Большие языковые модели (LLM) сталкиваются с проблемами при понимании длинного текста, а размер контекстного окна ограничивает их возможности обработки. Чтобы решить эту проблему, исследователи разработали эталонный тест LooGLE для оценки способности LLM понимать длительный контекст. LooGLE содержит 776 сверхдлинных документов (в среднем 19,3 тыс. слов), выпущенных после 2022 года, и 6448 тестовых экземпляров, охватывающих различные области, с целью более всесторонней оценки способности модели понимать и обрабатывать длинные тексты. Этот тест оценивает эффективность существующих LLM и предоставляет ценную информацию для разработки будущих моделей.
В области обработки естественного языка понимание длительного контекста всегда было проблемой. Хотя большие языковые модели (LLM) хорошо справляются с различными языковыми задачами, они часто ограничены при обработке текста, размер которого превышает размер их контекстного окна. Чтобы преодолеть это ограничение, исследователи усердно работали над улучшением способности студентов LLM понимать длинные тексты, что важно не только для академических исследований, но и для сценариев реального применения, таких как понимание предметных знаний, длинные тексты. генерация диалогов и длинных историй или генерация кода и т. д. также имеют решающее значение.
В этом исследовании авторы предлагают новый эталонный тест - LooGLE (Long Context Generic Language Evaluation), который специально разработан для оценки способности LLM понимать длинный контекст. Этот тест содержит 776 сверхдлинных документов после 2022 года, каждый документ содержит в среднем 19,3 тыс. слов и имеет 6448 тестовых экземпляров, охватывающих различные области, такие как наука, история, спорт, политика, искусство, события, развлечения и т. д.
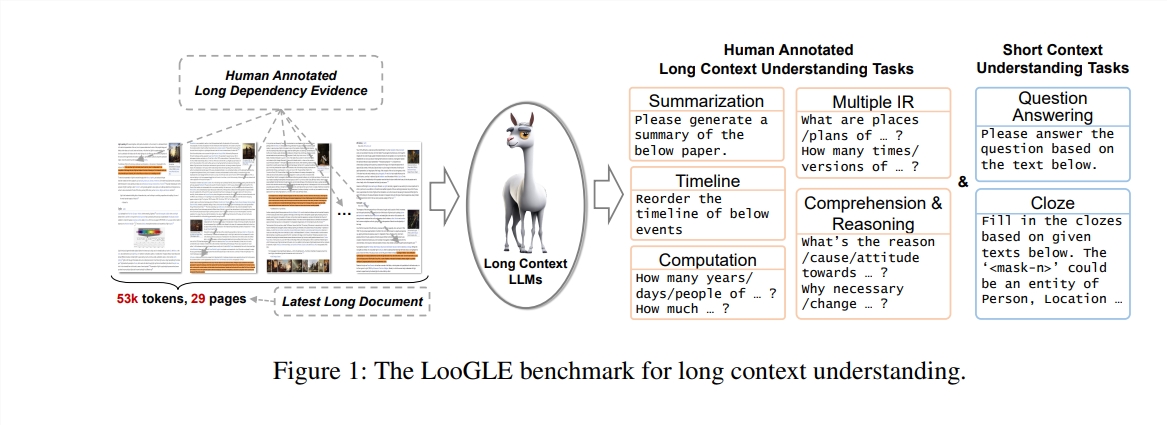
Особенности LooGLE
Сверхдлинные реальные документы: длина документов в ooGLE намного превышает размер контекстного окна LLM, что требует от модели способности запоминать и понимать более длинный текст.
Задачи с длинными и короткими зависимостями, разработанные вручную: эталонный тест содержит 7 основных задач, включая задачи с короткими и длинными зависимостями, для оценки способности LLM понимать содержание длинных и коротких зависимостей.
Относительно новые документы: все документы были выпущены после 2022 года, что гарантирует, что большинство современных LLM не знакомились с этими документами во время предварительного обучения, что позволяет более точно оценить их возможности контекстного обучения.
Общие междоменные данные: контрольные данные поступают из популярных документов с открытым исходным кодом, таких как документы arXiv, статьи в Википедии, сценарии фильмов и телепередач и т. д.
Исследователи провели комплексную оценку восьми современных программ LLM, и результаты выявили следующие ключевые выводы:
Коммерческая модель превосходит модель с открытым исходным кодом по производительности.
LLM хорошо справляются с задачами с кратковременной зависимостью, но создают проблемы с более сложными задачами с длительной зависимостью.
Методы, основанные на изучении контекста и цепочках мышления, обеспечивают лишь ограниченные улучшения в понимании длительного контекста.
Методы, основанные на поиске, демонстрируют значительные преимущества при ответе на короткие вопросы, в то время как стратегии по увеличению длины контекстного окна за счет оптимизированной архитектуры Transformer или позиционного кодирования имеют ограниченное влияние на понимание длинного контекста.
Тест LooGLE не только предоставляет систематическую и комплексную схему оценки LLM с длинным контекстом, но также дает рекомендации для будущей разработки моделей с возможностями «истинного понимания длительного контекста». Весь оценочный код опубликован на GitHub для справки и использования исследовательским сообществом.
Адрес статьи: https://arxiv.org/pdf/2311.04939.
Адрес кода: https://github.com/bigai-nlco/LooGLE
Тест LooGLE представляет собой важный инструмент для оценки и улучшения возможностей LLM по пониманию длинного текста, а результаты его исследований имеют большое значение для содействия развитию области обработки естественного языка. Предложенные исследователями направления улучшения заслуживают внимания. Я считаю, что в будущем появятся все более мощные LLM, позволяющие лучше справляться с длинными текстами.