В последние годы стоимость обучения крупномасштабных языковых моделей остается высокой, что стало важным фактором, ограничивающим развитие ИИ. В центре внимания отрасли стало то, как сократить затраты на обучение и повысить эффективность. Редактор Downcodes предлагает вам интерпретацию последней статьи исследователей из Гарвардского и Стэнфордского университетов. В этой статье предлагается правило масштабирования с учетом точности, которое эффективно снижает затраты на обучение за счет корректировки точности обучения модели, даже в некоторых случаях. В этом случае это также может улучшить производительность модели. Давайте подробнее рассмотрим это интересное исследование.
В области искусственного интеллекта больший масштаб, похоже, означает большие возможности. В поисках более мощных языковых моделей крупные технологические компании лихорадочно объединяют параметры моделей и данные обучения, но обнаруживают, что затраты также растут. Разве не существует экономичного и эффективного способа обучения языковых моделей?
Исследователи из Гарвардского и Стэнфордского университетов недавно опубликовали статью, в которой обнаружили, что точность обучения модели подобна скрытому ключу, который может открыть «код стоимости» обучения языковой модели.
Что такое точность модели? Проще говоря, это относится к параметрам модели и количеству цифр, используемых в процессе расчета. Традиционные модели глубокого обучения обычно используют для обучения 32-битные числа с плавающей запятой (FP32), но в последние годы, с развитием аппаратного обеспечения, используются типы чисел с более низкой точностью, такие как 16-битные числа с плавающей запятой (FP16) или 8-битные числа с плавающей запятой (FP16). битовые целые числа (INT8) Обучение уже возможно.
Итак, какое влияние окажет снижение точности модели на ее производительность? Это именно тот вопрос, который мы хотим изучить в этой статье? Посредством большого количества экспериментов исследователи проанализировали изменения стоимости и производительности обучения модели и вывода при различной точности, а также предложили новый набор правил масштабирования, учитывающих точность.
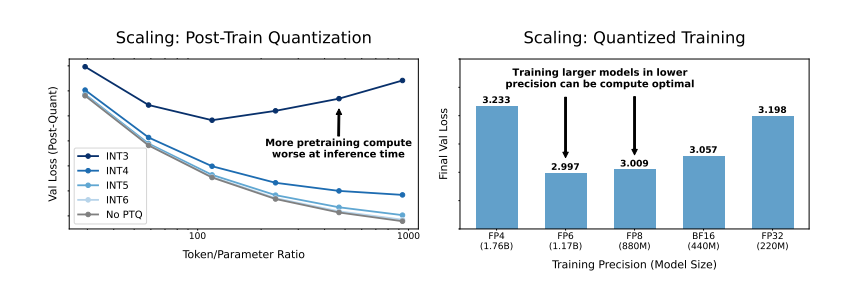
Они обнаружили, что обучение с более низкой точностью эффективно уменьшает «эффективное количество параметров» модели, тем самым уменьшая объем вычислений, необходимых для обучения. Это означает, что при том же вычислительном бюджете мы можем обучать более масштабные модели или в том же масштабе, используя более низкую точность, можно сэкономить много вычислительных ресурсов.
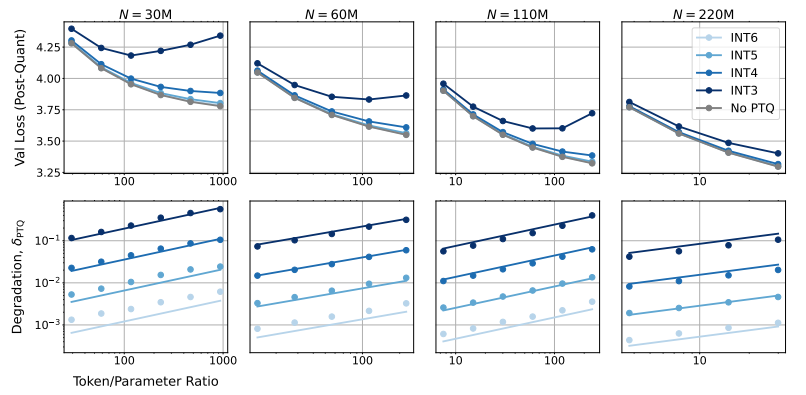
Еще более удивительно то, что исследователи также обнаружили, что в некоторых случаях обучение с более низкой точностью может фактически улучшить производительность модели. Например, для тех, где требуется «квантование после обучения». Если модель использует более низкую точность на этапе обучения, модель будет более устойчивой к снижению точности после квантования, тем самым показывая лучшую производительность на этапе вывода.
Итак, какую точность нам следует выбрать для обучения модели? Анализируя правила масштабирования, исследователи пришли к некоторым интересным выводам:
Традиционное 16-битное точное обучение может оказаться неоптимальным. Их исследования показывают, что точность в 7–8 цифр может быть более экономичным вариантом.
Также неразумно слепо проводить обучение со сверхнизкой точностью (например, 4-значным). Потому что при крайне низкой точности количество эффективных параметров модели резко упадет. Чтобы сохранить производительность, нам необходимо значительно увеличить размер модели, что, в свою очередь, приведет к увеличению вычислительных затрат.
Оптимальная точность обучения может различаться для моделей разных размеров. Для тех моделей, которые требуют большой «перетренированности», таких как серии «Лама-3» и «Джемма-2», тренировка с более высокой точностью может быть более рентабельной.
Это исследование открывает новый взгляд на понимание и оптимизацию обучения языковой модели. Это говорит нам о том, что выбор точности не статичен, но его необходимо взвешивать с учетом конкретного размера модели, объема обучающих данных и сценариев применения.
Конечно, у этого исследования есть некоторые ограничения. Например, модель, которую они использовали, является относительно мелкомасштабной, и экспериментальные результаты нельзя напрямую обобщить на модели более крупного масштаба. Кроме того, они сосредоточились только на функции потерь модели и не оценивали производительность модели на последующих задачах.
Тем не менее, это исследование по-прежнему имеет важные последствия. Он раскрывает сложную взаимосвязь между точностью модели, производительностью модели и стоимостью обучения, а также дает нам ценную информацию для разработки и обучения более мощных и экономичных языковых моделей в будущем.
Документ: https://arxiv.org/pdf/2411.04330.
В целом, это исследование предлагает новые идеи и методы для снижения затрат на обучение крупномасштабных языковых моделей, а также представляет собой важную справочную информацию для будущей разработки ИИ. Редактор Downcodes надеется на дальнейший прогресс в исследованиях точности моделей и внесет свой вклад в создание более экономичных моделей ИИ.