В последние годы быстрое развитие технологий искусственного интеллекта во многом зависит от обучения огромных данных. Однако редактор Downcodes обнаружил, что последние исследования Массачусетского технологического института и других учреждений указывают на то, что сложность получения данных резко возрастает. Сетевые данные, которые когда-то были легко доступны, теперь подвергаются все более строгим ограничениям, что создает огромные проблемы для обучения и развития ИИ. Исследование, в ходе которого было проанализировано несколько наборов данных с открытым исходным кодом, раскрывает эту суровую реальность.
За бурным развитием искусственного интеллекта всплывает серьезная проблема — возрастает сложность сбора данных. Последние исследования Массачусетского технологического института и других институтов показали, что веб-данные, которые когда-то были легко доступны, теперь становятся все труднее доступны, что представляет собой серьезную проблему для обучения и исследований в области искусственного интеллекта.
Исследователи обнаружили, что веб-сайты, сканируемые с помощью нескольких наборов данных с открытым исходным кодом, таких как C4, RefineWeb, Dolma и т. д., быстро ужесточают свои лицензионные соглашения. Это не только влияет на обучение коммерческих моделей ИИ, но и препятствует исследованиям академических и некоммерческих организаций.

Это исследование было проведено четырьмя руководителями групп из Медиа-лаборатории Массачусетского технологического института, Колледжа Уэллсли, AI-стартапа Raive и других учреждений. Они отмечают, что ограничения на данные распространяются, а асимметрия и несоответствия лицензирования становятся все более очевидными.
В качестве методов исследования исследовательская группа использовала Протокол исключения роботов (REP) и Условия обслуживания веб-сайта (ToS). Они обнаружили, что даже сканеры таких крупных компаний, занимающихся искусственным интеллектом, как OpenAI, сталкиваются со все более жесткими ограничениями.
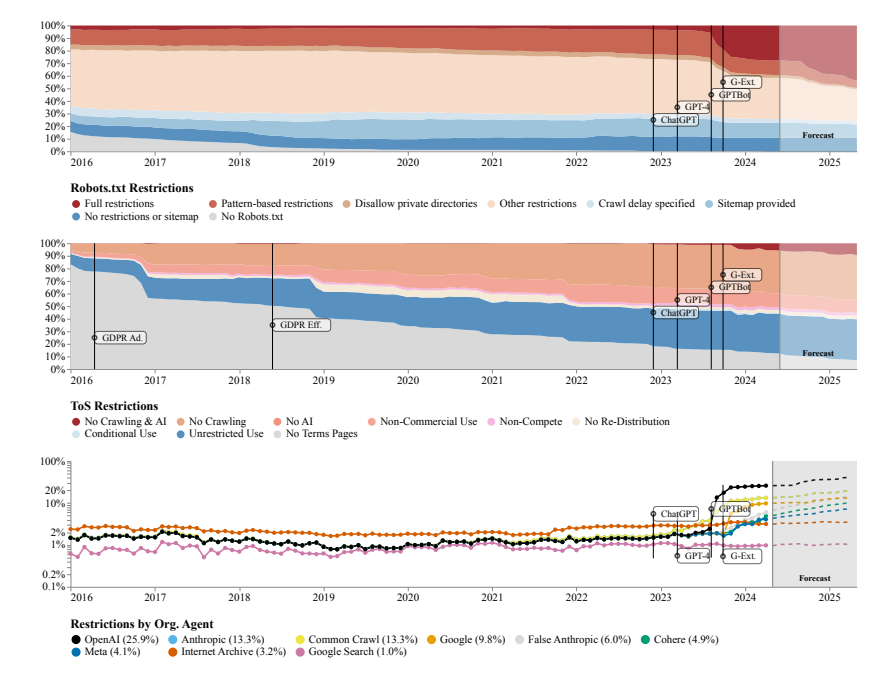
Модель SARIMA предсказывает, что в будущем, будь то через robots.txt или ToS, ограничения на данные веб-сайта будут продолжать увеличиваться. Это говорит о том, что доступ к открытым сетевым данным станет сложнее.
Исследование также показало, что данные, полученные из Интернета, не соответствуют целям обучения модели ИИ, что может повлиять на согласованность модели, методы сбора данных и авторские права.
Исследовательская группа призывает к необходимости более гибких соглашений, отражающих пожелания владельцев веб-сайтов, разделяющих разрешенные и недопустимые варианты использования и синхронизирующихся с условиями обслуживания. В то же время они хотят, чтобы разработчики ИИ могли использовать данные в открытой сети для обучения, и надеются, что будущие законы поддержат это.
Адрес статьи: https://www.dataprovenance.org/Consent_in_Crisis.pdf.
Это исследование забило тревогу по поводу проблемы сбора данных в области искусственного интеллекта, а также поставило новые задачи для обучения и разработки будущих моделей ИИ. Как сбалансировать сбор данных и права и интересы владельцев веб-сайтов, станет ключевым вопросом, который необходимо серьезно рассмотреть и решить в сфере искусственного интеллекта. Редактор Downcodes рекомендует обратить внимание на статью, чтобы узнать подробности.