Быстрое развитие больших языковых моделей (LLM) впечатляет, но простого расширения масштаба модели недостаточно для достижения истинного интеллекта ИИ. Редактор Downcodes считает, что предоставление модели возможности саморазвиваться, чтобы она могла продолжать учиться и совершенствоваться на этапе вывода, имеет решающее значение для будущего развития ИИ. В этой статье будет рассмотрен ключевой фактор саморазвития ИИ — долговременная память (LTM), а также способы достижения постоянного прогресса в ИИ с помощью LTM.
Большие языковые модели (LLM), такие как серия GPT, продемонстрировали удивительные возможности в понимании языка, рассуждении и планировании с помощью своих огромных наборов данных и достигли уровня, сравнимого с человеческим в различных сложных задачах. Большинство исследований было сосредоточено на дальнейшем совершенствовании этих моделей путем их обучения на более крупных наборах данных с целью разработки более мощных базовых моделей.
Однако, хотя обучение более мощной базовой модели имеет решающее значение, исследователи полагают, что предоставление модели возможности продолжать развиваться на этапе вывода, то есть саморазвития ИИ, также имеет решающее значение для развития ИИ. По сравнению с использованием крупномасштабных данных для обучения модели, саморазвитие может потребовать лишь ограниченных данных или взаимодействий.
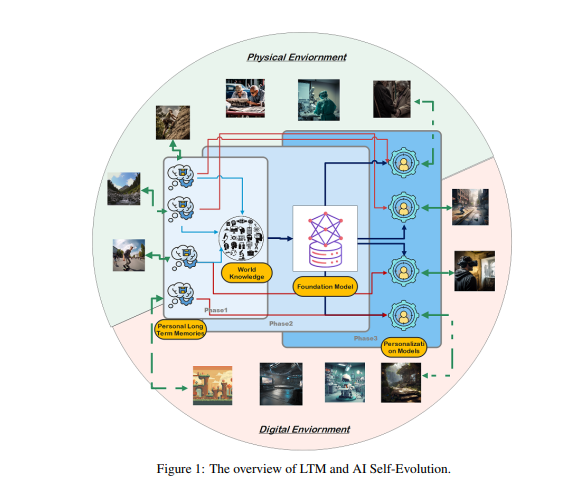
Вдохновленные столбчатой структурой коры головного мозга человека, исследователи предположили, что модели ИИ могут развивать возникающие когнитивные способности и строить модели внутреннего представления посредством итеративного взаимодействия с окружающей средой.
Для достижения этой цели исследователи предположили, что модель должна иметь долговременную память (LTM) для хранения и управления обработанными данными реального взаимодействия. LTM не только способен представлять отдельные данные с длинным хвостом в статистических моделях, но также способствует саморазвитию, поддерживая разнообразный опыт в различных средах и агентах.
LTM — это ключ к реализации саморазвития ИИ. Подобно тому, как люди постоянно учатся и совершенствуются посредством личного опыта и взаимодействия с окружающей средой, саморазвитие моделей ИИ также опирается на данные LTM, накопленные во время взаимодействия. В отличие от эволюции человека, эволюция модели, основанной на LTM, не ограничивается взаимодействием в реальном мире. Модели могут взаимодействовать с физической средой, как люди, и получать прямую обратную связь, которая обрабатывается для расширения их возможностей. Это также ключевая область исследований в области воплощенного ИИ.
С другой стороны, модели также могут взаимодействовать в виртуальных средах и накапливать данные LTM, что дешевле и эффективнее, чем взаимодействие в реальном мире, тем самым более эффективно расширяя возможности.
Создание LTM требует уточнения и структурирования необработанных данных. Под необработанными данными подразумевается сбор всех необработанных данных, полученных моделью при взаимодействии с внешней средой или в процессе обучения. Эти данные содержат множество наблюдений и записей, которые могут содержать ценные закономерности и большие объемы избыточной или нерелевантной информации.
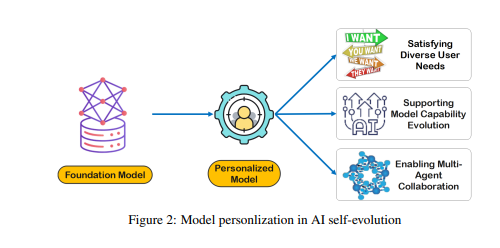
Хотя необработанные данные составляют основу памяти и познания модели, они требуют дальнейшей обработки, прежде чем их можно будет эффективно использовать для персонализации или эффективного выполнения задач. LTM уточняет и структурирует эти необработанные данные, чтобы модель могла их использовать. Этот процесс расширяет возможности модели предоставлять персонализированные ответы и рекомендации.
Создание LTM сталкивается с такими проблемами, как разреженность данных и разнообразие пользователей. В постоянно обновляемых системах LTM разреженность данных является распространенной проблемой, особенно для пользователей с ограниченной историей взаимодействия или разрозненными действиями, что затрудняет обучение модели. Кроме того, разнообразие пользователей также усложняет ситуацию, требуя от моделей как адаптации к индивидуальным шаблонам, так и эффективного обобщения для различных групп пользователей.
Исследователи разработали систему многоагентной совместной работы под названием Omne, которая реализует саморазвитие ИИ на основе LTM. В этой структуре каждый агент имеет независимую системную структуру и может автономно изучать и хранить полную модель среды для построения независимого понимания среды. Благодаря этой совместной разработке на основе LTM система ИИ может адаптироваться к изменениям в индивидуальном поведении в режиме реального времени, оптимизировать планирование и выполнение задач, а также способствовать дальнейшему персонализированному и эффективному саморазвитию ИИ.
Платформа Omne заняла первое место в эталонном тесте GAIA, доказав огромный потенциал использования LTM для саморазвития ИИ и решения реальных проблем. Исследователи полагают, что продвижение исследований LTM имеет решающее значение для дальнейшего развития и практического применения технологии искусственного интеллекта, особенно с точки зрения саморазвития.
В целом, долговременная память является ключом к саморазвитию ИИ, позволяя моделям ИИ учиться и совершенствоваться на основе опыта, как и люди. Создание и использование LTM требует преодоления таких проблем, как разреженность данных и разнообразие пользователей. Платформа Omne обеспечивает реальное решение для саморазвития искусственного интеллекта на основе LTM, а ее успех в эталонном тесте GAIA демонстрирует огромный потенциал в этой области.
Документ: https://arxiv.org/pdf/2410.15665.
Благодаря исследованиям долговременной памяти (LTM) самоэволюция ИИ больше не является далекой мечтой. Ожидается, что в будущем модели искусственного интеллекта на основе LTM продемонстрируют более мощные возможности в более широком спектре областей и принесут большую пользу человеческому обществу. Ждём новых инновационных результатов!