В области создания и понимания изображений с помощью ИИ существующие модели часто сталкиваются с проблемой балансирования возможностей понимания и генерации. Они неэффективны и полагаются на большое количество предварительно обученных компонентов. Платформа JanusFlow, запущенная DeepSeek AI, предлагает новую идею для решения этой проблемы. Редактор Downcodes даст вам глубокое понимание того, как JanusFlow достигает унификации понимания и генерации изображений посредством инновационного архитектурного дизайна и достигает замечательных результатов.
Несмотря на быстрый прогресс в области создания и понимания изображений с помощью искусственного интеллекта, остаются серьезные проблемы, которые препятствуют разработке целостного, унифицированного подхода.
В настоящее время модели, ориентированные на понимание изображений, как правило, плохо справляются с созданием высококачественных изображений, и наоборот. Такая архитектура разделения задач не только увеличивает сложность, но и ограничивает эффективность, затрудняя выполнение задач, требующих как понимания, так и генерации. Кроме того, многие существующие модели слишком сильно полагаются на архитектурные модификации или предварительно обученные компоненты для эффективного выполнения какой-либо функции, что приводит к компромиссам в производительности и проблемам интеграции.
Чтобы решить эти проблемы, DeepSeek AI запустила JanusFlow, мощную платформу искусственного интеллекта, предназначенную для унификации понимания и создания изображений. JanusFlow устраняет ранее упомянутые недостатки за счет интеграции понимания и создания изображений в единую архитектуру. Эта новая структура имеет минималистский дизайн, сочетающий авторегрессионные языковые модели с исправленным потоком — современный подход к генеративному моделированию.
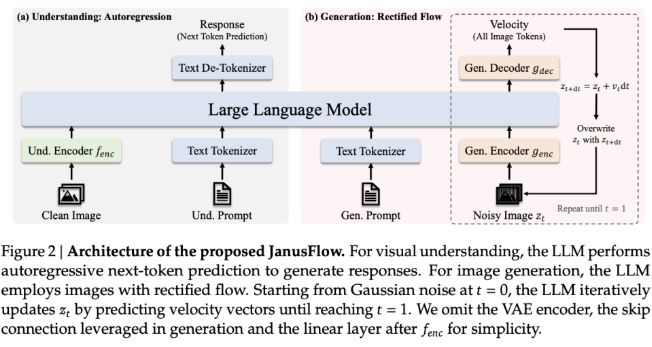
Устраняя необходимость в отдельных компонентах LLM и генерации, JanusFlow обеспечивает более тесную функциональную интеграцию, одновременно снижая сложность архитектуры. Он представляет двойную структуру кодировщика-декодера, разделяет задачи понимания и генерации и обеспечивает согласованность производительности в единой схеме обучения путем выравнивания представлений.
Что касается технических деталей, JanusFlow легко и эффективно объединяет корректирующий поток и большие языковые модели. Архитектура включает в себя независимые визуальные кодировщики для задач понимания и генерации. Во время обучения эти кодеры выравниваются друг с другом для улучшения семантической согласованности, что позволяет системе хорошо выполнять задачи генерации изображений и визуального понимания.
Такое разделение кодеров предотвращает помехи между задачами, тем самым расширяя возможности каждого модуля. Модель также использует руководство без классификатора (CFG) для контроля соответствия между сгенерированными изображениями и текстовыми условиями, тем самым улучшая качество изображения. По сравнению с традиционными унифицированными системами, которые используют диффузионные модели в качестве внешних инструментов, JanusFlow обеспечивает более простой и прямой процесс генерации с меньшими ограничениями. Эффективность этой архитектуры демонстрируется ее способностью соответствовать или превосходить производительность многих моделей для конкретных задач в нескольких тестах.
Важность JanusFlow заключается в его эффективности и универсальности, которые заполняют критический пробел в разработке мультимодальных моделей. Устраняя необходимость в независимых модулях генерации и понимания, JanusFlow позволяет исследователям и разработчикам использовать единую среду для решения нескольких задач, значительно снижая сложность и использование ресурсов.
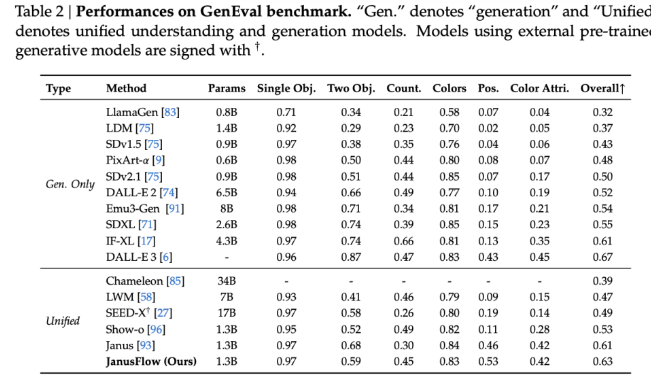
Результаты тестов показывают, что JanusFlow превосходит многие существующие унифицированные модели с оценками 74,9, 70,5 и 60,3 на MMBench, SeedBench и GQA соответственно. С точки зрения генерации изображений JanusFlow превзошел SDv1.5 и SDXL с результатом 9,51 для MJHQ FID-30k и 0,63 для GenEval. Эти показатели демонстрируют его превосходную способность генерировать высококачественные изображения и решать сложные мультимодальные задачи, используя всего 1,3 млрд параметров.
В заключение, JanusFlow сделал важный шаг на пути к разработке единой модели искусственного интеллекта, способной одновременно понимать и генерировать изображения. Его минималистский подход, ориентированный на интеграцию возможностей авторегрессии с корректирующими потоками, не только повышает производительность, но и упрощает архитектуру модели, делая ее более эффективной и доступной.
Отделяя визуальный кодер и выравнивая представления во время обучения, JanusFlow успешно объединяет понимание и генерацию изображений. Поскольку исследования ИИ продолжают расширять границы возможностей моделей, JanusFlow представляет собой важную веху на пути к созданию более универсальных и универсальных мультимодальных систем ИИ.
Модель: https://huggingface.co/deepseek-ai/JanusFlow-1.3B
Статья: https://arxiv.org/abs/2411.07975.
В целом, JanusFlow продемонстрировал большой потенциал в области мультимодального искусственного интеллекта благодаря своей эффективной архитектуре и превосходной производительности, указывая на новое направление развития будущих моделей искусственного интеллекта. С нетерпением ждем, когда JanusFlow сыграет свою роль в новых сценариях применения!