С быстрым развитием технологий искусственного интеллекта спрос на модели визуального языка растет с каждым днем, но высокие требования к вычислительным ресурсам ограничивают их применение на обычных устройствах. Редактор Downcodes представит вам сегодня облегченную модель визуального языка под названием SmolVLM, которая может эффективно работать на устройствах с ограниченными ресурсами, таких как ноутбуки и графические процессоры потребительского уровня. Появление SmolVLM дало большему количеству пользователей возможность испытать передовые технологии искусственного интеллекта, снизило порог использования, а также предоставило разработчикам более удобные инструменты исследования.
В последние годы растет спрос на применение моделей машинного обучения для решения зрительных и языковых задач, но большинство моделей требуют огромных вычислительных ресурсов и не могут эффективно работать на персональных устройствах. Особенно небольшие устройства, такие как ноутбуки, потребительские графические процессоры и мобильные устройства, сталкиваются с огромными проблемами при обработке задач визуального языка.
Возьмем в качестве примера Qwen2-VL, хотя он и обладает отличной производительностью, но имеет высокие требования к аппаратному обеспечению, что ограничивает его удобство использования в приложениях реального времени. Поэтому разработка облегченных моделей для работы с меньшими ресурсами стала важной необходимостью.
Hugging Face недавно выпустила SmolVLM, модель визуального языка с двумя параметрами, специально разработанную для рассуждений на стороне устройства. SmolVLM превосходит другие аналогичные модели с точки зрения использования памяти графического процессора и скорости генерации токенов. Его основной особенностью является возможность эффективной работы на небольших устройствах, таких как ноутбуки или графические процессоры потребительского уровня, без ущерба для производительности. СмолВЛМ находит идеальный баланс между производительностью и эффективностью, решая проблемы, которые было трудно преодолеть в предыдущих аналогичных моделях.
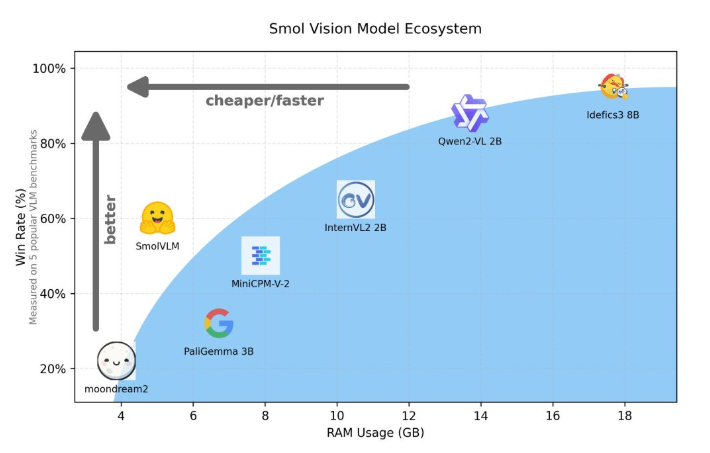
По сравнению с Qwen2-VL2B, SmolVLM генерирует токены в 7,5–16 раз быстрее благодаря оптимизированной архитектуре, которая делает возможным упрощенный вывод. Такая эффективность не только приносит конечным пользователям практическую выгоду, но и значительно повышает удобство работы с пользователем.
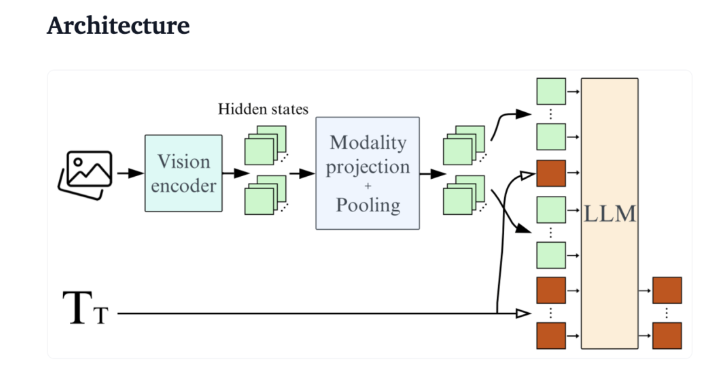
С технической точки зрения SmolVLM имеет оптимизированную архитектуру, которая поддерживает эффективный вывод на стороне устройства. Пользователи даже могут легко выполнить тонкую настройку Google Colab, значительно снизив порог экспериментирования и разработки.
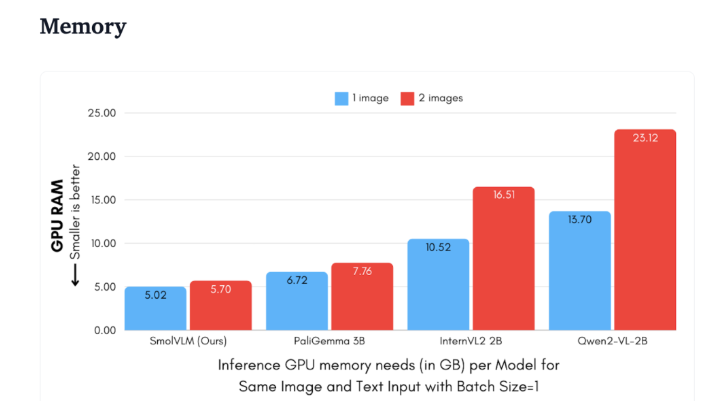
Благодаря небольшому объему памяти SmolVLM может бесперебойно работать на устройствах, которые ранее не могли поддерживать аналогичные модели. При тестировании 50-кадрового видео на YouTube SmolVLM показала хорошие результаты, набрав 27,14%, и опередила две более ресурсоёмкие модели по потреблению ресурсов, продемонстрировав сильную адаптивность и гибкость.
SmolVLM — важная веха в области визуальных языковых моделей. Его запуск позволяет выполнять сложные задачи визуального языка на повседневных устройствах, заполняя важный пробел в существующих инструментах искусственного интеллекта.
SmolVLM не только отличается скоростью и эффективностью, но также предоставляет разработчикам и исследователям мощный инструмент для облегчения обработки визуального языка без дорогостоящих затрат на оборудование. Поскольку технология искусственного интеллекта продолжает становиться все более популярной, такие модели, как SmolVLM, сделают мощные возможности машинного обучения более доступными.
демо: https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
В целом, SmolVLM установил новый стандарт для легких моделей визуального языка. Его эффективная работа и удобное использование будут во многом способствовать популяризации и развитию технологий искусственного интеллекта. Мы с нетерпением ждем новых подобных инноваций в будущем, которые позволят технологиям искусственного интеллекта принести пользу большему количеству людей.