Команда OpenDataLab Шанхайской лаборатории искусственного интеллекта (Шанхайская лаборатория искусственного интеллекта) представила новый интеллектуальный инструмент извлечения данных MinerU на главном форуме WAIC Science Frontier 2024 года. Этот инструмент с открытым исходным кодом призван упростить процесс обработки данных ИИ и помочь исследователям более эффективно извлекать высококачественные данные из огромных документов. MinerU поддерживает различные форматы документов, включая PDF, веб-страницы, epub, mobi и docx и т. д., и конвертирует их в формат Markdown, который легко анализировать. Его основные функциональные модули Magic-PDF и Magic-Doc ориентированы на извлечение PDF-документов и веб-страниц/электронных книг соответственно и используют такие модели, как LayoutLMv3, YOLOv8, UniMERNet и PaddleOCR, для достижения высококачественного извлечения данных, что значительно улучшает качество обработки данных. эффективность обработки.
На главном форуме WAIC Science Frontier 2024 года команда OpenDataLab, работающая над большой модельной базой данных Шанхайской лаборатории искусственного интеллекта (Шанхайская лаборатория искусственного интеллекта), представила новый интеллектуальный инструмент извлечения данных под названием MinerU. Этот инструмент призван упростить процесс обработки данных ИИ и помочь исследователям ИИ извлекать высококачественные данные из огромных документов.
MinerU — это универсальный инструмент с открытым исходным кодом для извлечения данных из документов и веб-страниц, который может конвертировать мультимодальные PDF-документы, включая изображения, таблицы, формулы и т. д., в понятный и простой для анализа формат Markdown. Он также может быстро анализировать и извлекать формальный контент с веб-страниц, содержащих информацию о помехах, например рекламу, и поддерживает пакетное преобразование нескольких форматов, таких как epub, mobi, docx и т. д., в Markdown.
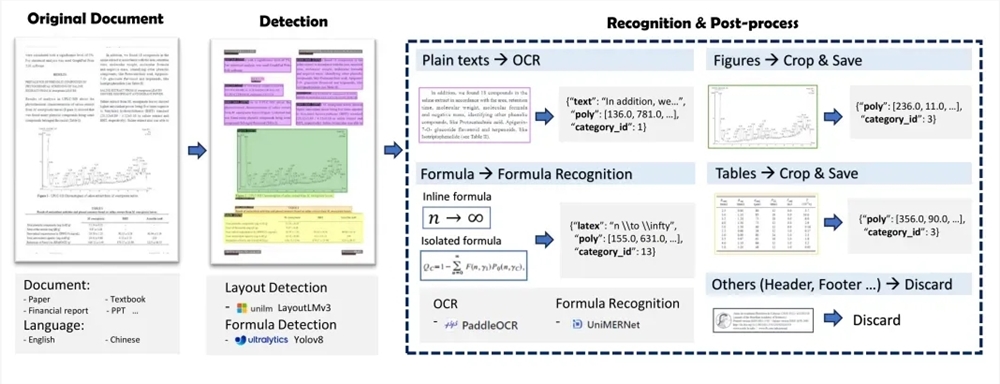
MinerU состоит из двух основных частей: Magic-PDF и Magic-Doc. Magic-PDF фокусируется на извлечении документов PDF и конвертирует PDF в формат Markdown. Он может быстро идентифицировать элементы макета PDF, автоматически удалять нетекстовое содержимое и сохранять структуру и формат исходного документа. Magic-Doc отвечает за извлечение веб-страниц и электронных книг, поддерживает извлечение общей информации веб-страниц, такой как статьи, форумы, музыка, видео и т. д., а также преобразование форматов электронных книг.
На техническом уровне процесс извлечения PDF-документов MinerU включает в себя предварительную обработку классификации PDF-документов, анализ модели, конвейерную обработку и проверку качества результатов извлечения PDF-файлов. Он использует ряд моделей, таких как LayoutLMv3, YOLOv8, UniMERNet и PaddleOCR, для достижения высококачественного извлечения данных документа.
Выпуск MinerU не только предоставляет исследователям искусственного интеллекта мощный инструмент обработки данных, но также способствует дальнейшему обновлению всей системы инструментов цепочки для разработки и применения крупных моделей.
Ссылка на опыт сообщества Magic:
https://modelscope.cn/studios/OpenDataLab/MinerU
Ссылка на открытый исходный код:
https://github.com/opendatalab/MinerU/
Модель MinerU с открытым исходным кодом (PDF-Extract-Kit):
https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit
Открытый исходный код и простота использования MinerU значительно облегчат работу исследователей и разработчиков искусственного интеллекта, повысят эффективность обработки данных в области искусственного интеллекта и обеспечат надежную поддержку разработки больших моделей. Добро пожаловать на ссылку, чтобы испытать и использовать MinerU.