Редактор Downcodes сообщает: В последние годы технология анимации изображений на основе звука быстро развивалась, но существующие модели по-прежнему имеют узкие места с точки зрения эффективности и продолжительности. Чтобы решить эту проблему, исследователи разработали новую технологию под названием JoyVASA, которая значительно повышает качество и эффективность аудио-анимации изображений за счет оригинальной двухэтапной конструкции. JoyVASA не только способна создавать более длинные анимированные видеоролики, но также поддерживает анимацию лиц животных и демонстрирует хорошую многоязычную совместимость, открывая новые возможности в области производства анимации.
Недавно исследователи предложили новую технологию под названием JoyVASA, целью которой является улучшение эффектов анимации изображений, управляемых звуком. Благодаря постоянному развитию моделей глубокого обучения и распространения портретная анимация на основе звука добилась значительного прогресса в качестве видео и точности синхронизации губ. Однако сложность существующих моделей повышает эффективность обучения и вывода, а также ограничивает продолжительность и межкадровую непрерывность видео.
JoyVASA использует двухэтапный дизайн. На первом этапе вводится разделенная структура представления лица, позволяющая отделить динамические выражения лица от статических трехмерных представлений лица.
Такое разделение позволяет системе комбинировать любую статическую 3D-модель лица с динамическими последовательностями действий для создания более длинных анимированных видеороликов. На втором этапе исследовательская группа обучила диффузионный преобразователь, который может генерировать последовательности действий непосредственно из звуковых сигналов — процесс, не зависящий от личности персонажа. Наконец, генератор, основанный на первом этапе обучения, принимает трехмерное изображение лица и сгенерированную последовательность действий в качестве входных данных для визуализации высококачественных анимационных эффектов.
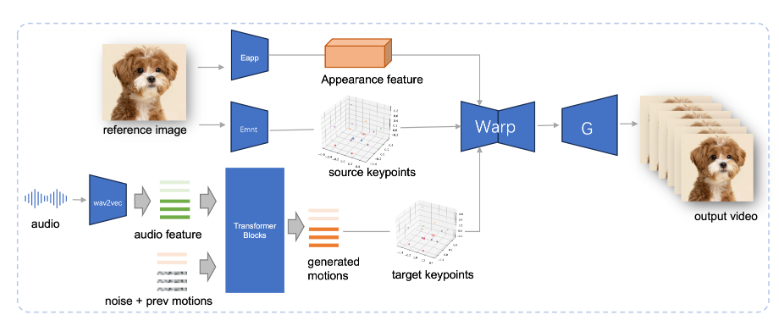
Примечательно, что JoyVASA не ограничивается анимацией портретов людей, но также может легко анимировать морды животных. Эта модель обучена на смешанном наборе данных, объединяющем частные данные на китайском языке и общедоступные данные на английском языке, что демонстрирует хорошие возможности многоязычной поддержки. Результаты экспериментов доказывают эффективность этого метода. Будущие исследования будут сосредоточены на улучшении производительности в реальном времени и совершенствовании управления выражениями для дальнейшего расширения применения этой структуры в анимации изображений.
Появление JoyVASA знаменует собой важный прорыв в технологии аудио-анимации, открывающий новые возможности в области анимации.
Вход в проект: https://jdh-algo.github.io/JoyVASA/
Инновация технологии JoyVASA заключается в ее эффективном двухэтапном проектировании и мощных возможностях многоязычной поддержки, что обеспечивает более удобное и эффективное решение для производства анимации. Ожидается, что в будущем, по мере дальнейшего совершенствования технологии, JoyVASA будет широко использоваться в большем количестве областей, что принесет нам более реалистичные и захватывающие анимационные работы. С нетерпением ждем новых технологических прорывов и открытия новой главы в развитии анимационной индустрии!