Moore Thread открыла исходный код своей большой модели распознавания звука MooER, которая является первой в отрасли крупной речевой моделью с открытым исходным кодом, основанной на отечественном полнофункциональном обучении и выводе графического процессора, что является важной вехой. MooER поддерживает распознавание китайской и английской речи и фонетический перевод на китайский и английский, демонстрируя мощные возможности многоязычной обработки. Его инновационная трехкомпонентная структура модели (кодировщик, адаптер и декодер) позволяет модели эффективно обрабатывать звук и выполнять последующие задачи. В настоящее время код вывода и модель, обученная на основе 5000 часов данных, находятся в открытом доступе. В будущем код обучения и расширенная модель, обученная на основе 80 000 часов данных, будут открыты, что будет значительно способствовать развитию. аудиотехнологий AI в стране и за рубежом.
MooER показал хорошие результаты в сравнительных тестах нескольких известных аудиосистем с открытым исходным кодом, распознающих большие модели: коэффициент ошибок в китайском слове (CER) составляет всего 4,21%, а коэффициент ошибок в английском слове (WER) - 17,98%, особенно BLEU на китайском языке. -Набор тестов для перевода на английский язык. Оценка достигает 25,2, опережая другие модели с открытым исходным кодом. Модель MooER-80k, обученная на основе данных за 80 000 часов, имеет более высокую производительность: CER и WER снижены до 3,50% и 12,66% соответственно, что демонстрирует большой потенциал. Этот шаг Moore Thread не только демонстрирует сильные стороны отечественных графических процессоров в области искусственного интеллекта, но и придаёт новый импульс развитию глобальной технологии искусственного интеллекта в области аудио. Ожидается, что MooER принесёт ещё больше прорывов в будущем.
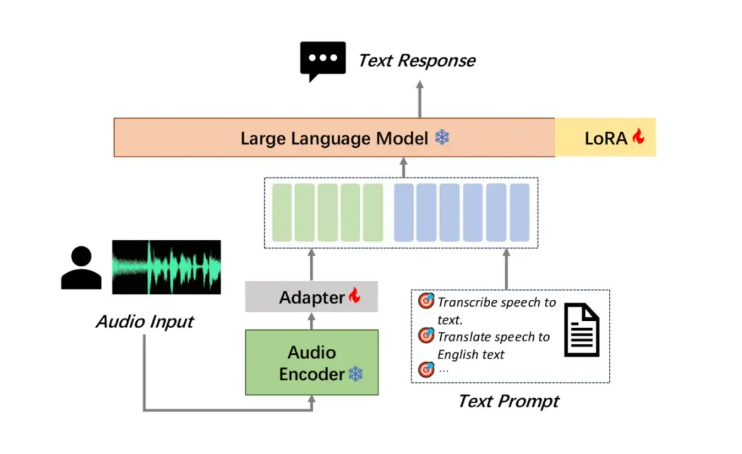
В сравнительных тестах с несколькими известными крупными моделями с открытым исходным кодом MooER-5K показал отличные результаты. В китайском тесте коэффициент ошибок в словах (CER) достиг 4,21%; в английском тесте коэффициент ошибок в словах (WER) составил 17,98%, что лучше или эквивалентно показателям других топ-моделей. Особо стоит отметить, что в тестовом наборе для перевода на китайский и английский язык Covost2zh2en оценка MooER BLEU достигает 25,2, что значительно опережает другие модели с открытым исходным кодом и достигает уровня, сопоставимого с приложениями промышленного уровня.
Что еще более интересно, так это то, что модель MooER-80k, обученная на основе 80 000 часов данных, показывает более высокую производительность. CER на китайском тестовом наборе еще больше упал до 3,50%, а WER на английском тестовом наборе также был оптимизирован до 12,66. %. Показывает огромный потенциал развития.
MooER с открытым исходным кодом от Moore Thread не только демонстрирует возможности применения отечественных графических процессоров в области искусственного интеллекта, но и придаёт новую жизнь развитию глобальной аудиотехнологии искусственного интеллекта. Поскольку все больше обучающих данных и кодов становятся открытыми, отрасль ожидает, что MooER принесет больше прорывов в распознавании речи, переводе и других областях, а также будет способствовать популяризации и инновационному применению технологии аудио AI.
Адрес: https://arxiv.org/pdf/2408.05101
Открытый исходный код MooER отмечает, что отечественные графические процессоры добились значительного прогресса в области крупных моделей искусственного интеллекта, предоставляя ценные ресурсы и платформы для отечественных и зарубежных разработчиков. Ожидается, что MooER сможет сыграть роль в большем количестве сценариев применения в будущем и способствовать постоянным инновациям и развитию технологии аудио AI.