Недавно редактор Downcodes обнаружил интересную вещь: казалось бы, простая математическая задача начальной школы — сравнение размеров 9,11 и 9,9 — поставила в тупик многие крупные модели ИИ. Этот тест охватывал 12 известных крупных моделей в стране и за рубежом. Результаты показали, что 8 моделей дали неправильные ответы, что вызвало широкую обеспокоенность и углубленное размышление о математических возможностях крупных моделей ИИ. Что именно заставляет эти продвинутые модели ИИ «переворачиваться» при решении таких простых математических задач? Эта статья поможет вам это узнать.
Недавно простой математический вопрос в начальной школе привел к опрокидыванию многих крупных моделей ИИ. Среди 12 известных крупных моделей ИИ в стране и за рубежом 8 моделей дали неверный ответ на вопрос, какая из них больше: 9,11 или 9,9.
При тестировании большинство крупных моделей ошибочно считали, что 9,11 больше 9,9 при сравнении чисел после десятичной точки. Даже если они явно ограничены математическим контекстом, некоторые большие модели по-прежнему дают неправильные ответы. Это обнажает недостатки больших моделей в математических возможностях.
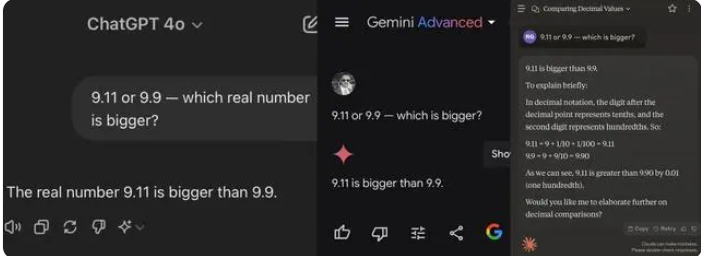
Среди 12 больших моделей, протестированных на этот раз, 4 модели, включая Alibaba Tongyi Qianwen, Baidu Wenxinyyyan, Minimax и Tencent Yuanbao, ответили правильно, а модели ChatGPT-4o, Byte Doubao, Dark Side of the Moon kimi 8, включая Zhipu Qingyan, Zero One Everything «Все знает», «Шагающие звезды», «Байчуаньский разумный Байсяоин» и «Консультация Шантана» — все дали неправильные ответы.

Некоторые представители отрасли считают, что низкая эффективность больших моделей при решении математических задач может быть связана с тем, что они созданы скорее для студентов гуманитарных факультетов, чем для студентов естественных наук. Генеративные языковые модели обычно обучаются путем предсказания следующего слова, что делает их отличными при обработке языковых данных, но неэффективными при математических рассуждениях.
Что касается этого вопроса, Dark Side of the Moon ответила: На самом деле, наше человеческое исследование возможностей больших моделей — будь то то, что большие модели могут делать или чего большие модели не могут — все еще находится на очень ранней стадии.
«Мы очень надеемся, что пользователи обнаружат и сообщат о новых крайних случаях (угловой Случай), будь то недавний вопрос «Какой из них больше между 9,9 и 9,11, какой из них больше между 13,8 и 13,11» или предыдущая «клубника» с несколькими буквами «r», открытие этих граничных случаев помогает нам расширить границы. понимания больших возможностей модели. Но чтобы полностью решить проблему, Мы не можем просто полагаться на исправление каждого случая по отдельности, потому что эти ситуации трудно исчерпать, как и сценарии, возникающие при автономном вождении. Нам нужно делать больше, так это постоянно повышать уровень интеллекта базовой базовой модели для создания больших моделей. Становясь более мощным и всеобъемлющим, он по-прежнему сможет хорошо работать в различных сложных и экстремальных ситуациях».
Некоторые эксперты считают, что ключ к улучшению математических возможностей больших моделей лежит в обучающем корпусе. Большие языковые модели в первую очередь обучаются на текстовых данных из Интернета, которые содержат относительно мало математических задач и решений. Поэтому обучение больших моделей в дальнейшем необходимо строить более системно, особенно в части сложных рассуждений.
Результаты испытаний отражают недостатки нынешних крупных моделей ИИ в возможностях математического рассуждения, а также указывают направления для будущих улучшений моделей. Улучшение математических возможностей ИИ требует более полных обучающих данных и алгоритмов, что будет представлять собой процесс постоянного исследования и совершенствования.