В эпоху информационного взрыва крайне важно эффективно обрабатывать текстовую информацию в изображениях. Редактор Downcodes сегодня представит революционную модель оптического распознавания символов — GOT (Общая теория оптического распознавания символов), которая знаменует собой вступление технологии оптического распознавания символов в эпоху 2.0. Модель GOT сочетает в себе преимущества традиционного оптического распознавания символов и больших языковых моделей и обеспечивает новые прорывы в области распознавания текста благодаря своей высокой производительности и универсальности. Он может не только распознавать английские и китайские документы и тексты сцен, но также обрабатывать сложную информацию, такую как математические и химические формулы, музыкальные символы, диаграммы и т. д. Его можно назвать «универсальным игроком» в области оптического распознавания символов.
В эпоху цифровых технологий быстрое преобразование текстового содержимого изображений в редактируемый текст является распространенным и важным требованием. Теперь появление новой модели оптического распознавания символов (OCR) под названием GOT (Общая теория оптического распознавания символов) знаменует вступление технологии OCR в эпоху 2.0. Эта инновационная модель сочетает в себе преимущества традиционных систем оптического распознавания символов и крупномасштабных языковых моделей для создания более эффективного и интеллектуального инструмента распознавания текста.
Модель GOT использует инновационную сквозную архитектуру. Эта конструкция не только экономит ресурсы, но и значительно расширяет возможности распознавания за пределы распознавания текста. Модель состоит из кодера изображения примерно с 80 миллионами параметров и декодера примерно с 5 миллионами параметров. Кодер изображений способен сжимать изображения размером до 1024x1024 пикселей в блоки данных, а декодер преобразует эти данные в текст длиной до 8000 символов.
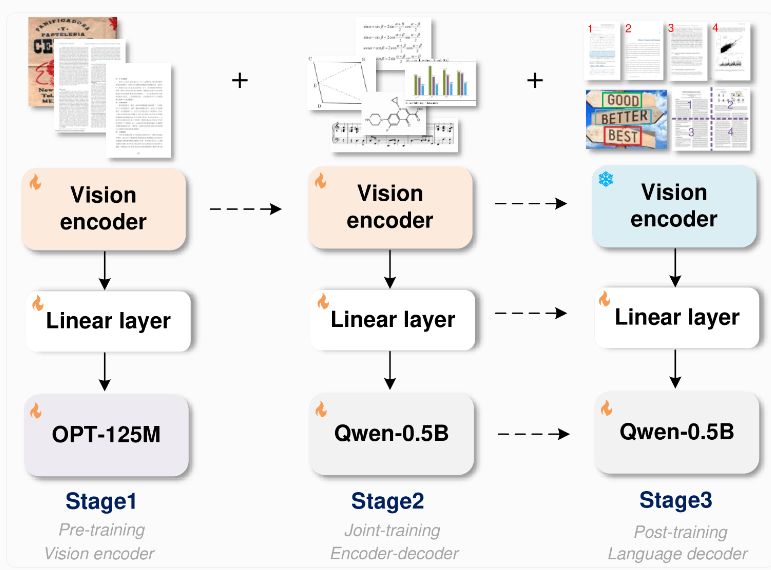
Сила GOT заключается в его универсальности. Он может не только распознавать и преобразовывать английские и китайские документы и тексты сцен, но также обрабатывать математические и химические формулы, музыкальные символы, простые геометрические фигуры и различные диаграммы. Это делает GOT настоящим универсалом.
Чтобы обучить эту модель, исследовательская группа сначала сосредоточилась на задачах распознавания текста, затем использовала Qwen-0.5B от Alibaba в качестве декодера и настроила его на различные синтетические данные. Они использовали профессиональные инструменты рендеринга, такие как LaTeX, Mathpix-markdown-it и Matplotlib, для создания миллионов пар изображение-текст для обучения модели.

Еще одной особенностью технологии OCR2.0 является ее способность извлекать форматированный текст, заголовки и даже многостраничные изображения и преобразовывать их в структурированный цифровой формат. Это открывает новые возможности для автоматизированной обработки и анализа в таких областях, как наука, музыка и анализ данных.
В тестах различных задач OCR GOT продемонстрировал отличную производительность, достигнув лучших в отрасли результатов в распознавании текста документов и сцен и даже превзойдя многие профессиональные модели и большие языковые модели в распознавании диаграмм. Будь то сложные формулы химической структуры или нотная запись и визуализация данных, OCR2.0 может точно фиксировать и преобразовывать их в машиночитаемые форматы.
Чтобы позволить большему количеству пользователей испытать и использовать эту технологию, исследовательская группа выпустила бесплатные демоверсии и код на платформе Hugging Face. Появление OCR2.0, несомненно, произвело революцию в области обработки информации. Оно не только повышает эффективность, но и повышает гибкость, позволяя нам легче обрабатывать текстовую информацию в изображениях.
Появление модели GOT, несомненно, вдохнуло новую жизнь в технологию оптического распознавания символов. Ее эффективные, точные и универсальные функции будут широко использоваться во всех сферах жизни, обеспечивая больше удобства в работе и жизни людей. Мы с нетерпением ждем дальнейшего улучшения модели GOT в будущем и преподнесем нам еще больше сюрпризов!