Область обработки естественного языка (NLP) меняется с каждым днем, и быстрое развитие больших языковых моделей (LLM) принесло нам беспрецедентные возможности и проблемы. Среди них узким местом является зависимость оценки модели от данных, аннотированных человеком. Высокая стоимость и трудоемкость работы по сбору данных ограничивают эффективную оценку и постоянное совершенствование модели. Редактор Downcodes познакомит вас с новым решением, предложенным исследователями Meta FAIR, — «Самообучающийся оценщик», которое предлагает новую идею решения этой проблемы.
В современную эпоху область обработки естественного языка (NLP) быстро развивается, и большие языковые модели (LLM) могут выполнять сложные языковые задачи с высокой точностью, открывая больше возможностей для взаимодействия человека и компьютера. Однако серьезной проблемой в НЛП является зависимость от человеческих аннотаций для оценки модели.
Данные, созданные человеком, имеют решающее значение для обучения и проверки модели, но сбор этих данных обходится дорого и требует много времени. Более того, поскольку модели продолжают совершенствоваться, может потребоваться обновление ранее собранных аннотаций, что делает их менее полезными для оценки новых моделей. Это приводит к необходимости постоянного сбора новых данных, что создает проблемы для масштаба и устойчивости эффективной оценки моделей.
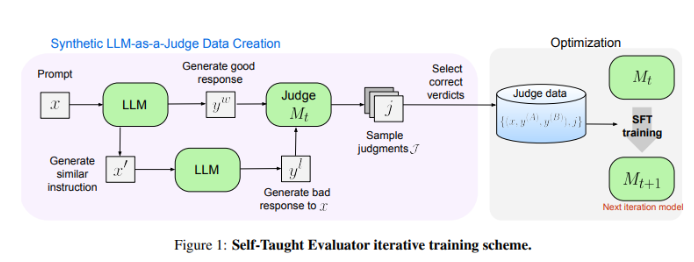
Исследователи Meta FAIR придумали новое решение — «Оценщик-самоучка». Этот подход не требует человеческих аннотаций и обучается на синтетически сгенерированных данных. Сначала исходная модель генерирует контрастирующие синтетические пары предпочтений, а затем модель оценивает эти пары и итеративно улучшает их, используя собственное суждение для повышения производительности в последующих итерациях, что значительно снижает зависимость от аннотаций, созданных человеком.
Исследователи проверили производительность «самообучающегося оценщика» с помощью модели Llama-3-70B-Instruct. Этот метод повышает точность модели в тесте RewardBench с 75,4 до 88,7, что соответствует или даже превосходит производительность моделей, обученных с помощью человеческих аннотаций. После нескольких итераций окончательная модель достигла точности 88,3 при одном выводе и 88,7 при большинстве голосов, продемонстрировав свою высокую стабильность и надежность.
«Самообучающийся оценщик» предоставляет масштабируемое и эффективное решение для оценки моделей НЛП, используя синтетические данные и итеративное самосовершенствование, решая проблемы, связанные с использованием человеческих аннотаций, и продвигая разработку языковых моделей.
Адрес статьи: https://arxiv.org/abs/2408.02666.
«Самообучающийся оценщик» Meta FAIR внес революционные изменения в оценку моделей НЛП, а его эффективные и масштабируемые функции будут эффективно способствовать дальнейшему развитию будущих языковых моделей. Этот результат исследования не только снижает зависимость от данных, аннотированных человеком, но, что более важно, открывает путь к созданию более мощных и надежных моделей НЛП. Мы с нетерпением ждем новых подобных новинок в будущем!