Apple и Meta AI совместно запустили новую технологию под названием LazyLLM, которая призвана значительно повысить эффективность больших языковых моделей (LLM) при обработке длинных текстовых рассуждений. Когда текущий LLM обрабатывает длинные подсказки, вычислительная сложность механизма внимания увеличивается пропорционально квадрату количества жетонов, что приводит к низкой скорости, особенно на этапе предварительной зарядки. LazyLLM динамически выбирает важные токены для расчета, эффективно сокращая объем вычислений, и вводит механизм Aux Cache для эффективного восстановления удаленных токенов, что значительно увеличивает скорость и обеспечивает точность.
Недавно исследовательская группа Apple и исследователи Meta AI совместно запустили новую технологию под названием LazyLLM, которая повышает эффективность больших языковых моделей (LLM) при рассуждении длинных текстов.
Как мы все знаем, нынешний LLM часто сталкивается с проблемами низкой скорости при обработке длинных запросов, особенно на этапе предварительной зарядки. Это происходит главным образом потому, что вычислительная сложность современных архитектур-трансформеров при вычислении внимания растет квадратично с количеством токенов в подсказке. Поэтому при использовании модели Llama2 время вычисления первого токена часто в 21 раз превышает время последующих шагов декодирования, что составляет 23% времени генерации.
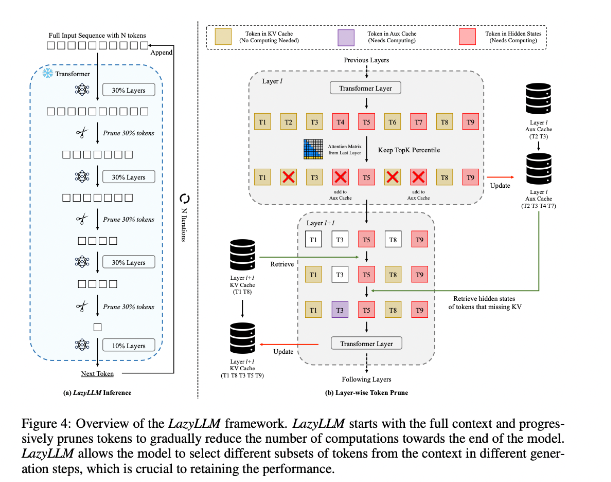
Чтобы улучшить эту ситуацию, исследователи предложили LazyLLM — новый метод ускорения вывода LLM за счет динамического выбора метода расчета важных токенов. Суть LazyLLM заключается в том, что он оценивает важность каждого токена на основе оценки внимания предыдущего уровня, тем самым постепенно уменьшая объем вычислений. В отличие от постоянного сжатия, LazyLLM может восстанавливать сокращенные токены, когда это необходимо для обеспечения точности модели. Кроме того, LazyLLM представляет механизм под названием Aux Cache, который может хранить неявное состояние сокращенных токенов для эффективного восстановления этих токенов и предотвращения снижения производительности.
LazyLLM отличается скоростью вывода, особенно на этапах предварительного заполнения и декодирования. Три основных преимущества этого метода заключаются в том, что он совместим с любым LLM на основе преобразователя, не требует переобучения модели во время реализации и очень эффективно справляется с различными языковыми задачами. Стратегия динамического сокращения LazyLLM позволяет значительно сократить объем вычислений, сохраняя при этом наиболее важные токены, тем самым увеличивая скорость генерации.
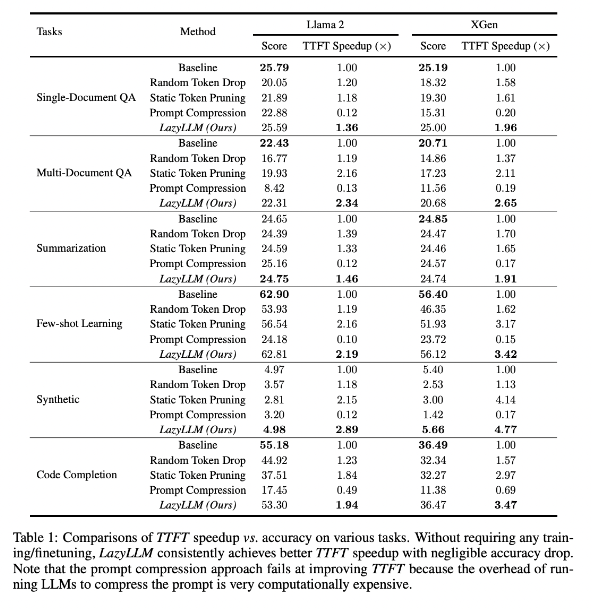
Результаты исследований показывают, что LazyLLM хорошо справляется с несколькими языковыми задачами: скорость TTFT увеличилась в 2,89 раза (для Llama2) и в 4,77 раза (для XGen), а точность почти такая же, как у базового уровня. Будь то ответы на вопросы, создание сводки или задачи завершения кода, LazyLLM может обеспечить более высокую скорость генерации и хороший баланс между производительностью и скоростью. Его прогрессивная стратегия сокращения в сочетании с послойным анализом закладывает основу успеха LazyLLM.
Адрес статьи: https://arxiv.org/abs/2407.14057.
Основные моменты:
LazyLLM ускоряет процесс рассуждения LLM за счет динамического выбора важных токенов, особенно в сценариях с длинным текстом.
Эта технология позволяет значительно улучшить скорость вывода, а скорость TTFT можно увеличить до 4,77 раз, сохраняя при этом высокую точность.
LazyLLM не требует внесения изменений в существующие модели, совместим с любым LLM на основе конвертера и прост в реализации.
В целом, появление LazyLLM предлагает новые идеи и эффективные решения для решения проблемы эффективности рассуждений длинных текстов LLM. Его превосходные характеристики по скорости и точности указывают на то, что он будет играть важную роль в будущих приложениях для больших моделей. Эта технология имеет широкие перспективы применения и заслуживает дальнейшего развития и применения.