Apple совместно с Вашингтонским университетом и другими учреждениями выпустила мощную языковую модель под названием DCLM с открытым исходным кодом, с размером параметров 700 миллионов и ошеломляющим объемом обучающих данных, достигающим 2,5 триллионов токенов данных. DCLM — это не только эффективная языковая модель, но, что более важно, он предоставляет инструмент под названием «Конкуренция наборов данных» (DataComp) для оптимизации набора данных языковой модели. Это нововведение не только повышает производительность модели, но также предоставляет новые методы и стандарты исследования языковых моделей, что заслуживает внимания.
Недавно команда Apple по искусственному интеллекту сотрудничала со многими учреждениями, такими как Вашингтонский университет, для запуска языковой модели с открытым исходным кодом под названием DCLM. Эта модель имеет 700 миллионов параметров и использует до 2,5 триллионов токенов данных во время обучения, чтобы помочь нам лучше понимать и генерировать язык.
Итак, что такое языковая модель? Проще говоря, это программа, которая может анализировать и генерировать язык, помогая нам выполнять различные задачи, такие как перевод, генерация текста и анализ настроений. Чтобы эти модели работали лучше, нам нужны качественные наборы данных. Однако получение и систематизация этих данных — непростая задача, поскольку нам необходимо отфильтровывать нерелевантный или вредный контент и удалять дублирующую информацию.
Чтобы решить эту проблему, исследовательская группа Apple запустила DataComp for Language Models (DCLM), инструмент оптимизации набора данных для языковых моделей. Недавно они открыли исходный код модели DCIM и набора данных на платформе Hugging Face. Версии с открытым исходным кодом включают DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 и dclm-baseline-1.0-parquet. С помощью этой платформы исследователи могут проводить большое количество экспериментов. и найдите лучшее решение. Эффективные стратегии обработки данных.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
Основное преимущество DCLM — структурированный рабочий процесс. Исследователи могут выбирать модели разного размера в зависимости от своих потребностей (от 412 до 700 миллионов параметров), а также могут экспериментировать с различными методами курирования данных, такими как дедупликация и фильтрация. Благодаря этим систематическим экспериментам исследователи могут четко оценить качество различных наборов данных. Это не только закладывает основу для будущих исследований, но и помогает нам понять, как повысить производительность модели за счет улучшения набора данных.
Например, используя набор контрольных данных, созданный DCLM, исследовательская группа обучила языковую модель с 700 миллионами параметров и достигла точности 5 шагов в тесте MMLU. Это улучшение на 6,6 по сравнению с предыдущим! самый высокий уровень процентных пунктов и использует на 40% меньше вычислительных ресурсов. Производительность базовой модели DCLM также сопоставима с Mistral-7B-v0.3 и Llama38B, которые требуют гораздо больше вычислительных ресурсов.
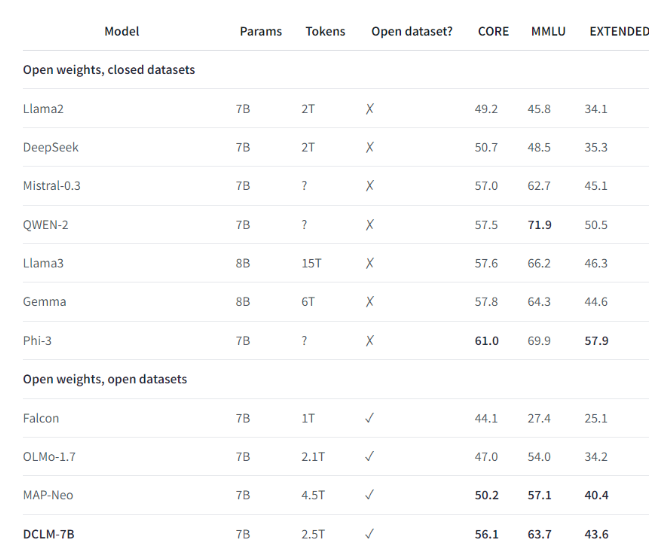
Запуск DCLM обеспечивает новый стандарт для исследований языковых моделей, помогая ученым систематически улучшать производительность модели при одновременном сокращении необходимых вычислительных ресурсов.
Основные моменты:
1️⃣ Apple AI сотрудничала с несколькими учреждениями для запуска DCLM, создав мощную языковую модель с открытым исходным кодом.
2️⃣ DCLM предоставляет стандартизированные инструменты оптимизации набора данных, которые помогают исследователям проводить эффективные эксперименты.
3️⃣ Новая модель демонстрирует значительный прогресс в важных тестах, одновременно снижая требования к вычислительным ресурсам.
В целом, открытый исходный код DCLM вдохнул новую жизнь в область исследования языковых моделей, а его эффективные инструменты оптимизации моделей и наборов данных, как ожидается, будут способствовать более быстрому развитию в этой области и рождению более мощных и эффективных языковых моделей. Мы ожидаем, что в будущем DCLM принесет еще более удивительные результаты исследований.