Команда Alibaba Tongyi Qianwen выпустила серию моделей с открытым исходным кодом Qwen2. Эта серия включает в себя 5 размеров моделей для предварительной подготовки и точной настройки инструкций. Количество параметров и производительность были значительно улучшены по сравнению с предыдущим поколением Qwen1.5. Серия Qwen2 также совершила крупный прорыв в многоязычных возможностях, поддерживая 27 языков, помимо английского и китайского. С точки зрения понимания естественного языка, кодирования, математических возможностей и т. д., большая модель (более 70B параметров) работает хорошо, особенно модель Qwen2-72B, которая превосходит предыдущее поколение по производительности и количеству параметров. Этот выпуск знаменует новую высоту в технологии искусственного интеллекта, предоставляя более широкие возможности для глобального применения и коммерциализации ИИ.
Сегодня рано утром команда Alibaba Tongyi Qianwen выпустила серию моделей с открытым исходным кодом Qwen2. Эта серия моделей включает в себя 5 размеров предварительно обученных и точно настроенных моделей: Qwen2-0,5B, Qwen2-1,5B, Qwen2-7B, Qwen2-57B-A14B и Qwen2-72B. Ключевая информация показывает, что количество параметров и производительность этих моделей были значительно улучшены по сравнению с предыдущим поколением Qwen1.5.
Для многоязычных возможностей модели в серии Qwen2 было вложено много усилий в увеличение количества и качества набора данных, охватывающего 27 других языков, кроме английского и китайского. После сравнительного тестирования большая модель (70B + параметры) показала хорошие результаты в понимании естественного языка, кодировании, математических возможностях и т. д. Модель Qwen2-72B превзошла предыдущее поколение по производительности и количеству параметров.
Модель Qwen2 не только демонстрирует сильные возможности в оценке базовой языковой модели, но также достигает впечатляющих результатов в оценке модели настройки инструкций. Его многоязычные возможности хорошо работают в тестах производительности, таких как M-MMLU и MGSM, демонстрируя мощный потенциал модели настройки инструкций Qwen2.
Модели серии Qwen2, выпущенные на этот раз, знаменуют новую высоту технологий искусственного интеллекта, предоставляя более широкие возможности для глобальных приложений искусственного интеллекта и коммерциализации. Заглядывая в будущее, Qwen2 будет и дальше расширять масштаб модели и мультимодальные возможности, чтобы ускорить развитие области искусственного интеллекта с открытым исходным кодом.
Информация о моделиСерия Qwen2 включает 5 типоразмеров базовых и настраиваемых моделей, включая Qwen2-0,5B, Qwen2-1,5B, Qwen2-7B, Qwen2-57B-A14B и Qwen2-72B. Мы объясняем ключевую информацию для каждой модели в таблице ниже:
Модель Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# Параметр 049 миллионов 154 миллиона 707B57.41B72.71B# Параметр Non-Emb 035 миллионов 131B598 миллионов 5632 миллионов 7021B Обеспечение качества действительно очень действительно истинное встроенное связывание true true false false false false длина контекста 32 тысячи 32 тысячи 128 тысяч 64 тысячи 128 тысячВ частности, в Qwen1.5 только Qwen1.5-32B и Qwen1.5-110B использовали внимание к групповым запросам (GQA). На этот раз мы применили GQA для всех размеров моделей, чтобы они могли воспользоваться преимуществами более высокой скорости и меньшего объема памяти при выводе моделей. Для небольших моделей мы предпочитаем применять связывающие вложения, поскольку на большие разреженные вложения приходится большая часть общих параметров модели.
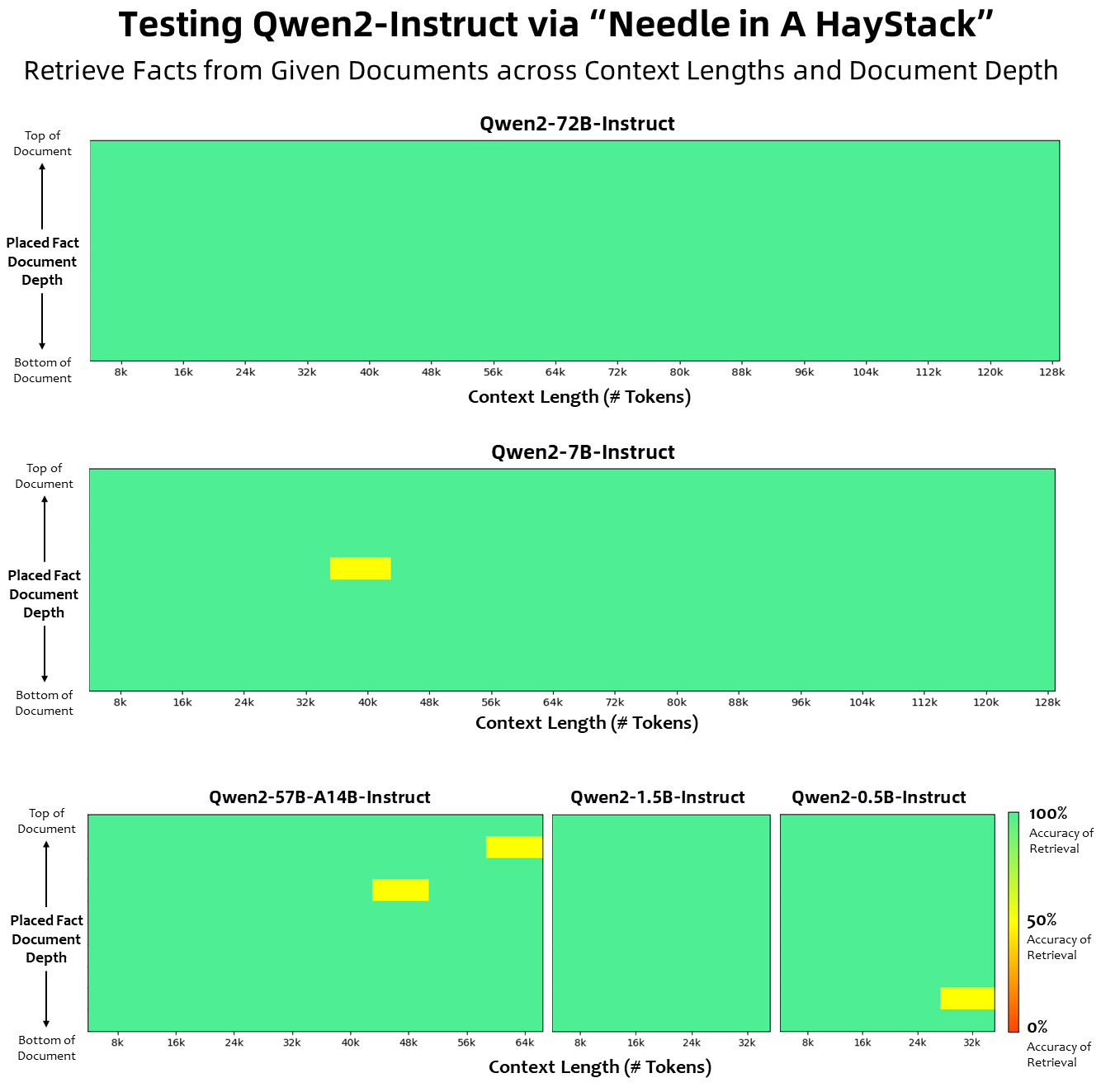
Что касается длины контекста, все модели базового языка были предварительно обучены на данных о длине контекста из 32 тысяч токенов, и мы наблюдали удовлетворительные возможности экстраполяции до 128 тысяч при оценке PPL. Однако для моделей, настроенных на инструкции, нас не удовлетворяет только оценка PPL, нам нужно, чтобы модель могла правильно понимать длинный контекст и выполнять задачу. В таблице мы перечисляем возможности модели настройки инструкций по длине контекста, оцененные путем оценки задачи Needlein a Haystack. Стоит отметить, что модели Qwen2-7B-Instruct и Qwen2-72B-Instruct, дополненные YARN, демонстрируют впечатляющие возможности и могут обрабатывать контексты длиной до 128 КБ.
Мы приложили значительные усилия для увеличения количества и качества наборов данных для предварительного обучения и обучения, охватывающих несколько языков, помимо английского и китайского, чтобы расширить его многоязычные возможности. Хотя большие языковые модели обладают свойственной способностью обобщаться на другие языки, мы явно подчеркиваем включение в наше обучение еще 27 языков:
Региональные языки Западноевропейский немецкий, французский, испанский, португальский, итальянский, голландский Восточно- и центральноевропейский русский, чешский, польский ближневосточный арабский, персидский, иврит, турецкий восточноазиатский японский, корейский юго-восточноазиатский вьетнамский, тайский, индонезийский, малайский, Лаосский, бирманский, кебуанский, кхмерский, тагальский южноазиатский хинди, бенгальский, урдуКроме того, мы прилагаем значительные усилия для решения проблем перекодирования, которые часто возникают при многоязычных оценках. Таким образом, способность нашей модели справляться с этим явлением значительно улучшается. Оценки с использованием сигналов, которые обычно вызывают межъязыковое переключение кода, подтвердили значительное снижение связанных с этим проблем.
ПроизводительностьРезультаты сравнительных испытаний показывают, что производительность крупномасштабной модели (70B+ параметров) значительно улучшилась по сравнению с Qwen1.5. В основе этого испытания лежала крупномасштабная модель Qwen2-72B. Что касается базовых языковых моделей, мы сравнили производительность Qwen2-72B и лучших на данный момент открытых моделей с точки зрения понимания естественного языка, приобретения знаний, возможностей программирования, математических возможностей, многоязычных возможностей и других возможностей. Благодаря тщательно отобранным наборам данных и оптимизированным методам обучения Qwen2-72B превосходит ведущие модели, такие как Llama-3-70B, и даже превосходит Qwen1.5 предыдущего поколения — с меньшим количеством параметров 110B.
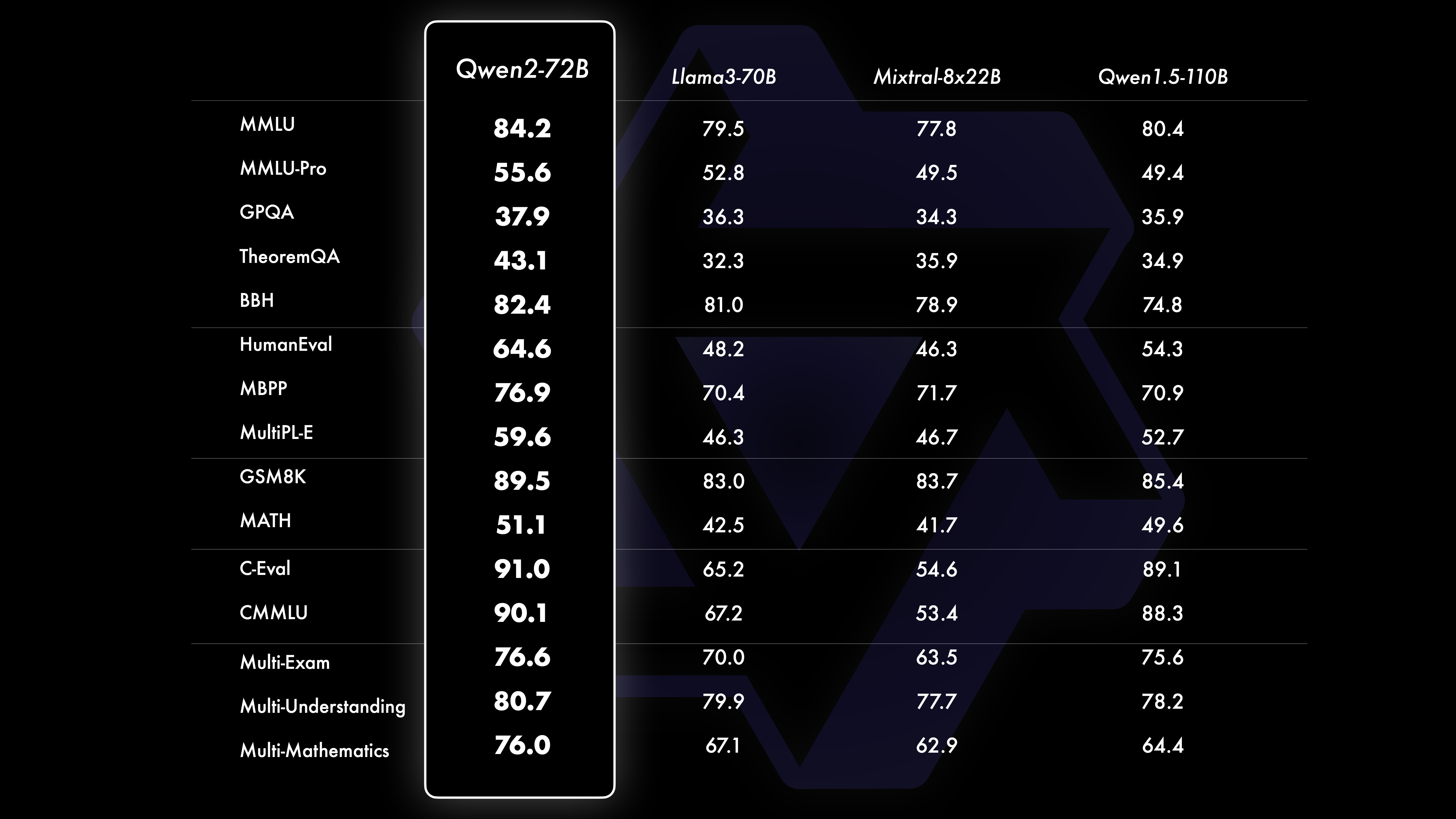
После обширной крупномасштабной предварительной подготовки мы проводим посттренинг, чтобы еще больше повысить интеллект Квена и приблизить его к человеку. Этот процесс еще больше улучшает возможности модели в таких областях, как кодирование, математика, рассуждение, следование инструкциям и понимание нескольких языков. Более того, результат модели согласуется с человеческими ценностями, гарантируя, что она полезна, честна и безвредна. Наш этап после обучения разработан с учетом принципов масштабируемого обучения и минимального вмешательства человека. В частности, мы изучаем, как получить высококачественные, надежные, разнообразные и творческие презентационные данные и данные о предпочтениях с помощью различных стратегий автоматического выравнивания, таких как выборка отклонения для математики, обратная связь при выполнении для кодирования и следования инструкциям, а также обратный перевод для творческого письма. ., масштабируемый контроль ролевых игр и многое другое. Что касается обучения, мы используем комбинацию контролируемой тонкой настройки, обучения по модели вознаграждения и онлайн-обучения DPO. Мы также используем новый онлайн-оптимизатор слияний, чтобы минимизировать налоги на согласование. Эти совместные усилия значительно улучшают возможности и интеллект наших моделей, как показано в таблице ниже.
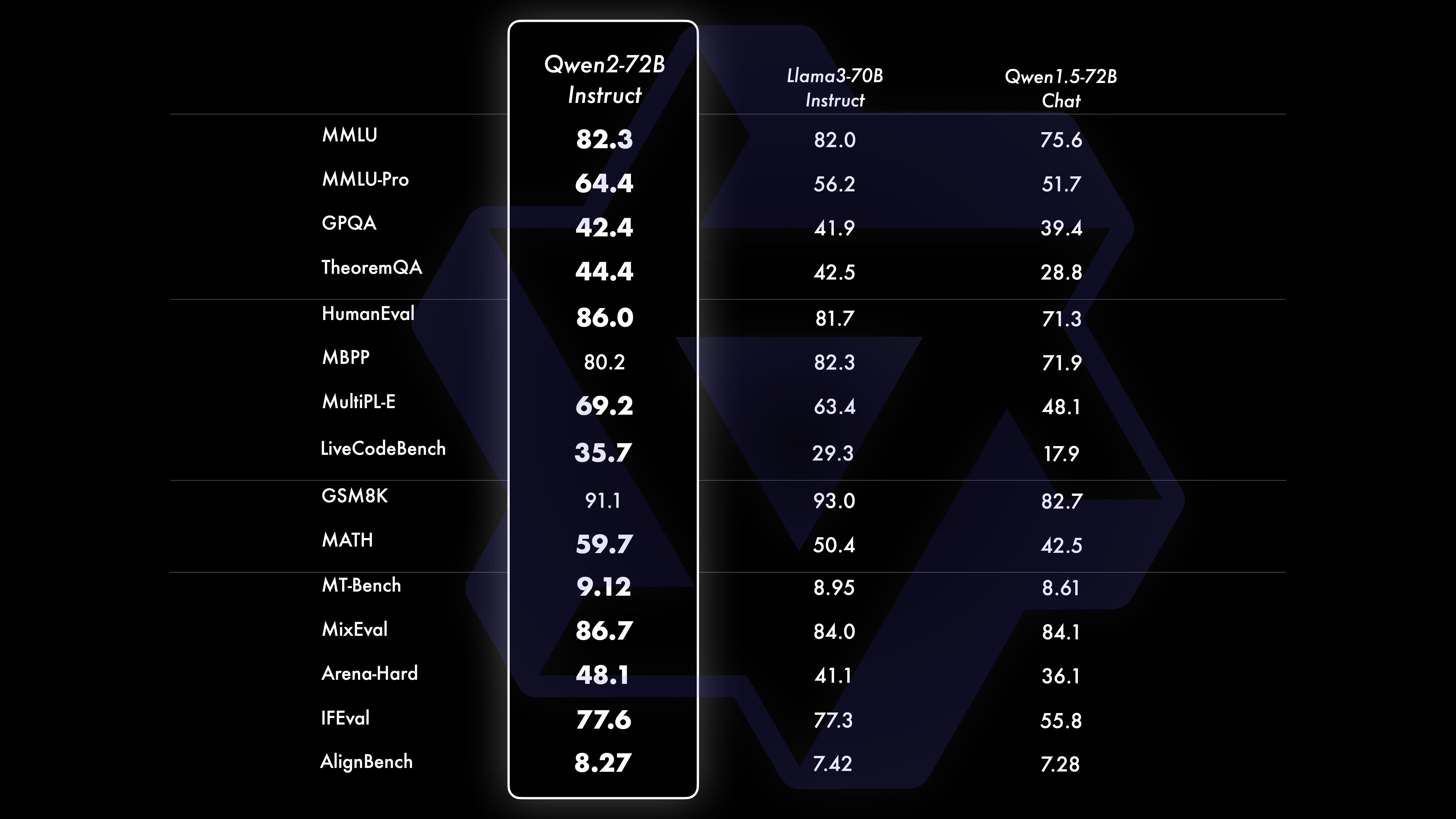
Мы провели комплексную оценку Qwen2-72B-Instruct, охватив 16 тестов в различных областях. Qwen2-72B-Instruct обеспечивает баланс между улучшением способностей и соответствием человеческим ценностям. В частности, Qwen2-72B-Instruct значительно превосходит Qwen1.5-72B-Chat во всех тестах, а также достигает конкурентоспособной производительности по сравнению с Llama-3-70B-Instruct.
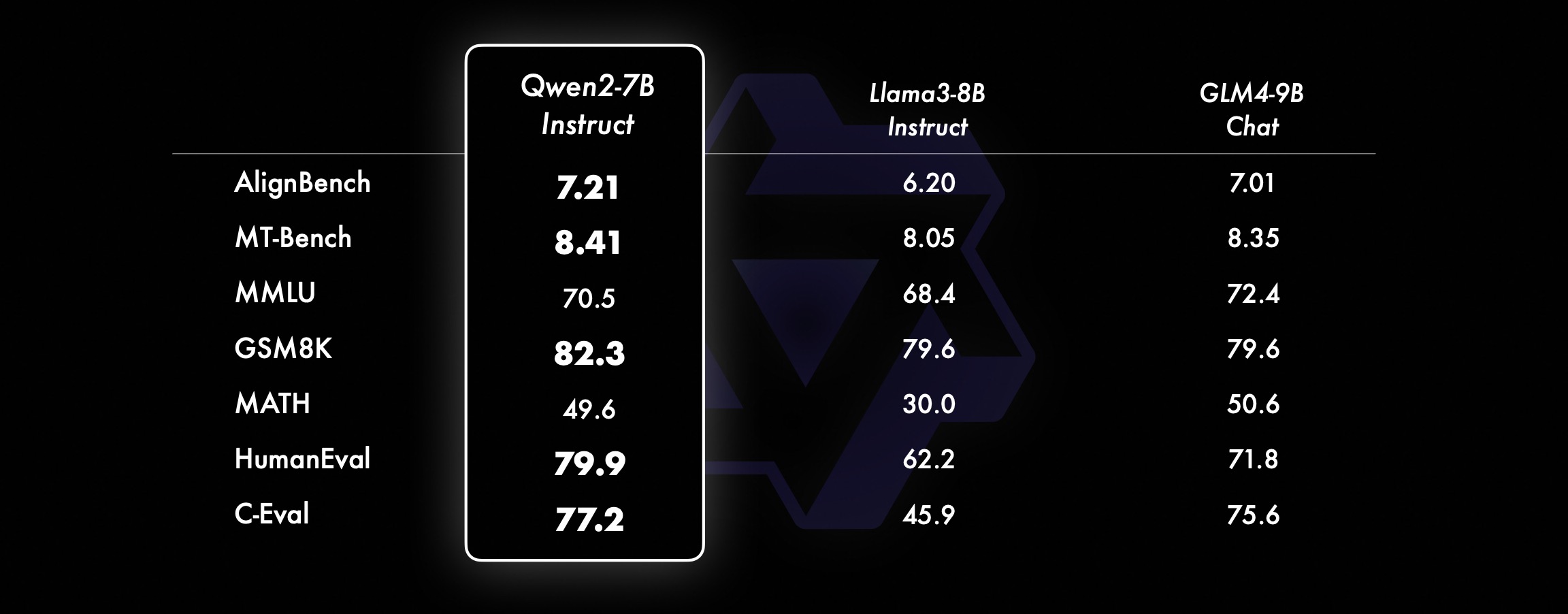
На моделях меньшего размера наши модели Qwen2 также превосходят аналогичные и даже более крупные модели SOTA. По сравнению с только что выпущенной моделью SOTA, Qwen2-7B-Instruct по-прежнему демонстрирует преимущества в различных тестах производительности, особенно в показателях кодирования и китайских индикаторах.
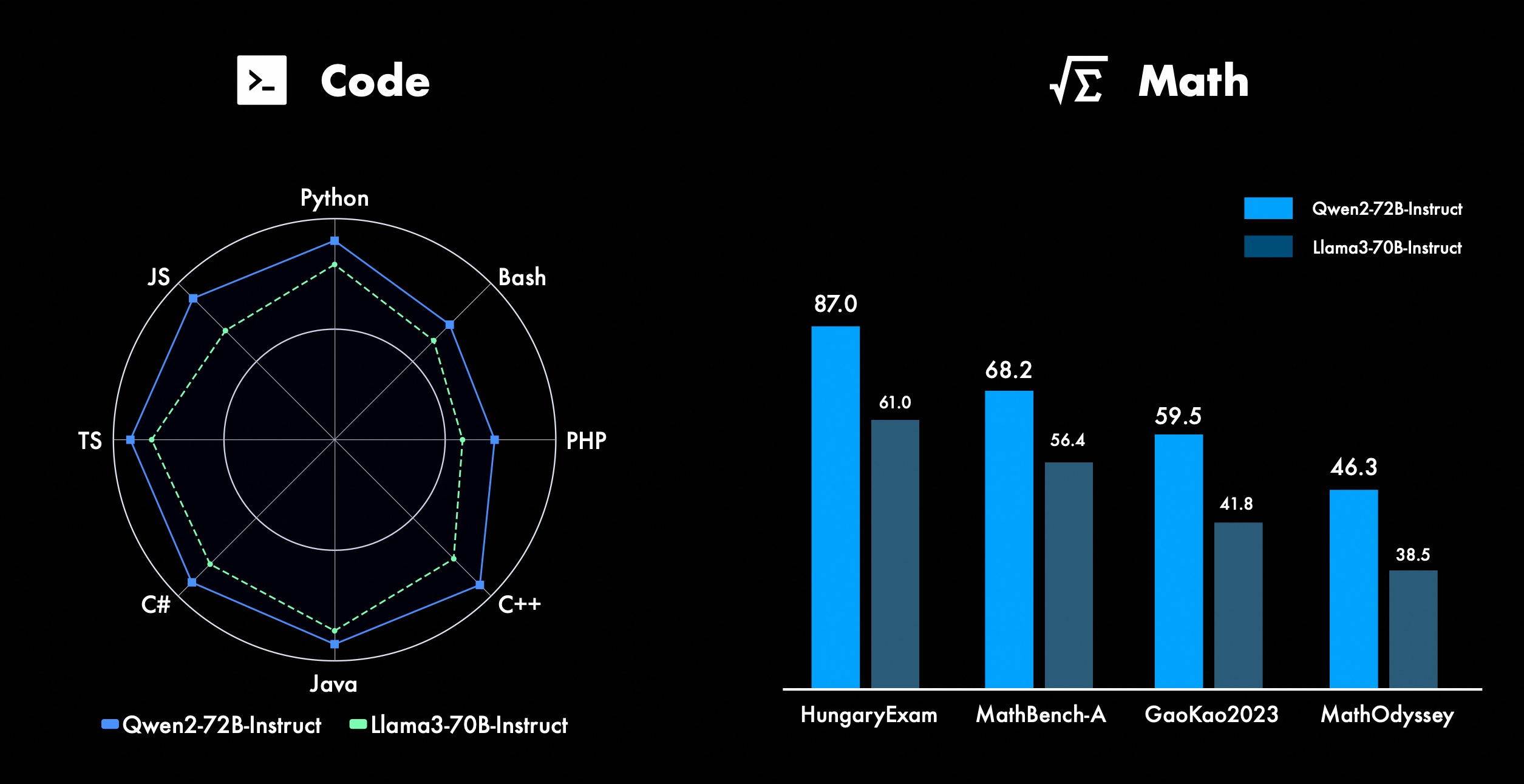
Мы постоянно работаем над улучшением расширенных функций Qwen, особенно в области кодирования и математики. Что касается кодирования, мы успешно интегрировали опыт обучения кодированию и данные CodeQwen1.5, в результате чего Qwen2-72B-Instruct добился значительных улучшений в различных языках программирования. В области математики Qwen2-72B-Instruct демонстрирует расширенные возможности решения математических задач за счет использования обширного и высококачественного набора данных.
В Qwen2 все модели настройки инструкций обучаются на контекстах длиной 32 КБ и экстраполируются на более длинные контексты с использованием таких методов, как YARN или Dual Chunk Attention.
На рисунке ниже показаны результаты наших тестов на Needle in a Haystack. Стоит отметить, что Qwen2-72B-Instruct отлично справляется с задачей извлечения информации в контексте 128k. В сочетании с присущей ему высокой производительностью его можно использовать, когда ресурсов достаточно. В этом случае он становится лучшим выбором для обработки длинных текстовых задач.
Кроме того, стоит отметить впечатляющие возможности других моделей серии: Qwen2-7B-Instruct почти идеально справляется с контекстами до 128 КБ, Qwen2-57B-A14B-Instruct — с контекстами до 64 КБ, а серия The Two модели меньшего размера поддерживают 32 тыс. контекстов.
В дополнение к модели длинного контекста мы открыли прокси-решение с открытым исходным кодом для эффективной обработки документов, содержащих до 1 миллиона тегов. Более подробную информацию можно найти в нашем специальном сообщении в блоге на эту тему.
В таблице ниже показана доля вредоносных ответов, полученных с помощью большой модели для четырех категорий многоязычных небезопасных запросов (незаконная деятельность, мошенничество, порнография, насилие в частной жизни). Тестовые данные поступают из Jailbreak и переводятся на несколько языков для оценки. Мы обнаружили, что Llama-3 неэффективно обрабатывает многоязычные сигналы и поэтому не включили ее в сравнение. С помощью теста значимости (P_value) мы обнаружили, что показатели безопасности модели Qwen2-72B-Instruct эквивалентны показателям GPT-4 и значительно выше, чем у модели Mistral-8x22B.
Язык Незаконная деятельность Мошенничество Порнография Неприкосновенность частной жизни Насилие GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Китайский0%13%0 %0%17%0%43%47%53%0%10%0%Английский0%7%0%0%23% 0%37%67%63%0%27%3%Дебиторская задолженность0%13%0% 0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%Франция0%3%0% 3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%точка0%7%0%3% 7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4% 11%0%22%26%22%0%0%0%средний0%8%0% 3%11%2%27%39%31%3%16%2% используют Qwen2 для разработкиВ настоящее время все модели выпущены в Hugging Face и ModelScope. Вы можете посетить карточку модели, чтобы просмотреть подробные методы использования и узнать больше о характеристиках, производительности и другой информации о каждой модели.
В течение долгого времени многие друзья поддерживали разработку Qwen, включая тонкую настройку (Axolotl, Llama-Factory, Firefly, Swift, XTuner), количественную оценку (AutoGPTQ, AutoAWQ, Neural Compressor), развертывание (vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), платформа API (Together, Fireworks, OpenRouter), локальный запуск (MLX, Llama.cpp, Ollama, LM Studio), агент и платформа RAG (LlamaIndex, CrewAI, OpenDevin), оценка (LMSys, OpenCompass, Open LLM Leaderboard), обучение моделей (Dolphin, Openbuddy) и т. д. Информацию о том, как использовать Qwen2 со сторонними платформами, см. в соответствующей документации, а также в нашей официальной документации.

В создание Qwen внесли свой вклад множество команд и отдельных лиц, о которых мы не упомянули. Мы искренне ценим их поддержку и надеемся, что наше сотрудничество будет способствовать исследованиям и разработкам в сообществе искусственного интеллекта с открытым исходным кодом.
лицензияНа этот раз мы меняем разрешение модели на другое. Qwen2-72B и его модель настройки инструкций по-прежнему используют исходную лицензию Qianwen, в то время как все остальные модели, включая Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B и Qwen2-57B-A14B, перешли на Apache2.0! Мы считаем, что что дальнейшее открытие нашей модели для сообщества может ускорить применение и коммерциализацию Qwen2 по всему миру.
Что будет дальше с Qwen2?Мы обучаем более крупную модель Qwen2 для дальнейшего изучения расширений модели, а также наших последних расширений данных. Кроме того, мы расширяем языковую модель Qwen2, делая ее мультимодальной, способной понимать визуальную и аудиоинформацию. В ближайшем будущем мы продолжим открывать новые модели с открытым исходным кодом для ускорения искусственного интеллекта с открытым исходным кодом. Следите за обновлениями!
ЦитироватьСкоро мы выпустим технический отчет по Qwen2. Цитаты приветствуются!
@article{qwen2, Приложение «Оценка базовой языковой модели»Оценка базовых моделей в основном фокусируется на характеристиках моделей, таких как понимание естественного языка, ответы на общие вопросы, кодирование, математика, научные знания, рассуждения и многоязычные возможности.
Оцениваемые наборы данных включают в себя:
Задания по английскому: MMLU (5 раз), MMLU-Pro (5 раз), GPQA (5 раз), теорема QA (5 раз), BBH (3 раза), HellaSwag (10 раз), Winogrande (5 раз), TruthfulQA ( 0 раз), АРК-С (25 раз)
Задачи кодирования: EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
Задачи по математике: GSM8K (4 раза), MATH (4 раза)
Китайские задачи: C-Eval (5-кадр), CMMLU (5-кадр)
Многоязычные задания: несколько экзаменов (M3Exam 5 раз, IndoMMLU 3 раза, ruMMLU 5 раз, mmMLU 5 раз), множественное понимание (BELEBELE 5 раз, XCOPA 5 раз, XWinograd 5 раз, XStoryCloze 0 раз, PAWS-X 5 раз) , множественная математика (MGSM 8 раз), множественные переводы (Флорес-1015 раз)
Набор данных производительности Qwen2-72B DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BAArchitectureMinistry of EducationDenseDenseDenseDense#Activated параметры 21B39B70B72B110B72B#Parameters 236B140B70B72 B110B72B Английский Морман ·Lu 78.577.879.577.580.484.2MMLU-Professional Edition-49.552. 845.849.455.6 Обеспечение качества-34.336.336.335.937.9 Вопросы и ответы по теореме-35.932.329.334.943.1Baibihei 78.978.981.065.574.88 2.4 Ширасваг 87.888.788.086. 87.6 Большие окна 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668.9 Честные вопросы и ответы 42.251.045.659.649.654.8 Оценка персонала по кодированию 45.746.348.246.354.364.6 Департамент государственной службы Малайзии 73 .971.770.466.970.976.9 Оценка 55.054.154.852.957.765. 4 Разные 44.446.746.341.852.759.6 Математика GSM8K79. 283.783.079.585.489.5 Математика 43.641.742.534.149.651.1 Оценка C по китайскому языку 81.754.665.284.189.191.0 Университет Монреаля, Канада 84.053 .467.283.588.390.1Несколько языков и несколько экзаменов s 67.563.570.066.475.676.6Множественное понимание 77.077.779.978.278.280.7Множественная математика 58.862.967.161.764.476.0Множественные переводы 36.023.338.035.636.2 37.8Qwen2-57B-A14B Набор данных Jabba Mixtral-8x7B Instrument-1.5-34BQwen1. 5-32BQwen2-57B-A14B Архитектура MoE MoE Плотная Плотная MoE #Активные параметры 12B12B34B32B14B #Параметры 52B47B34B32B57B Английский Moleman Lu 67.471.877.174.376.5MMLU - Профессиональная версия - 41.048.344.043.0 Обеспечение качества - 29.2 - 30.834.3 Вопросы и ответы по теореме - 23.2 - 28.833.5 Байбэй Черный 45.450.376.466.867.0 Шиела Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 Честные вопросы и ответы 46.451.153.957.457.7 Кодирование оценки рабочей силы 29.337.246.343. 353,0 Государственная служба Малайзии - 63.965.564.271,9 Оценка - 46,451 .950.457.2 Разное - 39.03 9.538.549 .8 Математика GSM8K59.962.582.776.880.7 Математика-30.841.736.143.0 Оценка C по китайскому языку --- 83.587.7 Университет Монреаля, Канада -- 84.882.388.5 Несколько языков И многократные экзамены -56.158.361.665.5 Многопартийное понимание -70.773.976.577.0multiple Математика -45.049.356.162.3 Multiple Перевод -29,830.033.544.5QWEN2-7B DataSet DataSet -7 -–7BQQQQQQQWEN -3-7BQVEN -3 -3 -CAMMA -7BQQWEN2-7B. -7BQwen2-7B# Параметры 7,2B850 миллионов 8.0B7.7B7.6B# Не-emb параметры 7,0B780 миллионов 7,0B650 миллионов 650 миллионов Английский Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 Обеспечение качества 24.725 .725.826. 731.8 Вопросы и ответы по теореме 19.221.522.114.231.1 Байбэй Блэк 56.155.157.740.262.6 Ширасвагер 83.282.282.178.580.7 Виногранд 78.479.077.471.377.0ARC-C60.061.159 .3 54.260.6Честные вопросы и ответы 42.244 .844.051.154.2 Оценка персонала по кодированию 29.337.233.536 .051.2 Государственная служба Малайзии 51.150.653.951.665.9 Оценка 36.439.640.340.054.2 Множественный 29.429.722.628.146.3 Математика GSM8K52.246.456.0 62.579.9 Математика 13.124.320.520. 344.2 Оценка C человека в Китае 47.443.649.574.183.2 Университет Монреаля , Канада -- 50.873.183.9 Многоязычный многоязычный экзамен 47.142.752.347.759.2 Многофакторное понимание 63.358.368.667.672.0 Многомерная математика 26.339.136.337.357.5 Многократный перевод 23.331.231 .928.431.5Qwen 2 -0,5B и набор данных Qwen2-1,5B Phi-2Gemma -2B Минимальная цена за тысячу показов Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# Параметры Non-Emb 250 миллионов 2.0B2.4B1.3B035 миллионов 1,3 B Морман Лу 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 Теорема Вопросы и ответы ---- 8.915.0 Оценка рабочей силы 47.622.050.020.122.031.1 Департамент государственной службы Малайзии 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 Математика 3.511.810.210.110.7 21.7 Байби Блэк 43.435.236.924.228.437. 2 Шила Сваг 73.171.468.361.449.366.6 Виногранд 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 Честные вопросы и ответы 44.533.1-39.439.745.9C - Оценка 23.428. 051.159.758.270.6 Монреальский университет, Канада 24.2 — 51.157.855.170.3 Инструкция по настройке модели оценки Qwen2-72B — Набор управляемых данных Camel — 3-70B — Руководство Qwen1.5-72B — Чат Qwen2-72B — Руководство на английском языке Mohr Man Lu 82.075.682.3MMLU — Professional Edition 56.251. 764.4 Обеспечение качества 41.939.442.4 Вопросы и ответы по теоремам 42.528.844.4MT – Bench8.958.619.12 Arena – Hard 41.136.148.1 IFEval (быстрый строгий доступ) 77.355.877.6 Оценка рабочей силы по кодированию 81.771.386.0 Государственная служба Малайзии 82.3 71.980.2 Множественная 63.448.169.2 Оценка 75.266.979.0 Тест живого кода 29.317.935.7 Математика GSM 8K93.082.7 91.1 Математика 50.442.559.7 Китайская оценка C 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Instruction DatasetMix tral-8x7B-Instruct-v0.1Yi-1.5 -34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - Guidance Architecture Министерство образования Dense Dense Министерство образования #Активированный параметр 12B34B32B14B #Параметр 47B34B32B57B Английский Mohr Man Lu 71.476.874.875.4MMLU - Профессиональная версия 43.352.346.452 .8 Качество Гарантия -- 30.834.3 Вопросы и ответы по теореме -- -30.933.1MT-Bench8.308.508.308.55 Оценка рабочей силы для кодирования 45.175.268.379.9 Государственная служба Малайзии 59.574.667.970.9 Различные --50.766.4 Оценка 48.5-63.671.6 В реальном времени Код Тест 12.3-15.225.5 Математика GSM8K65.790.283.679.6 Математика 30.750.142.449.1 Китайский C-Evaluation--76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide Набор данных Camel-3-8B-Guide Yi-1.5 -9Б -Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide English Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 Обеспечение качества 34.2--27.825.3 Теорема Вопросы и ответы 23.0- -14.125 .3MT-Bench8.058.208.357.608.41 Гуманитарное кодирование 62.266.571.846.379.9 Государственная служба Малайзия 67,9--48,967,2 Множественная 48,5--27,259,1 Оценка 60,9--44,870,3 Тестирование живого кода 17,3-- 6,0 26. 6 Математика GSM8K79.684.879.660.382.3 Математика 30.047.750.623.249.6 Китайская C-оценка 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct и Qwen2-1.5B-Instruct Data установите Qwen1 5-. 0.5B-Chat Qwen2-0.5B-Guide Qwen1.5-1.8B-Chat Qwen2-1.5B-Guide Morman Lu35.037.943.752.4 Оценка рабочей силы 9.117.125.037.8GSM8K11.340.135.361.6C-Оценка 37.245.255.363. 8IFEval ( запрос на строгий доступ) Команда 14.620.016.829.0 настраивает многоязычные возможности модели.Мы сравниваем модель настройки инструкций Qwen2 с другими недавними LLM по нескольким открытым межъязыковым тестам, а также по результатам человеческой оценки. В качестве базового уровня мы представляем результаты по двум наборам оценочных данных:
M-MMLU Окапи: многоязычная оценка общих знаний (для оценки мы используем подмножества ar, de, es, fr, it, nl, ru, uk, vi, zh). MGSM: для оценки немецкого, английского, испанского, французского языка, математики в Японский, русский, тайский, китайский и бразильский языкиРезультаты усреднены по языкам для каждого бенчмарка и выглядят следующим образом:
Образцовый M-MMLU (5 выстрелов) MGSM (0 выстрелов, CoT) Собственный LLM GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 команда LL.M с открытым исходным кодом-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -Направляющая 60.057.0Qwen2-57B-A14B-Направляющая 68.074.0Qwen2-72B-Направляющая 78.086.6Для ручной оценки мы сравниваем Qwen2-72B-Instruct с GPT3.5, GPT4 и Claude-3-Opus, используя собственный оценочный набор, включающий 10 языков ar, es, fr, ko, th, vi, pt, id, ja и ru (диапазон баллов от 1 до 5):
Модель Дебиторская задолженность Испанский Французский Corri Six Points ID Jiaru Average Claude-3-Works-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 9 3.724.324.09 ГПТ-4-Турбо- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-Guide 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 53.923 .943.873.833.953.553.773.063.633.71GPT-3.5-Турбо-11062.524. 073.472.373.382.903.373.562.753.243.16Сгруппированные по типам задач, результаты следующие:
Понимание знаний о модели Создание математических вычислений ГПТ-4-06133.424. 32ГПТ-3,5-Турбо-11063.373.673.892.97Эти результаты демонстрируют мощные многоязычные возможности модели настройки инструкций Qwen2.
Модели серии Qwen2 с открытым исходным кодом от Alibaba значительно улучшили производительность и поддерживают многоязычность, внося важный вклад в сообщество искусственного интеллекта с открытым исходным кодом. В будущем Qwen2 продолжит развивать и расширять масштаб модели и мультимодальные возможности, на что стоит рассчитывать.