Исследовательская группа Apple по искусственному интеллекту выпустила новое поколение мультимодальных больших языковых моделей MM1.5, которые могут интегрировать несколько типов данных, таких как текст и изображения, и продемонстрировали высокую производительность в таких задачах, как визуальный ответ на вопрос, генерация изображений и многоуровневая обработка данных. возможность модальной интерпретации данных. MM1.5 преодолевает трудности предыдущих мультимодальных моделей при обработке текстовых изображений и мелкозернистых визуальных задачах. Благодаря инновационному подходу, ориентированному на данные, он использует данные оптического распознавания символов высокого разрешения и синтетические описания изображений, чтобы значительно улучшить производительность модели. . Понимание. Редактор Downcodes даст вам глубокое понимание нововведений MM1.5 и его превосходной производительности в многочисленных тестах производительности.
Недавно исследовательская группа Apple по искусственному интеллекту представила новое поколение мультимодальных моделей больших языков (MLLM) — MM1.5. Эта серия моделей может комбинировать несколько типов данных, таких как текст и изображения, демонстрируя нам новую способность ИИ понимать сложные задачи. Такие задачи, как визуальный ответ на вопрос, генерация изображений и интерпретация мультимодальных данных, можно лучше решить с помощью этих моделей.
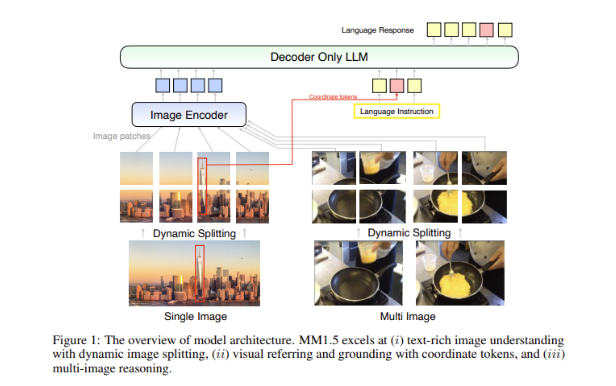
Большой проблемой в мультимодальных моделях является то, как добиться эффективного взаимодействия между различными типами данных. Предыдущие модели часто сталкивались с трудностями при работе с насыщенными текстом изображениями или мелкозернистыми задачами по зрению. Поэтому исследовательская группа Apple внедрила в модель MM1.5 инновационный метод, ориентированный на данные, используя данные оптического распознавания символов высокого разрешения и синтетические описания изображений, чтобы улучшить возможности понимания модели.
Этот метод не только позволяет MM1.5 превзойти предыдущие модели в задачах визуального понимания и позиционирования, но также запускает две специализированные версии модели: MM1.5-Video и MM1.5-UI, которые используются для понимания и позиционирования видео соответственно. Анализ мобильного интерфейса.
Обучение модели ММ1.5 разделено на три основных этапа.
Первый этап — это крупномасштабное предварительное обучение с использованием 2 миллиардов пар изображений и текстовых данных, 600 миллионов чередующихся изображений и текстовых документов и 2 триллионов текстовых токенов.
Второй этап заключается в дальнейшем повышении производительности задач с обогащенными текстом изображениями посредством непрерывной предварительной обработки 45 миллионов высококачественных данных оптического распознавания символов и 7 миллионов синтетических описаний.
Наконец, на этапе контролируемой тонкой настройки модель оптимизируется с использованием тщательно отобранных данных с одним изображением, несколькими изображениями и только текстовыми данными, чтобы улучшить ее при детальной визуальной ссылке и рассуждениях с несколькими изображениями.
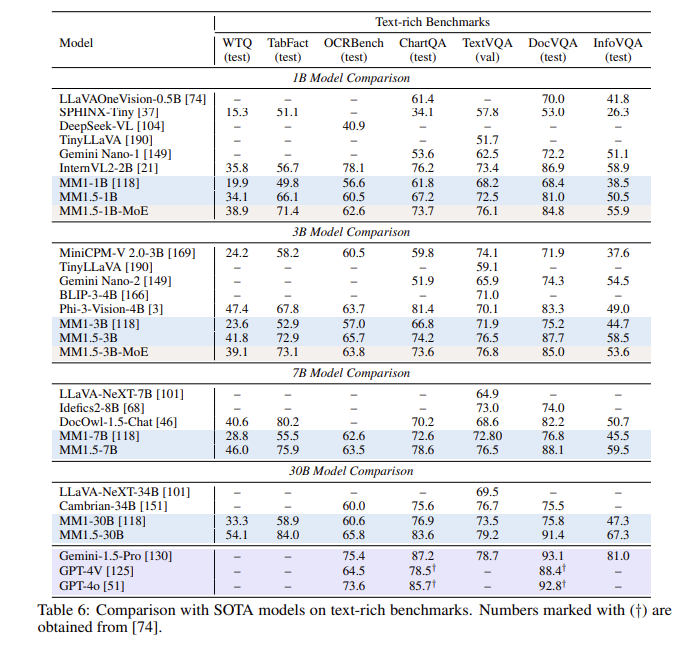
После серии оценок модель MM1.5 показала хорошие результаты в нескольких тестах производительности, особенно при работе с текстовыми изображениями, с улучшением на 1,4 балла по сравнению с предыдущей моделью. Кроме того, даже ММ1.5-Видео, специально разработанная для понимания видео, достигла лидирующего уровня в смежных задачах благодаря своим мощным мультимодальным возможностям.
Семейство моделей MM1.5 не только устанавливает новый стандарт для мультимодальных моделей большого языка, но также демонстрирует свой потенциал в различных приложениях, от общего понимания текста изображения до анализа видео и пользовательского интерфейса, и все это с выдающейся производительностью.
Выделять:
**Варианты моделей**: включают плотные модели и модели MoE с параметрами от 1 до 30 миллиардов, что обеспечивает масштабируемость и гибкое развертывание.
? **Обучающие данные**: использование 2 миллиардов пар изображения-текста, 600 миллионов чередующихся документов изображения-текста и 2 триллионов текстовых токенов.
**Улучшение производительности**. В сравнительном тесте, посвященном распознаванию текстовых изображений, было достигнуто улучшение на 1,4 балла по сравнению с предыдущей моделью.
В целом семейство моделей Apple MM1.5 добилось значительного прогресса в области мультимодальных моделей большого языка, а его инновационные методы и отличная производительность открывают новое направление для будущего развития ИИ. Мы с нетерпением ждем, когда MM1.5 продемонстрирует свой потенциал в большем количестве сценариев применения.