здесь в том, что мы изучим модель мира, а система восприятия извлечет подходящее абстрактное представление.
Теперь, прежде чем я перейду к примеру запуска этой системы, вы можете построить общую систему ИИ со всеми этими компонентами: моделью мира, функцией стоимости, которую можно настроить для поставленной задачи, модулем оптимизации (т. е. по-настоящему оптимизирующая, нахождение заданного модуля, определяющего оптимальную последовательность действий для модели мира) , кратковременной памяти, системы восприятия и т. д.
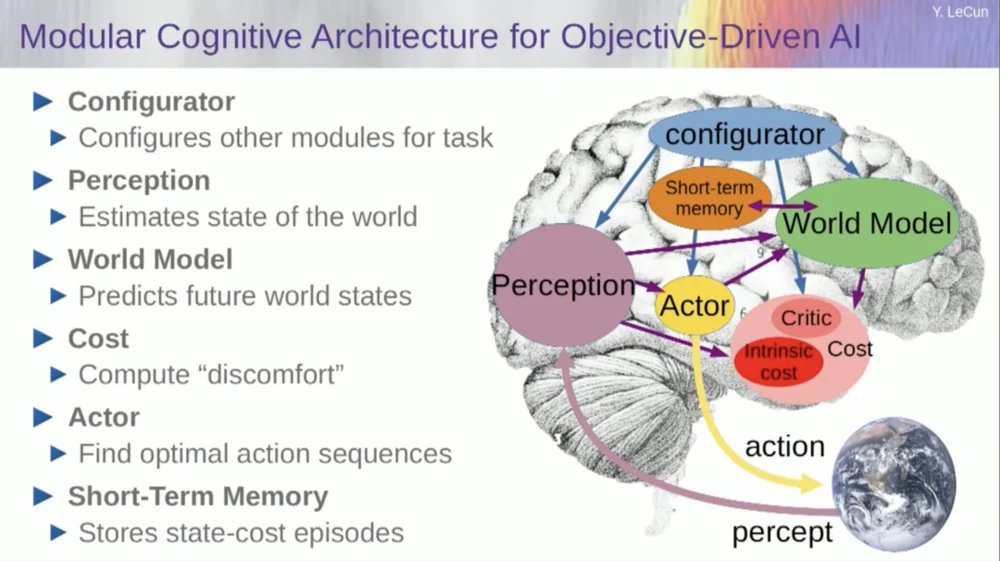
Итак, как это работает? Если ваше действие — это не одно действие, а последовательность действий, и ваша модель мира на самом деле представляет собой систему, которая говорит вам, учитывая состояние мира в момент времени T и возможные действия, предсказать состояние мира в момент времени T+1.
Вы хотите предсказать, какой эффект окажет последовательность двух действий в этой ситуации. Для достижения этой цели вы можете запустить свою модель мира несколько раз.
Получите исходное представление мирового состояния, введите предположение о нулевом значении действия, используйте модель для прогнозирования следующего состояния, затем выполните первое действие, вычислите следующее состояние, вычислите стоимость, а затем используйте методы обратного распространения ошибки и оптимизации на основе градиента, чтобы Узнайте, что позволит минимизировать стоимость двух действий. Это модель прогнозирующего управления.
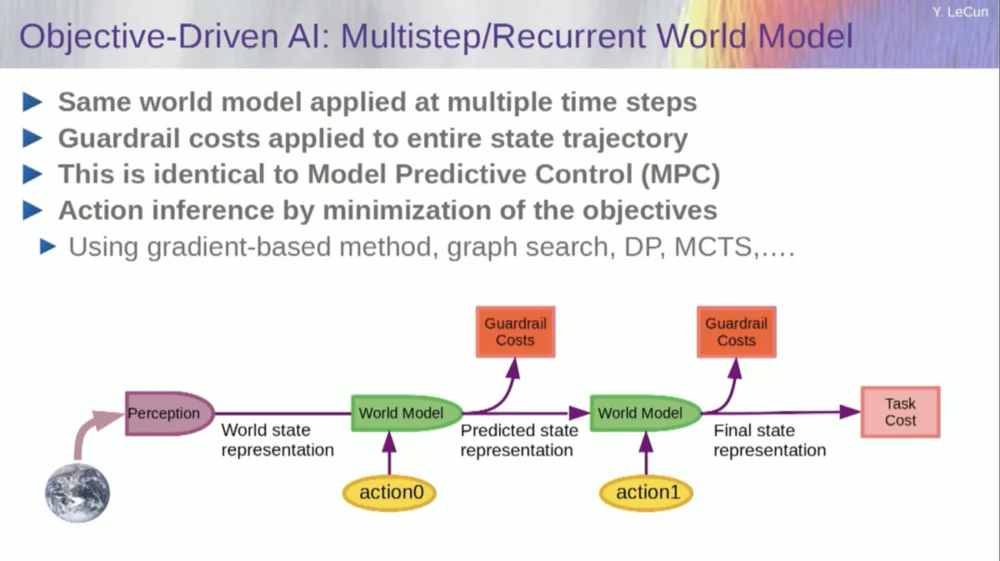
Мир не полностью детерминирован, поэтому вам придется использовать скрытые переменные, чтобы соответствовать вашей модели мира. Скрытые переменные — это, по сути, переменные, которые можно переключать внутри набора данных или брать из распределения, и они представляют собой переключение модели мира между несколькими предсказаниями, совместимыми с наблюдениями.
Еще более интересно то, что интеллектуальные системы в настоящее время не способны делать то, что могут делать люди и даже животные, а именно иерархическое планирование.
Например, если вы планировали поездку из Нью-Йорка в Париж, вы могли бы использовать свое понимание мира, своего тела и, возможно, свое представление обо всей конфигурации пути отсюда в Париж, чтобы спланировать всю поездку вместе со своим другом. низкий уровень мышечного контроля.
Верно? Если сложить количество шагов мышечного контроля за десять миллисекунд со всеми делами, которые вам предстоит сделать перед поездкой в Париж, получится огромное число. Итак, вы планируете иерархически, начиная с очень высокого уровня и говоря: «Хорошо, чтобы добраться до Парижа, мне сначала нужно съездить в аэропорт, сесть на самолет».
Как мне добраться до аэропорта? Допустим, я в Нью-Йорке, и мне нужно спуститься вниз и поймать такси. Как мне спуститься вниз? Мне нужно встать со стула, открыть дверь, подойти к лифту, нажать кнопку и т. д. Как мне встать со стула?
В какой-то момент вам придется выражать действия в виде низкоуровневых действий по контролю мышц, но мы не планируем все это на низкоуровневом уровне, мы занимаемся иерархическим планированием.

Как это сделать с помощью систем искусственного интеллекта, до сих пор полностью не решено, и мы понятия не имеем.
Кажется, это важное требование для разумного поведения.
Итак, как нам изучить модели мира, способные к иерархическому планированию, способные работать на разных уровнях абстракции? Ничего подобного никто не показал. Это серьезная задача. На изображении показан пример, который я только что упомянул.
Итак, как нам теперь обучать эту модель мира? Потому что это действительно большая проблема.
Я пытаюсь выяснить, в каком возрасте дети усваивают основные понятия об окружающем мире. Как они изучают интуитивную физику, физическую интуицию и все такое? Это происходит задолго до того, как они начинают изучать такие вещи, как язык и взаимодействие.
Таким образом, такие возможности, как отслеживание лиц, на самом деле появляются очень рано. Биологическое движение, различие между живыми и неодушевленными объектами, также появляется рано. То же самое касается постоянства объекта, которое означает, что объект сохраняется, когда он перекрыт другим объектом.
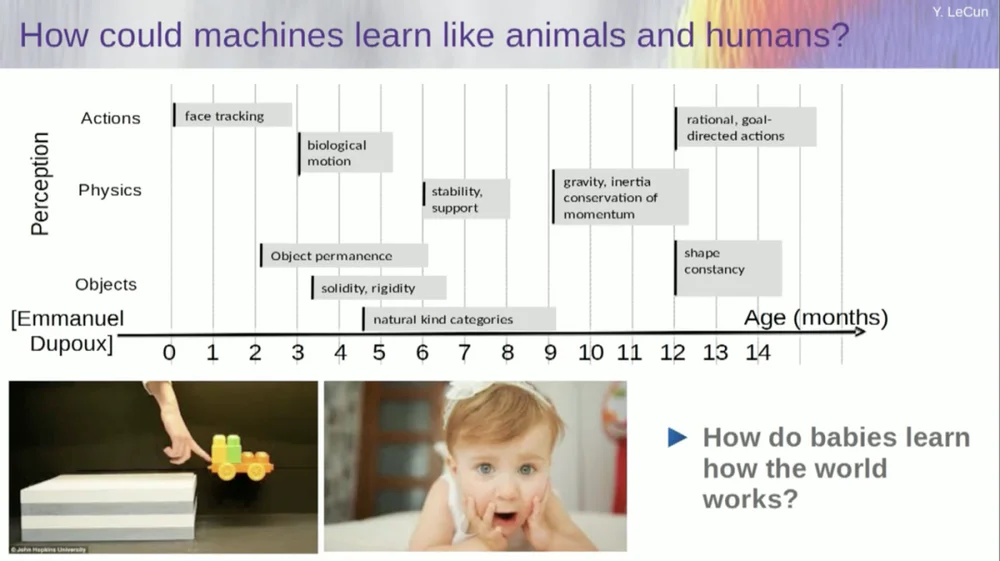
А дети учатся естественным путем, им не нужно давать названия вещам. Они будут знать, что стулья, столы и кошки разные. Что касается таких понятий, как стабильность и опора, такие как гравитация, инерция, сохранение и импульс, то они фактически не появляются примерно до девятимесячного возраста.
Это занимает много времени. Поэтому, если вы покажете шестимесячному ребенку сценарий слева, где тележка стоит на платформе, и столкнете ее с платформы, появится впечатление, что она парит в воздухе. Шестимесячный ребенок это заметит, а десятимесячный ребенок почувствует, что этого не должно происходить и предмет должен упасть.
Когда происходит что-то неожиданное, это означает, что ваша «модель мира» неверна. Итак, вы обратите внимание, потому что это может вас убить.
Таким образом, тип обучения, который здесь должен происходить, очень похож на тот тип обучения, который мы обсуждали ранее.
Возьмите входные данные, каким-либо образом исказите их и обучите большую нейронную сеть прогнозировать недостающие части. Если вы научите систему предсказывать, что произойдет в видео, точно так же, как мы обучаем нейронные сети предсказывать, что произойдет в тексте, возможно, эти системы смогут научиться здравому смыслу.
К сожалению, мы пытались это сделать в течение десяти лет, и это полный провал. Мы никогда не приближались к системе, которая могла бы получить какие-либо общие знания, просто пытаясь предсказать пиксели в видео.
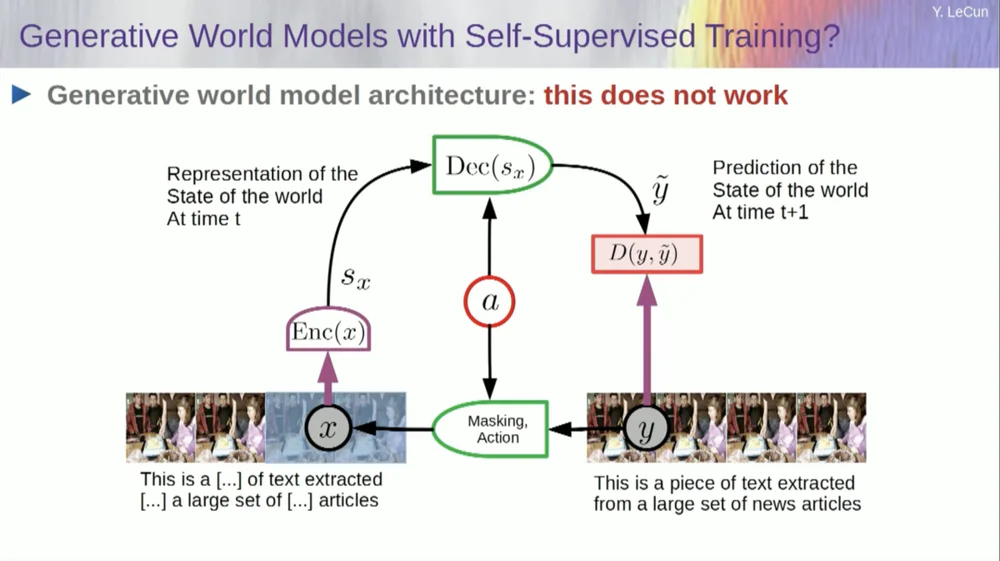
Вы можете научить систему прогнозировать видео, которые будут выглядеть хорошо. Существует множество примеров систем генерации видео, но внутренне они не являются хорошими моделями физического мира. Мы не можем сделать это с ними.
Итак, идея о том, что мы собираемся использовать генеративные модели для прогнозирования того, что произойдет с отдельными людьми, и система волшебным образом поймет структуру мира, является полным провалом.
За последнее десятилетие мы испробовали множество подходов.
Это терпит неудачу, потому что существует много возможных вариантов будущего. В дискретном пространстве, таком как текст, где вы можете предсказать, какое слово будет следовать за строкой слов, вы можете создать распределение вероятностей по возможным словам в словаре. Но когда дело доходит до видеокадров, у нас нет хорошего способа представить распределение вероятностей видеокадров. На самом деле эта задача совершенно невыполнима.

Типа, я снял видео этой комнаты, да? Я взял камеру и снял эту часть, а затем остановил видео. Я спросил систему, что будет дальше. Он мог бы предсказать оставшиеся комнаты. Будет стена, на ней будут сидеть люди, и плотность, вероятно, будет аналогична той, что слева, но точно предсказать на уровне пикселей все детали того, как будет выглядеть каждый из вас, совершенно невозможно. , текстуру мира и точный размер комнаты.
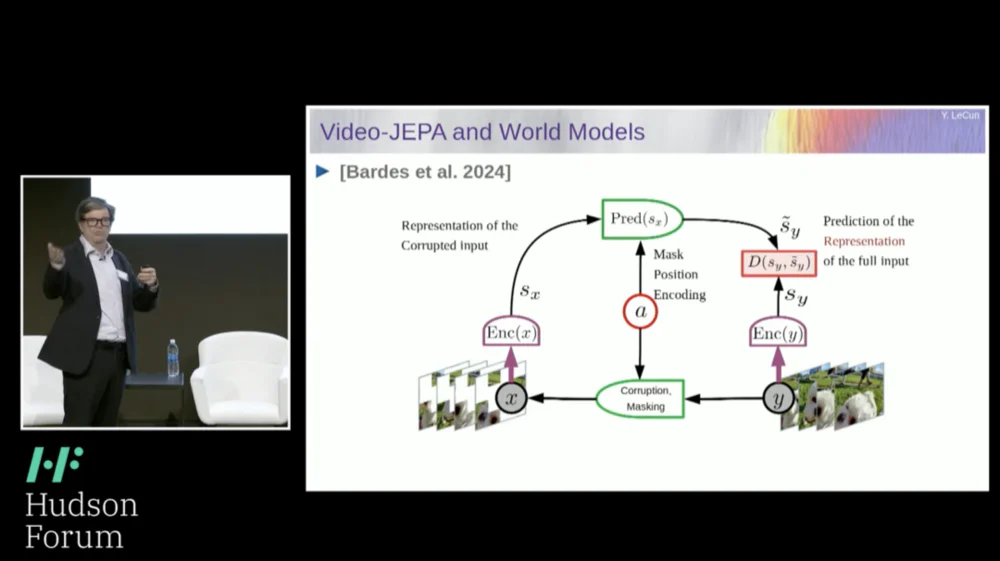
Итак, мое предлагаемое решение — Joint Embedding Prediction Architecture (JEPA) .
Идея состоит в том, чтобы отказаться от прогнозирования пикселей и вместо этого изучить абстрактное представление о том, как устроен мир, а затем делать прогнозы в этом пространстве представления. Это архитектура, архитектура прогнозирования совместного внедрения. Эти два внедрения принимают X (поврежденная версия) и Y соответственно, обрабатываются кодировщиком, а затем система обучается прогнозировать представление Y на основе представления X.
Проблема в том, что если вы обучите такую систему, просто используя градиентный спуск и обратное распространение ошибки, чтобы минимизировать ошибку прогнозирования, она рухнет. Он может изучить постоянное представление, чтобы прогнозы стали очень простыми, но неинформативными.
Итак, я хочу, чтобы вы запомнили разницу между автокодировщиками, генеративными архитектурами, автокодировщиками в масках и т. д., которые пытаются реконструировать прогнозы, и архитектурами совместного внедрения, которые делают прогнозы в пространстве представления.
Я думаю, что будущее за этими совместными архитектурами внедрения, и у нас есть много эмпирических доказательств того, что лучший способ изучить хорошие представления изображений — это использовать совместные архитектуры редактирования.
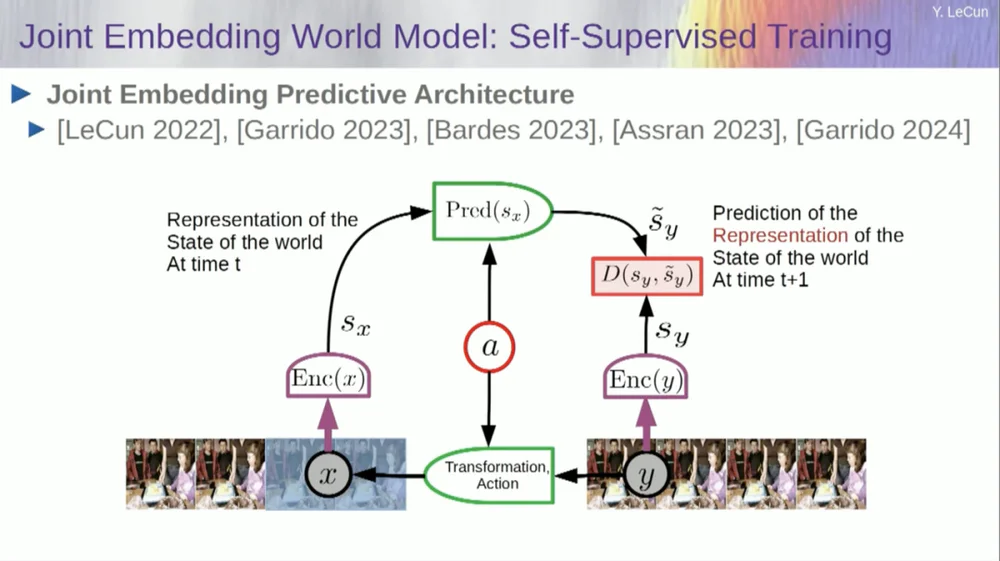
Все попытки изучить представления изображений посредством реконструкции были неудачными и неэффективными, и хотя есть много крупных проектов, заявляющих, что они работают, это не так, и наилучшая производительность достигается при использовании архитектуры справа.
Если задуматься, в этом и состоит суть нашего интеллекта: найти хорошее представление явления, чтобы мы могли делать прогнозы, — вот чем на самом деле занимается наука.
настоящий. Подумайте об этом: если вы хотите предсказать траекторию планеты, планета — очень сложный объект, она огромна, у нее есть всевозможные характеристики, такие как погода, температура и плотность.
Хоть это и сложный объект, для предсказания траектории планеты нужно знать всего 6 чисел: 3 координаты положения и 3 вектора скорости, и всё, больше ничего делать не нужно. Это очень важный пример, который действительно показывает, что суть предсказательной силы заключается в нахождении хорошего представления того, что мы наблюдаем.

Итак, как нам обучить такую систему?
Итак, вы хотите предотвратить сбой системы. Один из способов сделать это — использовать некоторую функцию стоимости, которая измеряет информационное содержание представления, выводимого кодером, и пытается максимизировать информационное содержание и минимизировать отрицательную информацию. Ваша система обучения должна одновременно извлекать как можно больше информации из входных данных, минимизируя при этом ошибку прогнозирования в этом пространстве представления.
Система найдет некоторый компромисс между извлечением как можно большего количества информации и отказом от извлечения непредсказуемой информации. Вы получите хорошее пространство представления, в котором можно делать прогнозы.
Итак, как вы измеряете информацию? Здесь все становится немного странно. Я пропущу это.
Машины превзойдут человеческий интеллект, станут безопасными и управляемыми
На самом деле существует способ понять это математически с помощью обучения, энергетических моделей и энергетических функций, но у меня нет времени вдаваться в подробности.
По сути, я говорю вам здесь несколько разных вещей: отказаться от генеративных моделей в пользу архитектур JEPA, отказаться от вероятностных моделей в пользу моделей, основанных на энергии, отказаться от контрастных методов обучения и обучения с подкреплением. Я говорю это уже 10 лет.
И это четыре самых популярных сегодня столпа машинного обучения. Так что я, вероятно, сейчас не очень популярен.
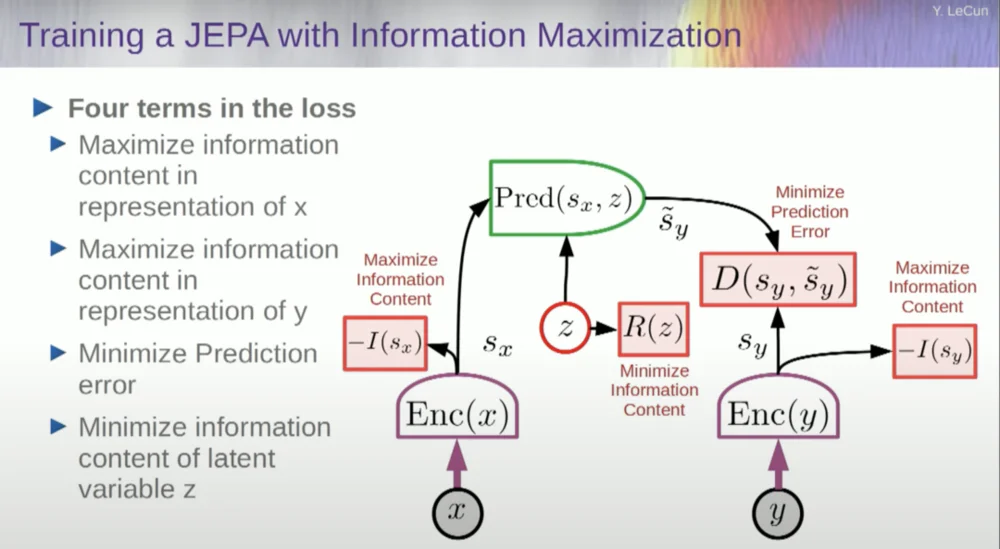
Один из подходов заключается в оценке информационного содержания путем измерения информационного содержания, поступающего от кодера.
В настоящее время существует шесть различных способов добиться этого. На самом деле, здесь есть метод под названием MCR, разработанный моими коллегами из Нью-Йоркского университета, который предназначен для предотвращения сбоев системы и создания констант.
Возьмите переменные из кодера и убедитесь, что эти переменные имеют ненулевое стандартное отклонение. Вы можете поместить это в функцию стоимости и убедиться, что веса ищутся, а переменные не схлопываются и не становятся константами. Это относительно просто.
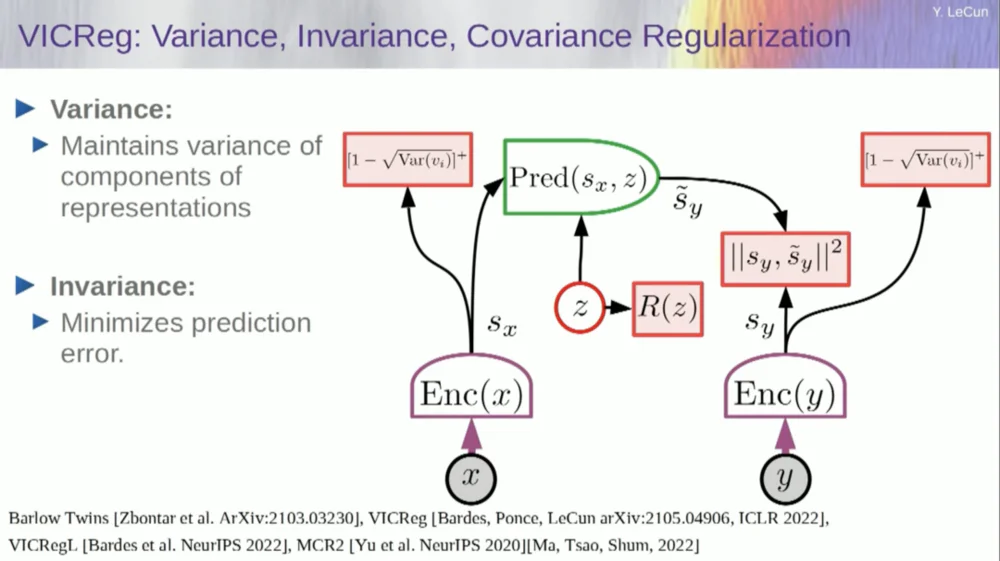
Проблема теперь в том, что система может «обмануть» и сделать все переменные равными или сильно коррелированными. Следовательно, вам необходимо добавить еще один член, недиагональный член, необходимый для минимизации ковариационной матрицы этих переменных, чтобы гарантировать их связь.
Конечно, этого недостаточно, поскольку переменные все равно могут быть зависимыми, но не связанными. Поэтому мы применяем другой метод расширения размеров SX до пространства VX более высокой размерности и применяем дисперсионно-ковариационную регуляризацию в этом пространстве, чтобы гарантировать выполнение требований.
Здесь есть еще одна хитрость, потому что я максимизирую верхний предел информационного содержания. Я хочу, чтобы фактическое информационное содержание соответствовало моей максимизации верхнего предела. Что мне нужно, так это нижний предел, чтобы он раздвигал нижний предел и увеличивал объем информации. К сожалению, у нас нет информации о нижних границах или, по крайней мере, мы не знаем, как их вычислять.
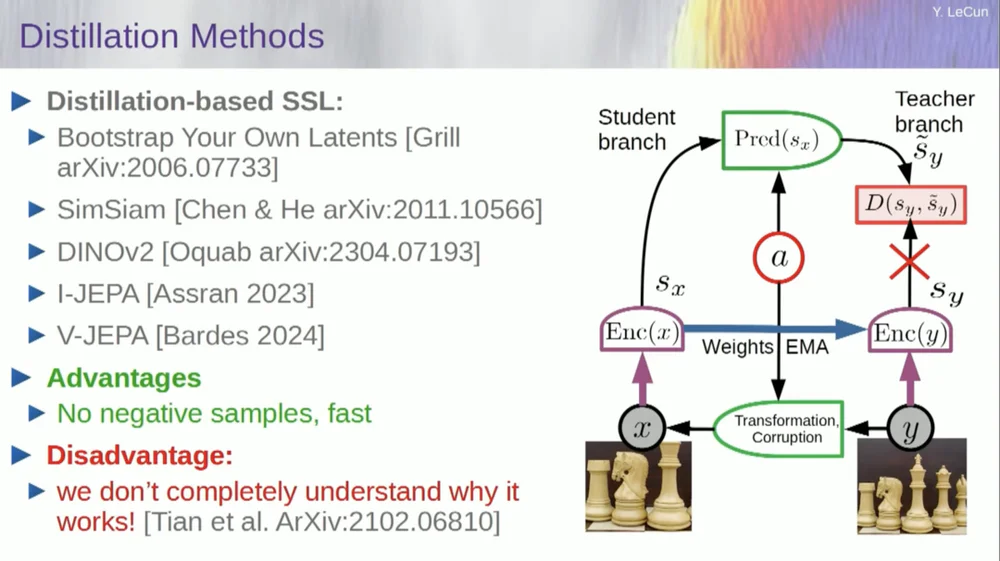
Существует второй набор методов, называемый «методом дистилляционного стиля».
Этот метод работает загадочным образом. Если вы хотите точно знать, кто что делает, вам следует спросить парня, сидящего здесь, в «Грилле».
У него есть личное эссе на эту тему, которое очень хорошо это определяет. Его основная идея заключается в обновлении только одной части модели без обратного распространения градиентов в другой части и интересном распределении весов. По этому аспекту также имеется множество работ.
Этот подход хорошо работает, если вы хотите обучить полностью самоуправляемую систему генерировать хорошие представления изображений. Уничтожение изображений осуществляется посредством маскировки, и недавняя работа, которую мы проделали для видео, позволяет нам обучить систему извлекать хорошие видеопредставления для использования в последующих задачах, таких как видео распознавания действий и т. д. Вы можете видеть, что маскирование большого фрагмента видео и создание прогнозов с помощью этого процесса используют этот трюк дистилляции в пространстве представления, чтобы предотвратить коллапс. Это прекрасно работает.
Итак, если мы добьемся успеха в этом проекте и получим системы, способные рассуждать, планировать и понимать физический мир, именно так будут выглядеть все наши взаимодействия в будущем.
Чтобы все заработало должным образом, потребуются годы, а может быть, даже десятилетие. Марк Цукерберг постоянно спрашивает меня, сколько времени это займет. Если нам это удастся, хорошо, у нас будут системы, которые станут посредниками во всех наших взаимодействиях с цифровым миром. Они ответят на все наши вопросы.
Они будут с нами еще долгое время и, по сути, станут хранилищем всех человеческих знаний. Это похоже на инфраструктуру, например на Интернет. Это не столько продукт, сколько инфраструктура.
Эти платформы ИИ должны иметь открытый исходный код. IBM и Meta участвуют в группе под названием «Альянс искусственного интеллекта», которая продвигает платформы искусственного интеллекта с открытым исходным кодом. Нам нужно, чтобы эти платформы имели открытый исходный код, потому что нам нужно разнообразие в этих системах искусственного интеллекта.

Нам нужно, чтобы они понимали все языки, все культуры, все системы ценностей в мире, и вы не получите этого от одной-единственной системы, созданной компанией на Западном или Восточном побережье США. Штаты. Это должен быть вклад всего мира.
Конечно, обучение финансовых моделей стоит очень дорого, поэтому этим способны заниматься лишь немногие компании. Если такие компании, как Meta, смогут предоставить базовую модель с открытым исходным кодом, тогда мир сможет настроить ее для своих собственных целей. Это философия, принятая Meta и IBM.

Таким образом, ИИ с открытым исходным кодом — это не просто хорошая идея, он необходим для культурного разнообразия и, возможно, даже для сохранения демократии.
Обучение и доработка будут осуществляться посредством краудсорсинга или экосистемы стартапов и других компаний.
Одна из причин, которая стимулирует рост экосистемы стартапов в области ИИ, — это доступность моделей ИИ с открытым исходным кодом. Сколько времени потребуется, чтобы достичь общего искусственного интеллекта? Я не знаю, это может занять годы или десятилетия.

На этом пути произошло много изменений, и остается еще много проблем, которые необходимо решить. Это почти наверняка будет сложнее, чем мы думаем. Это не происходит за один день, а представляет собой постепенную, постепенную эволюцию.
Так что дело не в том, что однажды мы откроем секрет всеобщего искусственного интеллекта, включим машину и мгновенно обретем сверхразум, и мы все будем уничтожены сверхразумом, нет, это не так.
Машины превзойдут человеческий интеллект, но они будут под контролем, потому что они целеустремленны. Мы ставим перед ними цели, и они их достигают. Как и многие из нас, мы являемся лидерами в промышленности или научных кругах.
Мы работаем с людьми умнее нас, и я, конечно, тоже. Тот факт, что есть много людей умнее меня, не означает, что они хотят доминировать или захватить власть, это просто правда. Конечно, за этим стоят риски, но я оставлю это для обсуждения позже, большое спасибо.