Редактор Downcodes узнал, что прорывное исследование Йельского университета раскрыло секрет обучения моделей ИИ: чем сложность данных не выше, тем лучше, но существует оптимальное состояние «на грани хаоса». Исследовательская группа умело использовала модель клеточного автомата для проведения экспериментов, изучила влияние данных разной сложности на обучающий эффект модели ИИ и пришла к примечательным выводам.
Исследовательская группа Йельского университета недавно опубликовала новаторский результат исследования, раскрывающий ключевой вывод в обучении моделей ИИ: данные с лучшим эффектом обучения ИИ не являются более простыми или сложными, но существует оптимальный уровень сложности — состояние, известное как край хаоса.
Исследовательская группа проводила эксперименты с использованием элементарных клеточных автоматов (ЭКА), которые представляют собой простые системы, в которых будущее состояние каждого блока зависит только от него самого и состояний двух соседних блоков. Несмотря на простоту правил, такие системы могут создавать разнообразные модели — от простых до очень сложных. Затем исследователи оценили эффективность этих языковых моделей при решении задач на рассуждение и предсказании шахматных ходов.
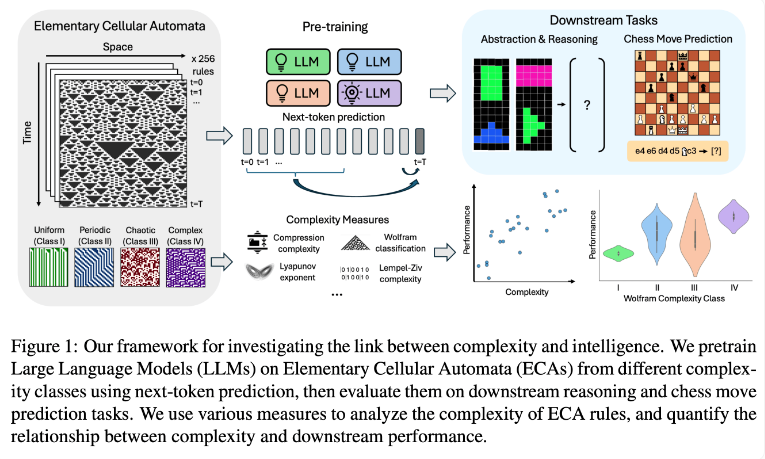
Результаты исследований показывают, что модели ИИ, обученные на более сложных правилах ECA, лучше справляются с последующими задачами. В частности, лучшие результаты показали модели, обученные на ECA класса IV по классификации Wolfram. Паттерны, создаваемые такими правилами, не являются ни полностью упорядоченными, ни полностью хаотичными, а скорее демонстрируют структурированную сложность.
Исследователи обнаружили, что, когда модели подвергались воздействию слишком простых шаблонов, они часто усваивали только простые решения. Напротив, модели, обученные на более сложных шаблонах, развивают более сложные возможности обработки, даже если доступны простые решения. Исследовательская группа предполагает, что сложность этого изученного представления является ключевым фактором в способности модели передавать знания для других задач.
Это открытие может объяснить, почему большие языковые модели, такие как GPT-3 и GPT-4, настолько эффективны. Исследователи полагают, что огромные и разнообразные данные, используемые при обучении этих моделей, могли создать эффекты, аналогичные сложным моделям ECA в их исследовании.
Это исследование предлагает новые идеи для обучения моделей ИИ и новую перспективу для понимания мощных возможностей больших языковых моделей. В будущем, возможно, мы сможем еще больше улучшить производительность и возможности обобщения моделей ИИ, более точно контролируя сложность обучающих данных. Редактор Downcodes считает, что этот результат исследования окажет глубокое влияние на область искусственного интеллекта.