Tencent Youtu Lab и другие учреждения открыли исходный код первой мультимодальной модели большого языка VITA, которая может одновременно обрабатывать видео, изображения, текст и аудио и обеспечивать плавный интерактивный опыт. Появление VITA направлено на то, чтобы восполнить недостатки существующих крупномасштабных языковых моделей обработки китайского диалекта. На основе модели Mixtral8×7B китайский словарный запас расширяется, а двуязычные инструкции точно настраиваются, что позволяет обоим владеть английским языком. и свободно говорит по-китайски. Это знаменует собой значительный прогресс сообщества открытого исходного кода в мультимодальном понимании и взаимодействии.
Недавно исследователи из Tencent Youtu Lab и других учреждений запустили первую мультимодальную модель большого языка VITA с открытым исходным кодом, которая может одновременно обрабатывать видео, изображения, текст и аудио, а ее интерактивный опыт также является первоклассным.
Модель VITA была создана для устранения недостатков крупных языковых моделей при обработке китайских диалектов. Он основан на мощной модели Mixtral8×7B, расширенном китайском словарном запасе и точно настроенных двуязычных инструкциях, что позволяет VITA не только хорошо владеть английским, но и свободно говорить по-китайски.
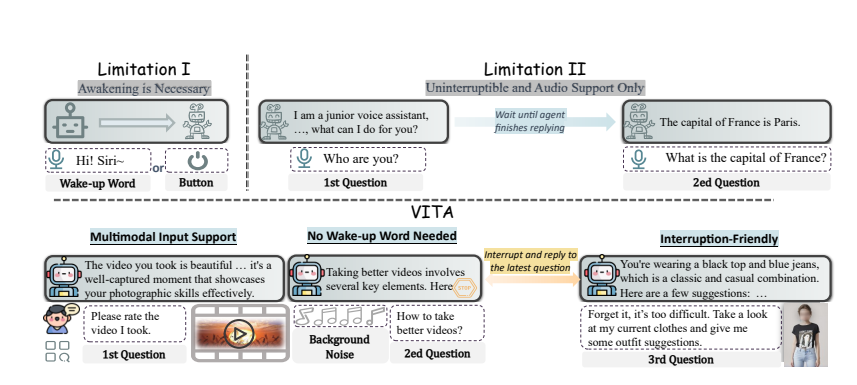
Основные особенности:
Мультимодальное понимание: способность VITA обрабатывать видео, изображения, текст и аудио беспрецедентна среди моделей с открытым исходным кодом.
Естественное взаимодействие: не нужно каждый раз говорить «Эй, ВИТА», он может ответить в любой момент, когда вы говорите, и даже когда вы разговариваете с другими, он может оставаться вежливым и не перебивать по своему желанию.
Пионер открытого исходного кода: VITA — это важный шаг для сообщества открытого исходного кода в мультимодальном понимании и взаимодействии, закладывающий основу для последующих исследований.
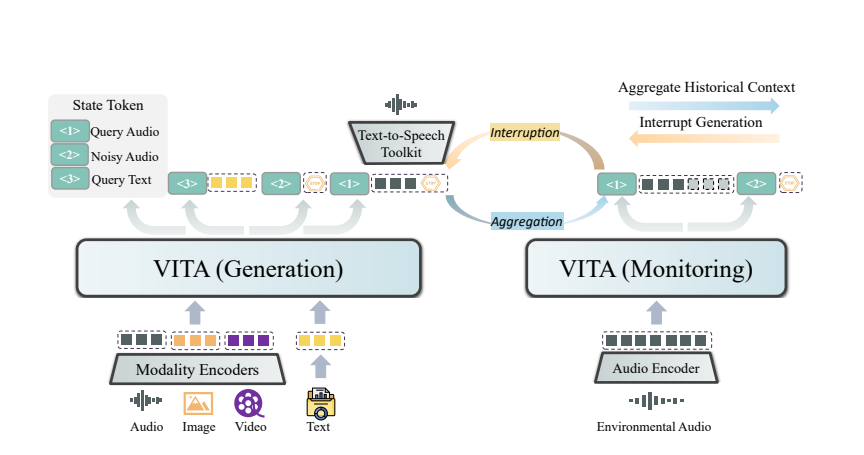
Магия VITA заключается в использовании двойной модели. Одна модель отвечает за генерацию ответов на запросы пользователей, а другая модель постоянно отслеживает входные данные окружающей среды, чтобы гарантировать точность и своевременность каждого взаимодействия.
VITA может не только общаться, но и выступать в качестве собеседника во время тренировок и даже давать советы во время путешествий. Он также может отвечать на вопросы на основе предоставленных вами изображений или видеоконтента, демонстрируя свою огромную практичность.
Хотя VITA продемонстрировала большой потенциал, она все еще развивается с точки зрения эмоционального синтеза речи и мультимодальной поддержки. Исследователи планируют позволить следующему поколению VITA генерировать высококачественный звук из видео и текстового ввода и даже изучить возможность одновременной генерации высококачественного аудио и видео.
Открытый исходный код модели VITA — это не только техническая победа, но и глубокая инновация в способе интеллектуального взаимодействия. По мере углубления исследований у нас есть основания полагать, что VITA принесет нам более разумный и гуманный интерактивный опыт.
Адрес статьи: https://arxiv.org/pdf/2408.05211.
Открытый исходный код VITA открывает новое направление для разработки мультимодальных больших языковых моделей. Его мощные функции и удобный интерактивный опыт указывают на то, что взаимодействие человека и компьютера в будущем станет более интеллектуальным и гуманным. Мы с нетерпением ждем, когда VITA совершит еще больший прорыв в будущем и принесет больше удобства в жизнь людей.