system design 101
1.0.0
【 ?? YouTube | - จดหมายข่าว 】
อธิบายระบบที่ซับซ้อนโดยใช้ภาพและคำศัพท์ง่ายๆ
ไม่ว่าคุณกำลังเตรียมตัวสำหรับการสัมภาษณ์การออกแบบระบบหรือเพียงต้องการทำความเข้าใจว่าระบบทำงานอย่างไร เราหวังว่าพื้นที่เก็บข้อมูลนี้จะช่วยให้คุณบรรลุเป้าหมายนั้น
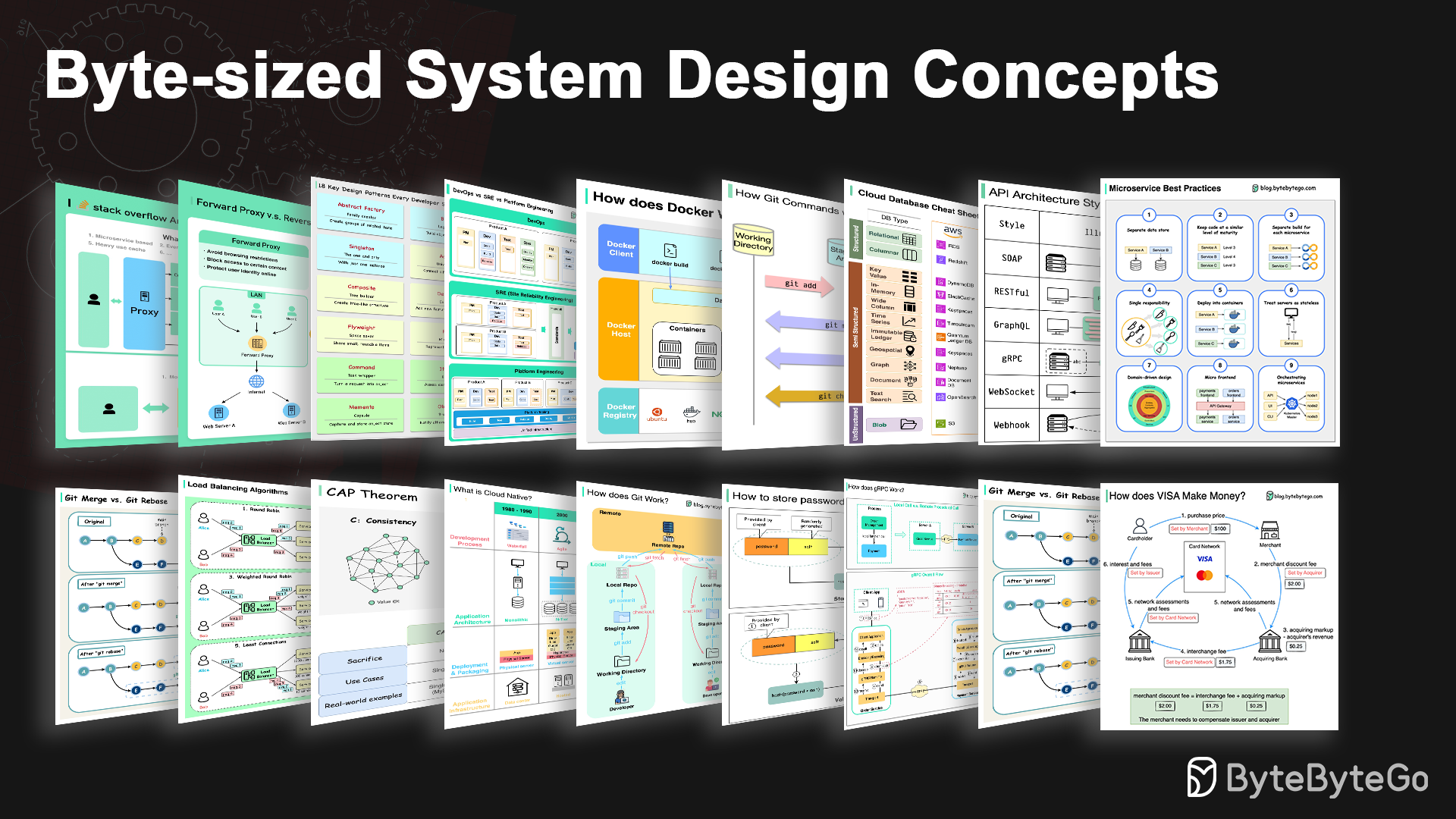
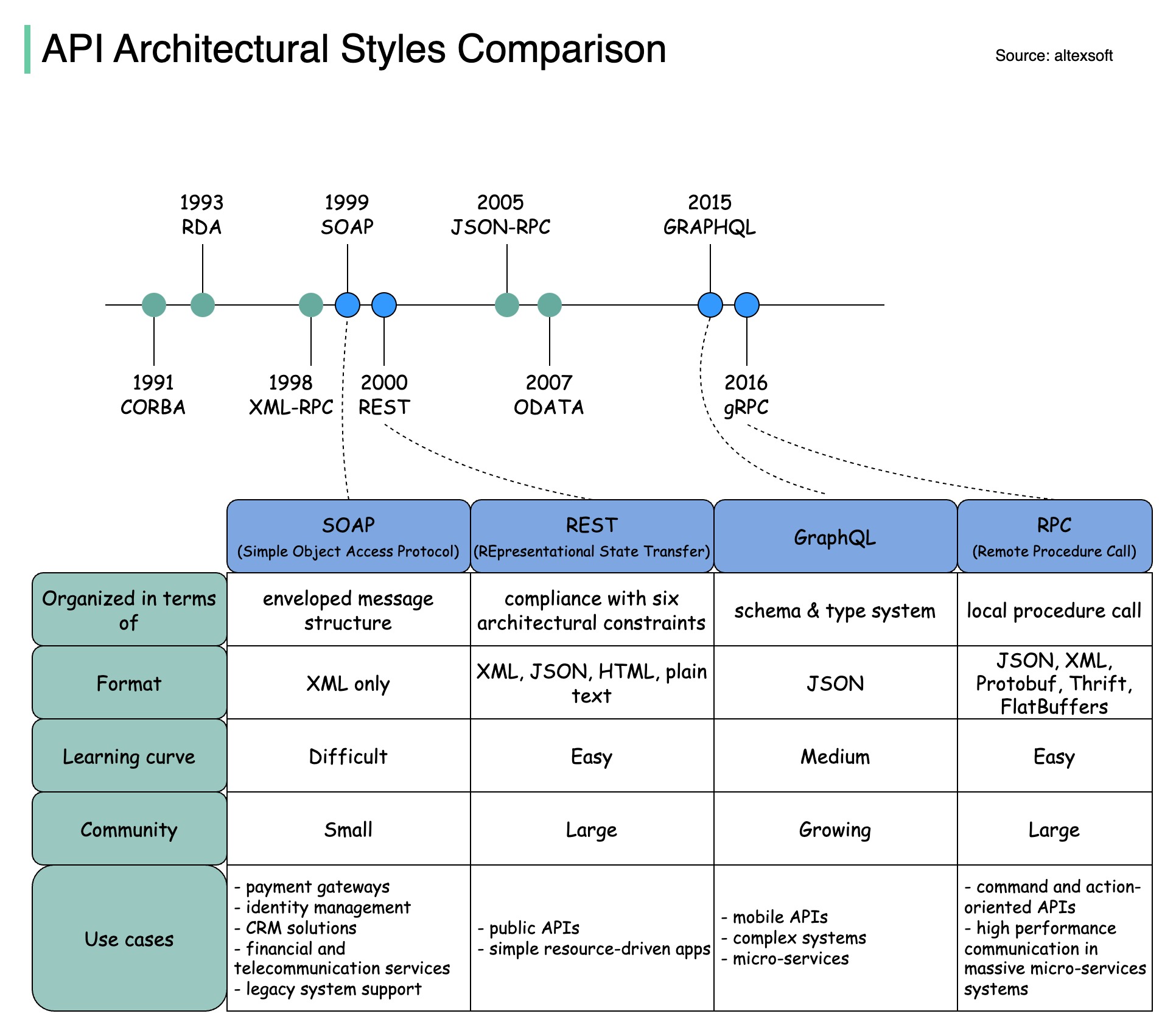
รูปแบบสถาปัตยกรรมกำหนดว่าส่วนประกอบต่างๆ ของ Application Programming Interface (API) โต้ตอบกันอย่างไร ด้วยเหตุนี้ พวกเขาจึงมั่นใจในประสิทธิภาพ ความน่าเชื่อถือ และความง่ายในการบูรณาการกับระบบอื่นๆ โดยมอบแนวทางมาตรฐานในการออกแบบและสร้าง API นี่คือสไตล์ที่ใช้มากที่สุด:
สบู่:
เป็นผู้ใหญ่ ครอบคลุม อิง XML
ดีที่สุดสำหรับแอปพลิเคชันระดับองค์กร
สงบ:
วิธี HTTP ยอดนิยมที่ใช้งานง่าย
เหมาะสำหรับบริการบนเว็บ
กราฟ QL:
ภาษาแบบสอบถาม ขอข้อมูลเฉพาะ
ลดโอเวอร์เฮดของเครือข่าย ตอบสนองเร็วขึ้น
จีอาร์พีซี:
บัฟเฟอร์โปรโตคอลที่ทันสมัย ประสิทธิภาพสูง
เหมาะสำหรับสถาปัตยกรรมไมโครเซอร์วิส
เว็บซ็อกเก็ต:
การเชื่อมต่อแบบเรียลไทม์ แบบสองทิศทาง และต่อเนื่อง
เหมาะสำหรับการแลกเปลี่ยนข้อมูลที่มีความหน่วงต่ำ
เว็บฮุค:
ขับเคลื่อนด้วยเหตุการณ์, การโทรกลับ HTTP, อะซิงโครนัส
แจ้งเตือนระบบเมื่อมีเหตุการณ์เกิดขึ้น
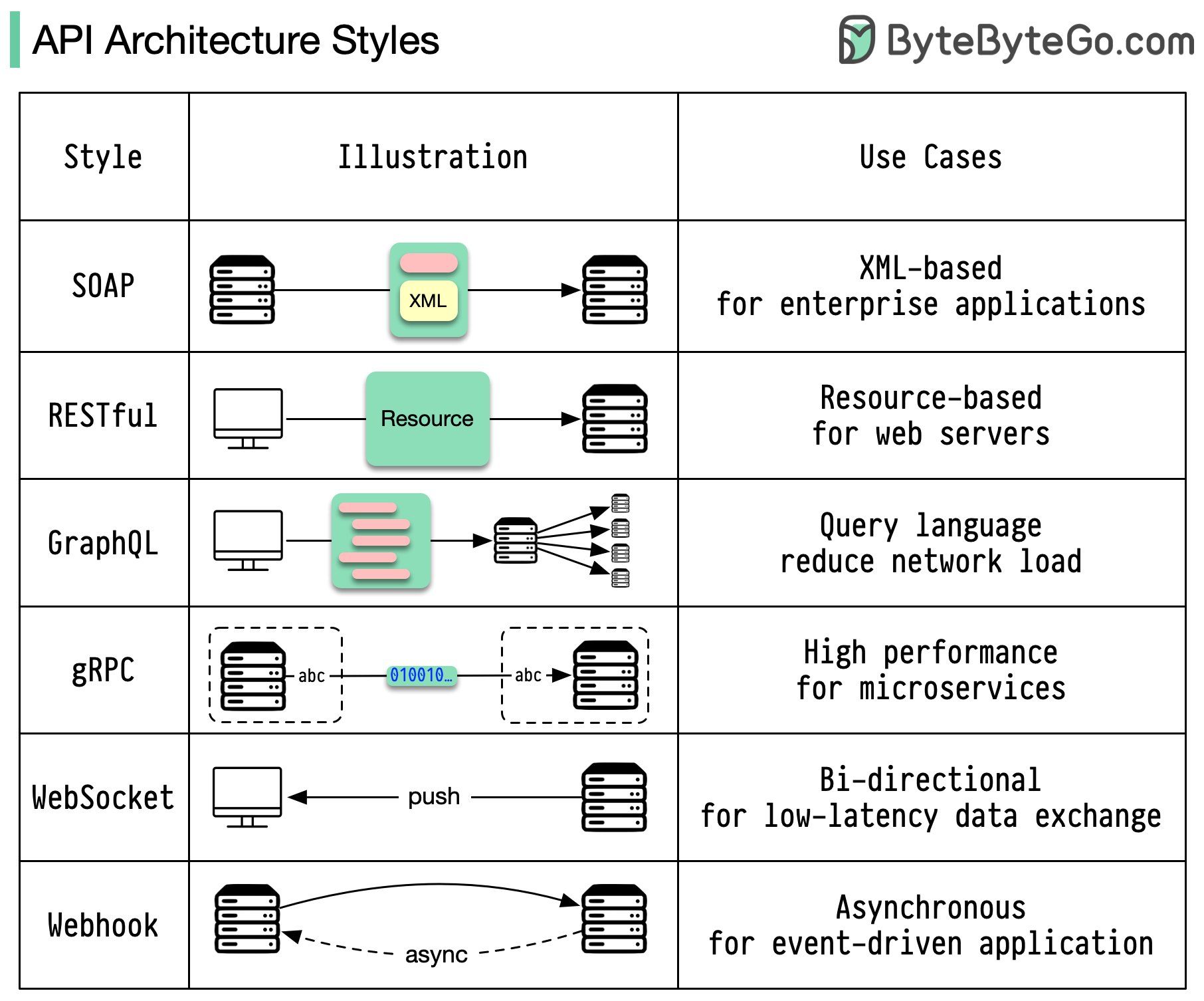
เมื่อพูดถึงการออกแบบ API REST และ GraphQL ต่างก็มีจุดแข็งและจุดอ่อนของตัวเอง
แผนภาพด้านล่างแสดงการเปรียบเทียบอย่างรวดเร็วระหว่าง REST และ GraphQL
พักผ่อน
GraphQL
ตัวเลือกที่ดีที่สุดระหว่าง REST และ GraphQL ขึ้นอยู่กับข้อกำหนดเฉพาะของแอปพลิเคชันและทีมพัฒนา GraphQL เหมาะอย่างยิ่งสำหรับความต้องการฟรอนต์เอนด์ที่ซับซ้อนหรือเปลี่ยนแปลงบ่อยครั้ง ในขณะที่ REST เหมาะกับแอปพลิเคชันที่ต้องการสัญญาที่เรียบง่ายและสม่ำเสมอ
แนวทาง API ไม่ใช่สัญลักษณ์แสดงหัวข้อย่อยสีเงิน การประเมินข้อกำหนดและข้อดีข้อเสียอย่างรอบคอบเป็นสิ่งสำคัญในการเลือกสไตล์ที่เหมาะสม ทั้ง REST และ GraphQL เป็นตัวเลือกที่ถูกต้องสำหรับการเปิดเผยข้อมูลและขับเคลื่อนแอปพลิเคชันสมัยใหม่
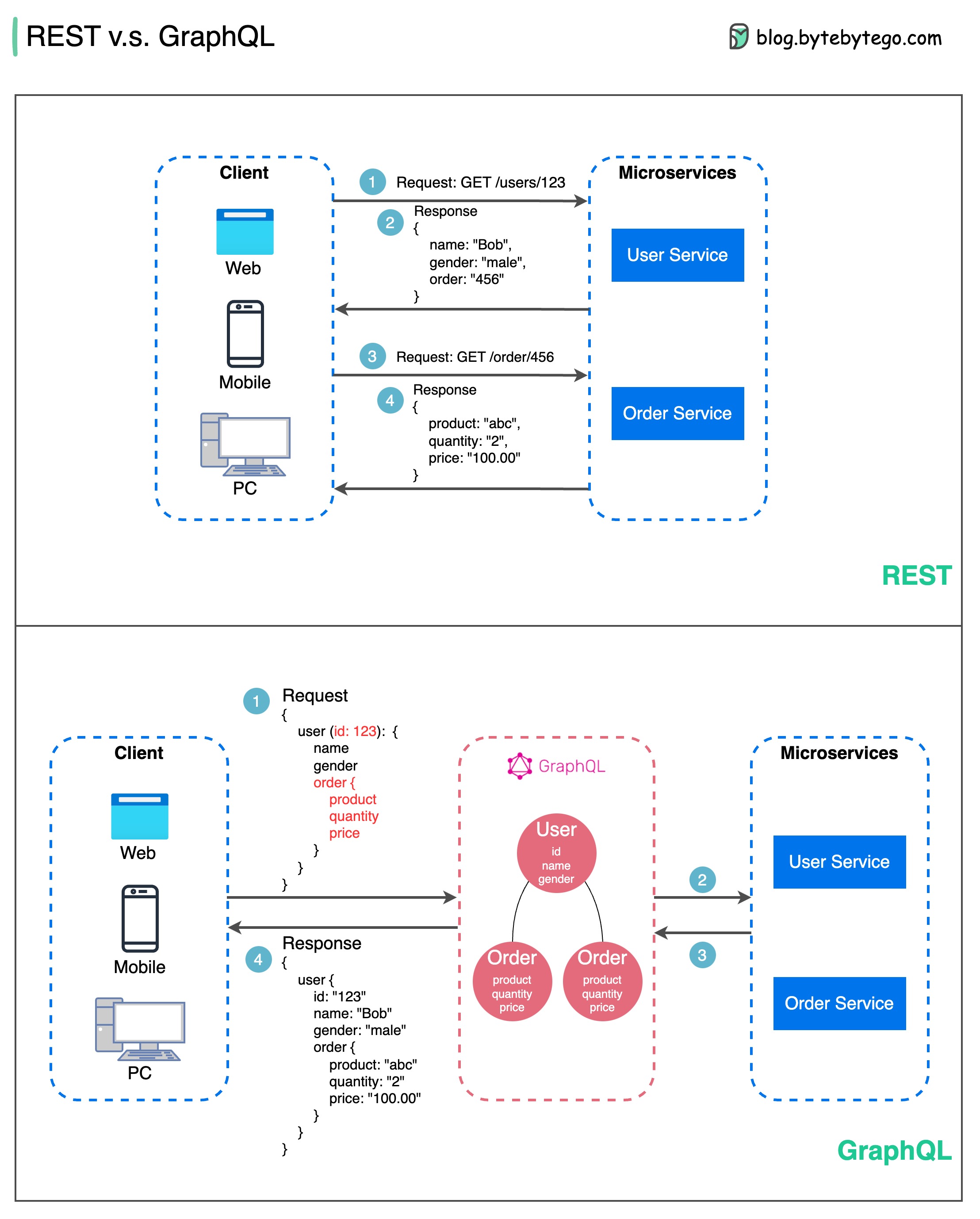
RPC (การเรียกขั้นตอนระยะไกล) เรียกว่า “ ระยะไกล ” เนื่องจากทำให้สามารถสื่อสารระหว่างบริการระยะไกลเมื่อมีการปรับใช้บริการกับเซิร์ฟเวอร์ที่แตกต่างกันภายใต้สถาปัตยกรรมไมโครเซอร์วิส จากมุมมองของผู้ใช้ มันทำหน้าที่เหมือนกับการเรียกใช้ฟังก์ชันในเครื่อง
แผนภาพด้านล่างแสดงการไหลของข้อมูลโดยรวมสำหรับ gRPC
ขั้นตอนที่ 1: การเรียก REST เกิดขึ้นจากไคลเอ็นต์ เนื้อหาของคำขอมักจะอยู่ในรูปแบบ JSON
ขั้นตอนที่ 2 - 4: บริการสั่งซื้อ (ไคลเอนต์ gRPC) ได้รับการเรียก REST แปลง และทำการเรียก RPC ไปยังบริการการชำระเงิน gRPC เข้ารหัส ต้นขั้วไคลเอ็นต์ เป็นรูปแบบไบนารีและส่งไปยังเลเยอร์การขนส่งระดับต่ำ
ขั้นตอนที่ 5: gRPC ส่งแพ็กเก็ตผ่านเครือข่ายผ่าน HTTP2 เนื่องจากการเข้ารหัสไบนารี่และการเพิ่มประสิทธิภาพเครือข่าย gRPC จึงเร็วกว่า JSON ถึง 5 เท่า
ขั้นตอนที่ 6 - 8: บริการชำระเงิน (เซิร์ฟเวอร์ gRPC) รับแพ็กเก็ตจากเครือข่าย ถอดรหัส และเรียกใช้แอปพลิเคชันเซิร์ฟเวอร์
ขั้นตอนที่ 9 - 11: ผลลัพธ์จะถูกส่งกลับจากแอปพลิเคชันเซิร์ฟเวอร์ และได้รับการเข้ารหัสและส่งไปยังเลเยอร์การขนส่ง
ขั้นตอนที่ 12 - 14: บริการสั่งซื้อจะได้รับแพ็กเก็ต ถอดรหัส และส่งผลลัพธ์ไปยังแอปพลิเคชันไคลเอนต์
แผนภาพด้านล่างแสดงการเปรียบเทียบระหว่างการสำรวจความคิดเห็นและ Webhook
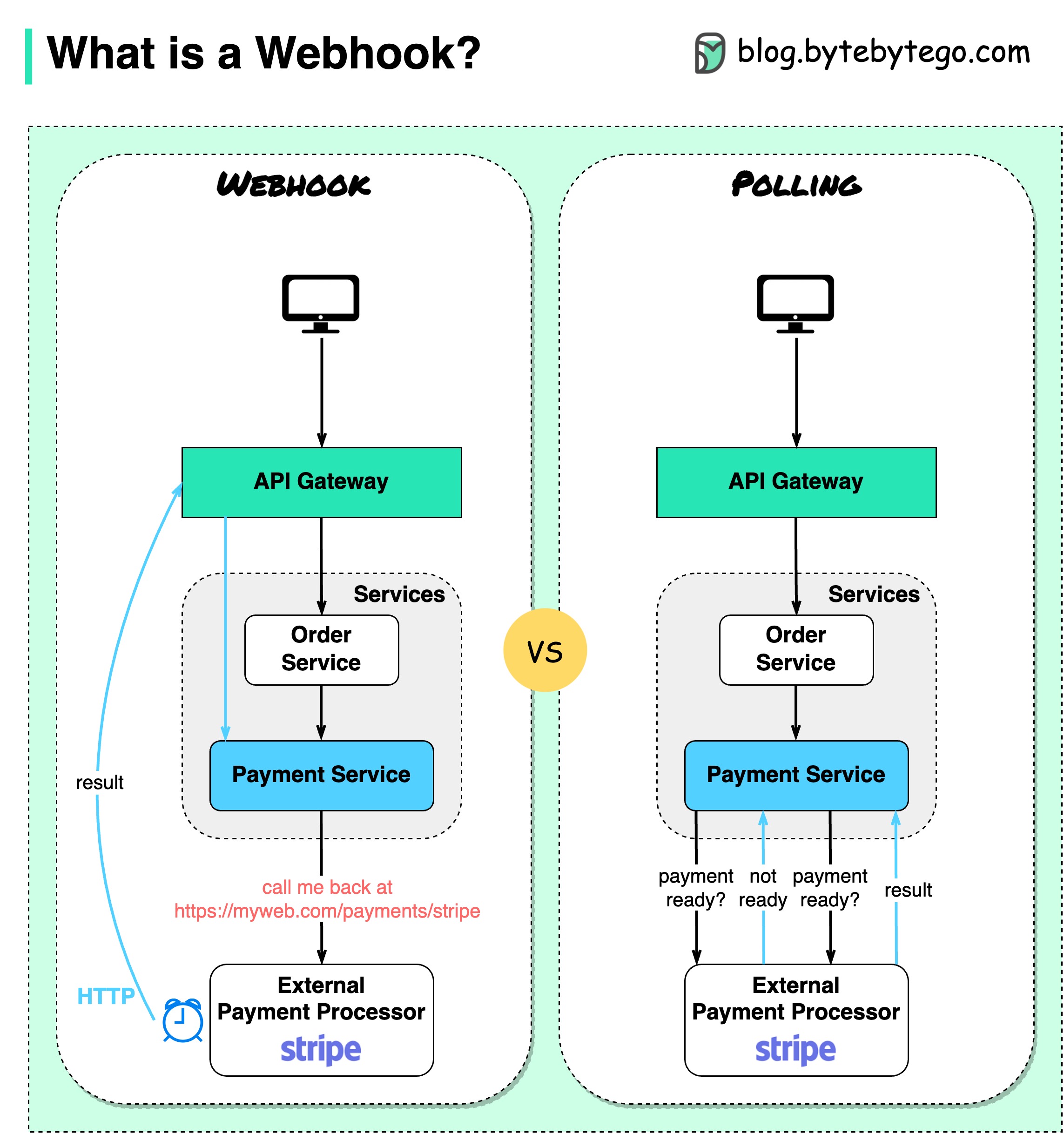
สมมติว่าเราเปิดเว็บไซต์อีคอมเมิร์ซ ลูกค้าส่งคำสั่งซื้อไปยังบริการสั่งซื้อผ่านเกตเวย์ API ซึ่งจะไปที่บริการชำระเงินสำหรับธุรกรรมการชำระเงิน บริการชำระเงินจะพูดคุยกับผู้ให้บริการชำระเงินภายนอก (PSP) เพื่อทำธุรกรรมให้เสร็จสิ้น
มีสองวิธีในการจัดการสื่อสารกับ PSP ภายนอก
1. การเลือกตั้งระยะสั้น
หลังจากส่งคำขอชำระเงินไปยัง PSP แล้ว บริการชำระเงินจะถาม PSP เกี่ยวกับสถานะการชำระเงินต่อไป หลังจากผ่านไปหลายรอบ ในที่สุด PSP ก็กลับมาพร้อมกับสถานะ
การลงคะแนนเสียงแบบสั้นมีข้อเสียอยู่ 2 ประการ:
2. เว็บฮุค
เราสามารถลงทะเบียน webhook กับบริการภายนอกได้ หมายความว่า: โทรกลับหาฉันที่ URL หนึ่งเมื่อคุณมีข้อมูลอัปเดตเกี่ยวกับคำขอ เมื่อ PSP ดำเนินการเสร็จสิ้น ระบบจะเรียกใช้คำขอ HTTP เพื่ออัปเดตสถานะการชำระเงิน
ด้วยวิธีนี้ กระบวนทัศน์การเขียนโปรแกรมจึงเปลี่ยนไป และบริการชำระเงินไม่จำเป็นต้องสิ้นเปลืองทรัพยากรเพื่อสำรวจสถานะการชำระเงินอีกต่อไป
จะเกิดอะไรขึ้นถ้า PSP ไม่โทรกลับ? เราสามารถตั้งค่างานแม่บ้านตรวจสอบสถานะการชำระเงินได้ทุกชั่วโมง
Webhooks มักถูกเรียกว่า Reverse API หรือ Push API เนื่องจากเซิร์ฟเวอร์ส่งคำขอ HTTP ไปยังไคลเอ็นต์ เราต้องใส่ใจกับ 3 สิ่งเมื่อใช้ webhook:
แผนภาพด้านล่างแสดงเคล็ดลับทั่วไป 5 ข้อในการปรับปรุงประสิทธิภาพของ API
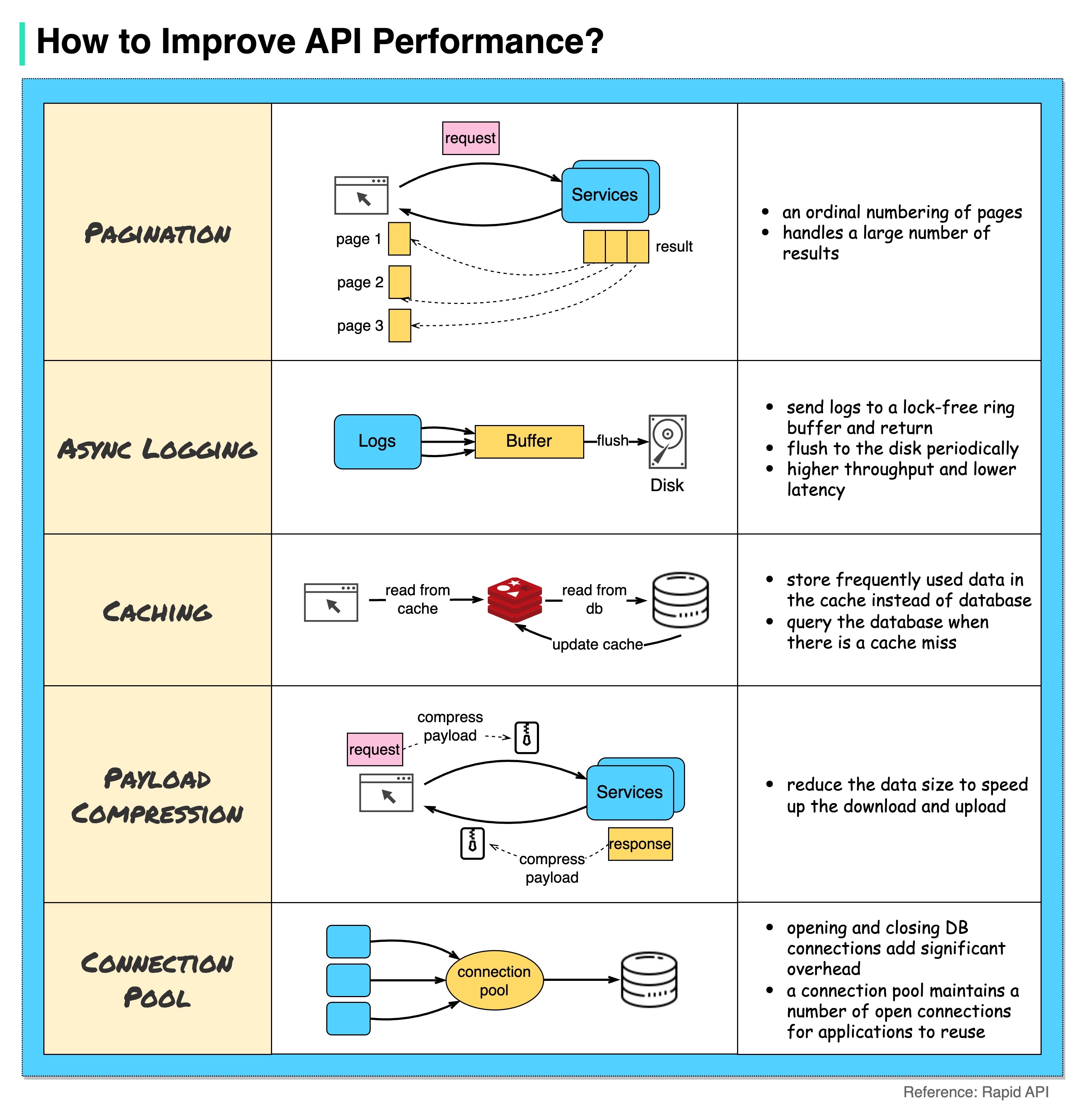
การแบ่งหน้า
นี่คือการปรับให้เหมาะสมทั่วไปเมื่อขนาดของผลลัพธ์มีขนาดใหญ่ ผลลัพธ์จะถูกส่งกลับไปยังไคลเอนต์เพื่อปรับปรุงการตอบสนองของบริการ
การบันทึกแบบอะซิงโครนัส
การบันทึกแบบซิงโครนัสเกี่ยวข้องกับดิสก์สำหรับการโทรทุกครั้ง และอาจทำให้ระบบช้าลง การบันทึกแบบอะซิงโครนัสจะส่งบันทึกไปยังบัฟเฟอร์ที่ไม่มีการล็อคก่อนแล้วจึงส่งคืนทันที บันทึกจะถูกล้างข้อมูลลงดิสก์เป็นระยะ ซึ่งจะช่วยลดค่าใช้จ่าย I/O ลงอย่างมาก
การแคช
เราสามารถจัดเก็บข้อมูลที่เข้าถึงบ่อยไว้ในแคชได้ ไคลเอ็นต์สามารถสอบถามแคชก่อนแทนที่จะไปที่ฐานข้อมูลโดยตรง หากมีแคชหายไป ไคลเอนต์สามารถสอบถามจากฐานข้อมูลได้ แคช เช่น Redis จะจัดเก็บข้อมูลไว้ในหน่วยความจำ ดังนั้นการเข้าถึงข้อมูลจึงเร็วกว่าฐานข้อมูลมาก
การบีบอัดเพย์โหลด
คำขอและการตอบกลับสามารถบีบอัดได้โดยใช้ gzip ฯลฯ เพื่อให้ขนาดข้อมูลที่ส่งมีขนาดเล็กลงมาก สิ่งนี้จะช่วยเพิ่มความเร็วในการอัพโหลดและดาวน์โหลด
พูลการเชื่อมต่อ
เมื่อเข้าถึงทรัพยากร เรามักจะต้องโหลดข้อมูลจากฐานข้อมูล การเปิดการเชื่อมต่อฐานข้อมูลแบบปิดจะเพิ่มค่าใช้จ่ายที่สำคัญ ดังนั้นเราจึงควรเชื่อมต่อกับ db ผ่านกลุ่มการเชื่อมต่อแบบเปิด พูลการเชื่อมต่อมีหน้าที่ในการจัดการวงจรการเชื่อมต่อ
HTTP แต่ละรุ่นแก้ปัญหาอะไรได้บ้าง
แผนภาพด้านล่างแสดงคุณสมบัติที่สำคัญ
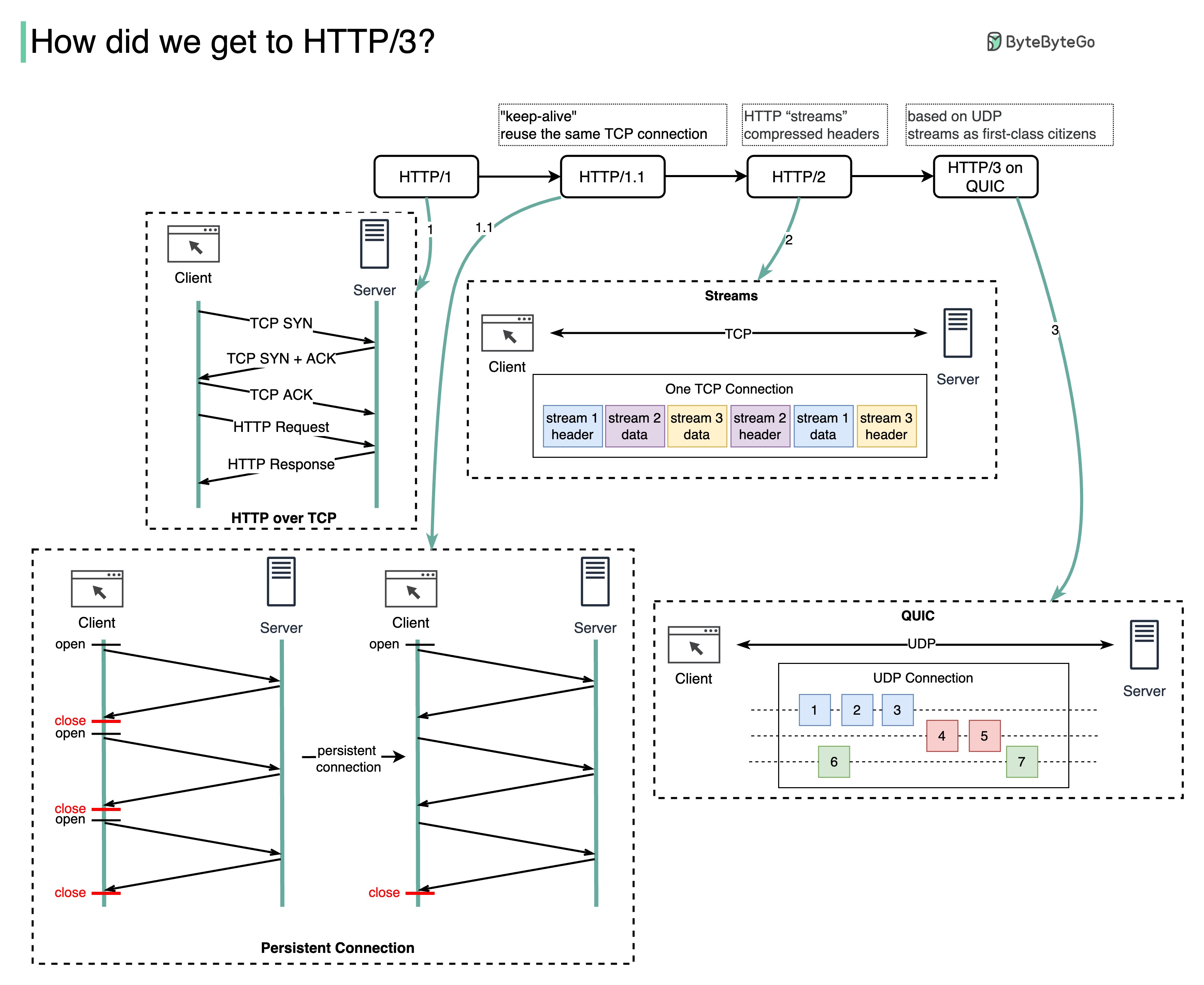
HTTP 1.0 ได้รับการสรุปและจัดทำเอกสารอย่างครบถ้วนในปี 1996 ทุกคำขอไปยังเซิร์ฟเวอร์เดียวกันต้องมีการเชื่อมต่อ TCP แยกต่างหาก
HTTP 1.1 เปิดตัวในปี 1997 การเชื่อมต่อ TCP สามารถเปิดทิ้งไว้เพื่อนำมาใช้ซ้ำได้ (การเชื่อมต่อแบบถาวร) แต่ไม่สามารถแก้ปัญหาการบล็อก HOL (ส่วนหัวของบรรทัด) ได้
การบล็อก HOL - เมื่อใช้คำขอแบบขนานที่อนุญาตในเบราว์เซอร์จนหมด คำขอที่ตามมาจะต้องรอให้คำขอเดิมดำเนินการให้เสร็จสิ้น
HTTP 2.0 ได้รับการเผยแพร่ในปี 2558 โดยจะแก้ไขปัญหา HOL ผ่านการร้องขอมัลติเพล็กซ์ ซึ่งกำจัดการบล็อก HOL ที่เลเยอร์แอปพลิเคชัน แต่ HOL ยังคงมีอยู่ที่เลเยอร์การขนส่ง (TCP)
ดังที่คุณเห็นในแผนภาพ HTTP 2.0 ได้แนะนำแนวคิดของ HTTP “สตรีม”: นามธรรมที่อนุญาตให้มีการแลกเปลี่ยน HTTP ที่แตกต่างกันแบบมัลติเพล็กซ์บนการเชื่อมต่อ TCP เดียวกัน ไม่จำเป็นต้องส่งแต่ละสตรีมตามลำดับ
HTTP 3.0 ร่างแรกเผยแพร่ในปี 2020 เป็นตัวตายตัวแทนที่เสนอของ HTTP 2.0 โดยจะใช้ QUIC แทน TCP สำหรับโปรโตคอลการขนส่งพื้นฐาน จึงลบการบล็อก HOL ในเลเยอร์การขนส่งออก
QUIC ขึ้นอยู่กับ UDP โดยแนะนำลำธารในฐานะพลเมืองชั้นหนึ่งในชั้นการขนส่ง สตรีม QUIC ใช้การเชื่อมต่อ QUIC เดียวกัน ดังนั้นจึงไม่จำเป็นต้องมีการจับมือกันเพิ่มเติมและการเริ่มช้าๆ เพื่อสร้างรายการใหม่ แต่สตรีม QUIC จะถูกส่งแยกกัน โดยส่วนใหญ่แล้วการสูญเสียแพ็กเก็ตที่ส่งผลต่อสตรีมหนึ่งจะไม่ส่งผลกระทบต่อสตรีมอื่นๆ
แผนภาพด้านล่างแสดงไทม์ไลน์ API และการเปรียบเทียบสไตล์ API
เมื่อเวลาผ่านไป รูปแบบสถาปัตยกรรม API ต่างๆ จะถูกเผยแพร่ แต่ละแห่งมีรูปแบบการแลกเปลี่ยนข้อมูลที่เป็นมาตรฐานของตัวเอง
คุณสามารถดูกรณีการใช้งานของแต่ละสไตล์ได้ในแผนภาพ
แผนภาพด้านล่างแสดงความแตกต่างระหว่างการพัฒนาที่เน้นโค้ดเป็นหลักและการพัฒนาที่เน้น API เป็นหลัก เหตุใดเราจึงต้องพิจารณาการออกแบบ API ก่อน
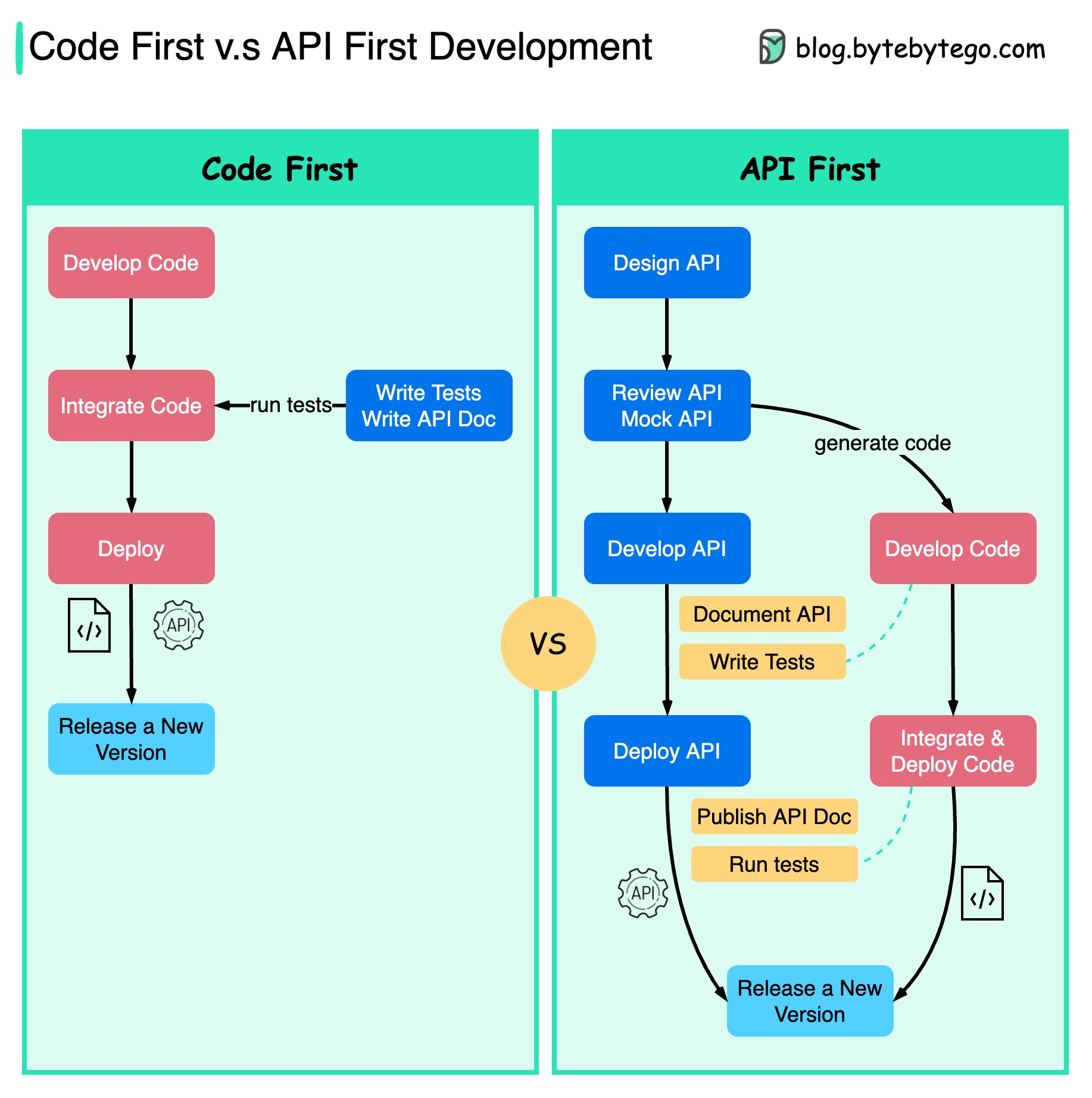
ควรคิดถึงความซับซ้อนของระบบก่อนที่จะเขียนโค้ดและกำหนดขอบเขตของบริการอย่างรอบคอบ
เราสามารถจำลองคำขอและการตอบกลับเพื่อตรวจสอบการออกแบบ API ก่อนที่จะเขียนโค้ด
นักพัฒนาพอใจกับกระบวนการนี้เช่นกัน เนื่องจากพวกเขาสามารถมุ่งเน้นไปที่การพัฒนาฟังก์ชั่นแทนที่จะเจรจาการเปลี่ยนแปลงกะทันหัน
ความเป็นไปได้ที่จะเกิดเรื่องประหลาดใจเมื่อสิ้นสุดวงจรชีวิตของโครงการจะลดลง
เนื่องจากเราได้ออกแบบ API ก่อน การทดสอบจึงสามารถออกแบบได้ในขณะที่โค้ดกำลังได้รับการพัฒนา ในทางหนึ่ง เรายังมี TDD (Test Driven Design) เมื่อใช้ API การพัฒนาครั้งแรก
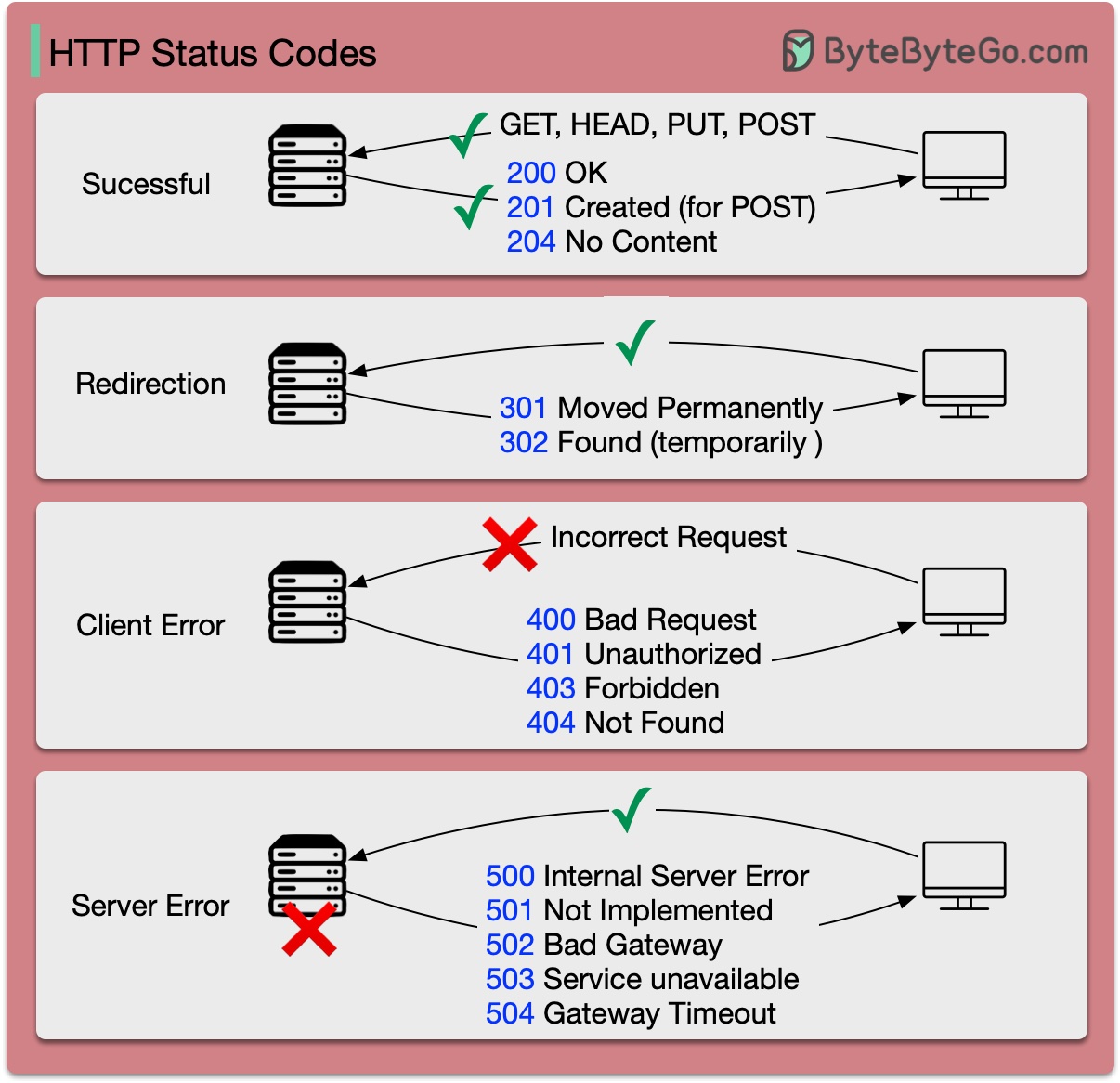
รหัสตอบกลับสำหรับ HTTP แบ่งออกเป็นห้าประเภท:
ข้อมูล (100-199) สำเร็จ (200-299) การเปลี่ยนเส้นทาง (300-399) ข้อผิดพลาดของไคลเอ็นต์ (400-499) ข้อผิดพลาดของเซิร์ฟเวอร์ (500-599)
แผนภาพด้านล่างแสดงรายละเอียด
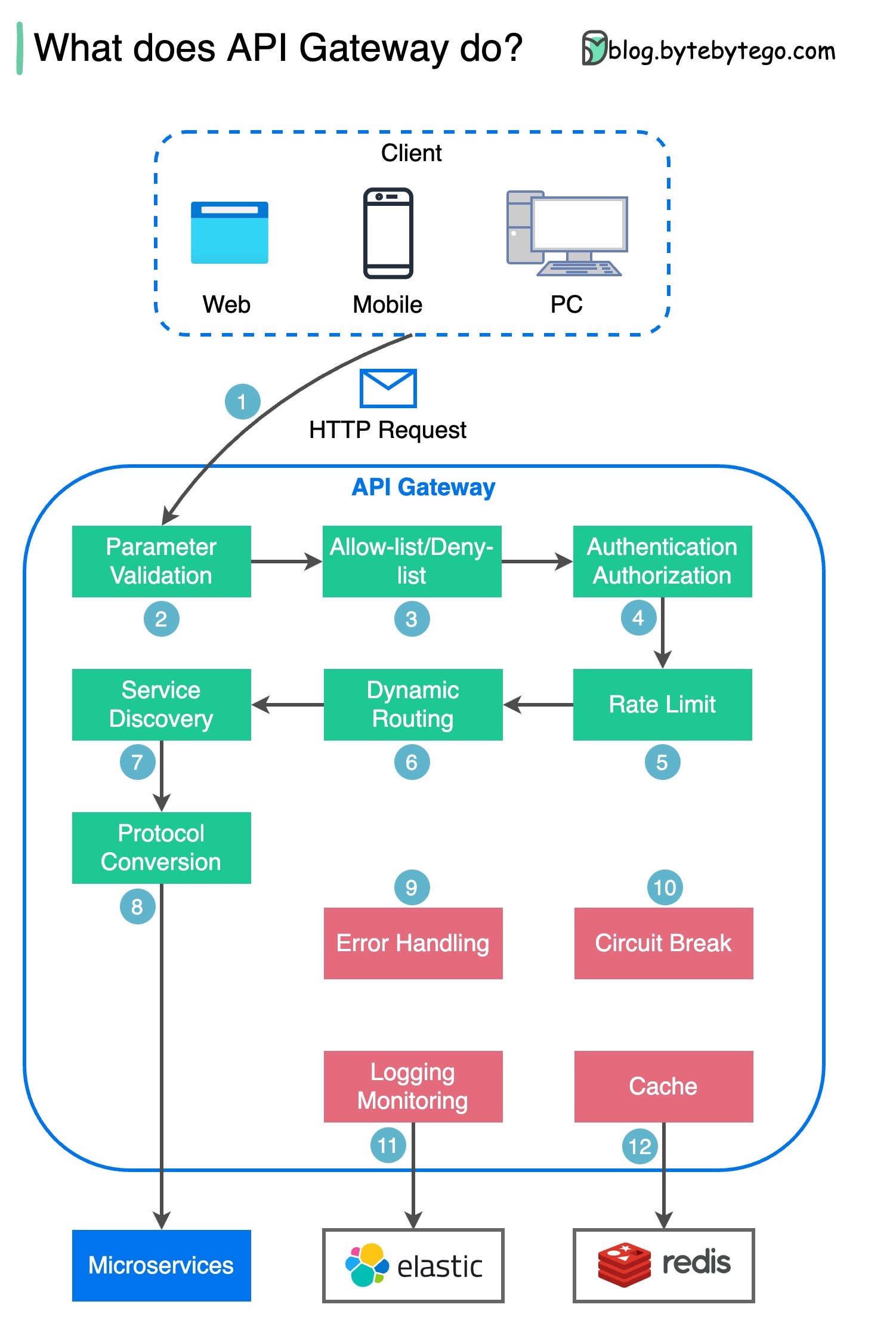
ขั้นตอนที่ 1 - ไคลเอนต์ส่งคำขอ HTTP ไปยังเกตเวย์ API
ขั้นตอนที่ 2 - เกตเวย์ API จะแยกวิเคราะห์และตรวจสอบแอตทริบิวต์ในคำขอ HTTP
ขั้นตอนที่ 3 - เกตเวย์ API ดำเนินการตรวจสอบรายการที่อนุญาต/ปฏิเสธรายการ
ขั้นตอนที่ 4 - เกตเวย์ API พูดคุยกับผู้ให้บริการข้อมูลประจำตัวเพื่อตรวจสอบสิทธิ์และการอนุญาต
ขั้นตอนที่ 5 - ใช้กฎการจำกัดอัตรากับคำขอ หากเกินขีดจำกัด คำขอจะถูกปฏิเสธ
ขั้นตอนที่ 6 และ 7 - เมื่อคำขอผ่านการตรวจสอบพื้นฐานแล้ว เกตเวย์ API จะค้นหาบริการที่เกี่ยวข้องเพื่อกำหนดเส้นทางไปโดยการจับคู่เส้นทาง
ขั้นตอนที่ 8 - เกตเวย์ API แปลงคำขอเป็นโปรโตคอลที่เหมาะสม และส่งไปยังไมโครเซอร์วิสแบ็กเอนด์
ขั้นตอนที่ 9-12: เกตเวย์ API สามารถจัดการข้อผิดพลาดได้อย่างถูกต้อง และจัดการกับข้อผิดพลาดหากข้อผิดพลาดใช้เวลาในการกู้คืนนานขึ้น (วงจรพัง) นอกจากนี้ยังสามารถใช้ประโยชน์จากสแต็ก ELK (Elastic-Logstash-Kibana) สำหรับการบันทึกและการตรวจสอบได้อีกด้วย บางครั้งเราแคชข้อมูลไว้ในเกตเวย์ API
แผนภาพด้านล่างแสดงการออกแบบ API ทั่วไปพร้อมตัวอย่างตะกร้าสินค้า
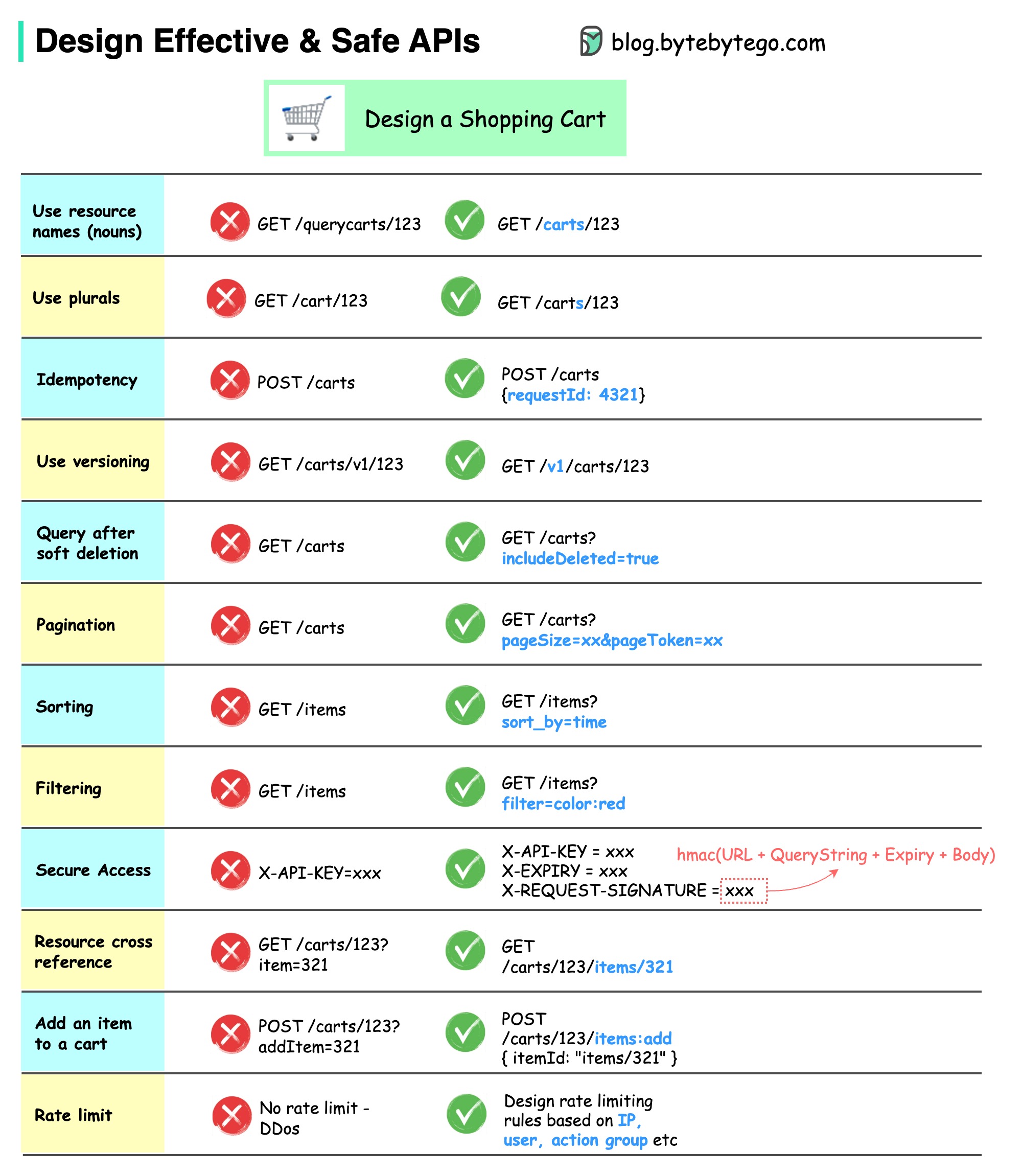
โปรดทราบว่าการออกแบบ API ไม่ใช่แค่การออกแบบเส้นทาง URL เท่านั้น โดยส่วนใหญ่ เราต้องเลือกชื่อทรัพยากร ตัวระบุ และรูปแบบเส้นทางที่เหมาะสม การออกแบบฟิลด์ส่วนหัว HTTP ที่เหมาะสมหรือการออกแบบกฎการจำกัดอัตราที่มีประสิทธิภาพภายในเกตเวย์ API มีความสำคัญเท่าเทียมกัน
ข้อมูลถูกส่งผ่านเครือข่ายอย่างไร? เหตุใดเราจึงต้องมีเลเยอร์จำนวนมากในโมเดล OSI
แผนภาพด้านล่างแสดงวิธีการห่อหุ้มข้อมูลและยกเลิกการห่อหุ้มข้อมูลเมื่อส่งผ่านเครือข่าย
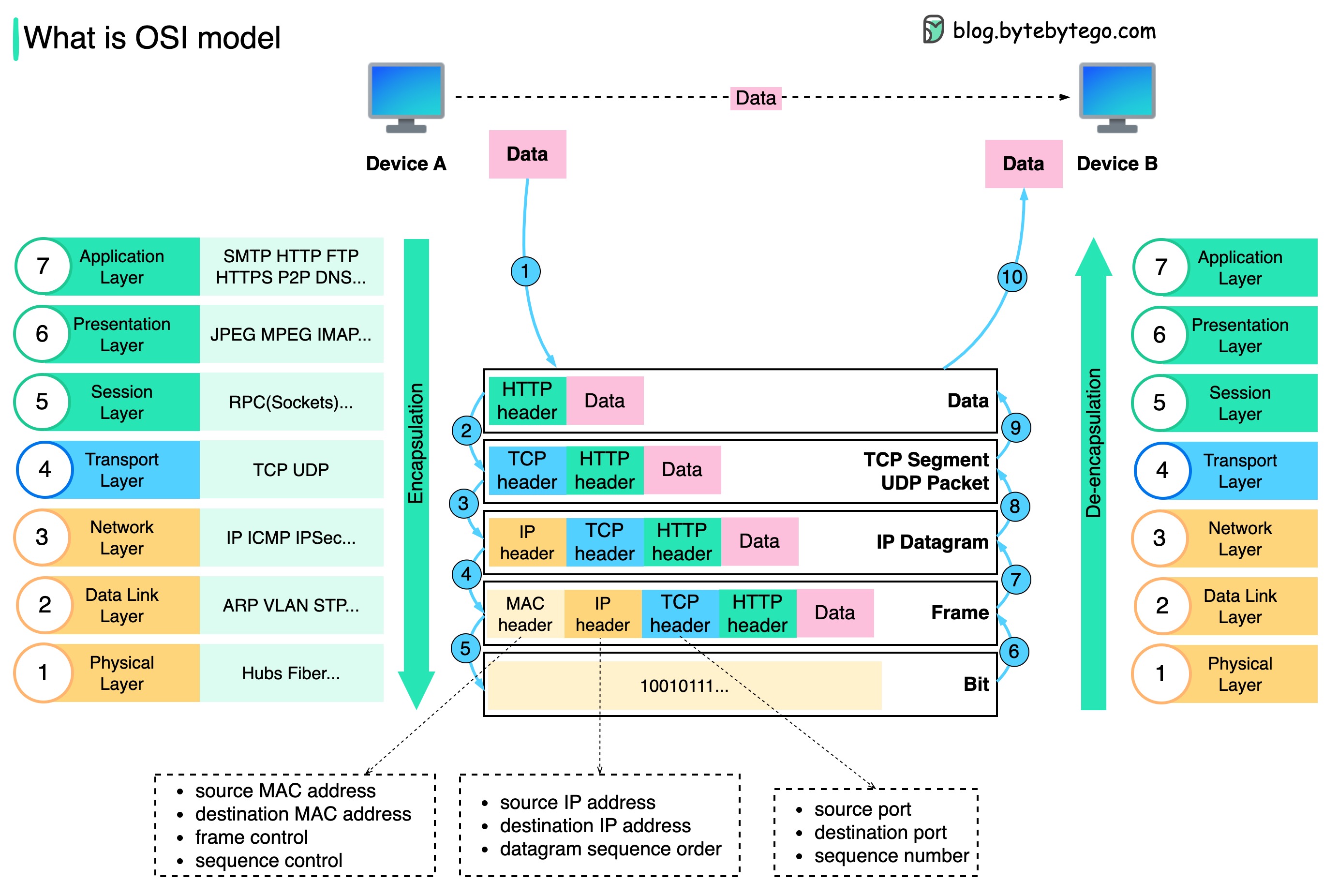
ขั้นตอนที่ 1: เมื่ออุปกรณ์ A ส่งข้อมูลไปยังอุปกรณ์ B ผ่านเครือข่ายผ่านโปรโตคอล HTTP อุปกรณ์นั้นจะถูกเพิ่มส่วนหัว HTTP ที่เลเยอร์แอปพลิเคชันก่อน
ขั้นตอนที่ 2: จากนั้นส่วนหัว TCP หรือ UDP จะถูกเพิ่มลงในข้อมูล มันถูกห่อหุ้มเป็นส่วน TCP ที่ชั้นการขนส่ง ส่วนหัวประกอบด้วยพอร์ตต้นทาง พอร์ตปลายทาง และหมายเลขลำดับ
ขั้นตอนที่ 3: ส่วนต่างๆ จะถูกห่อหุ้มด้วยส่วนหัว IP ที่เลเยอร์เครือข่าย ส่วนหัว IP ประกอบด้วยที่อยู่ IP ต้นทาง/ปลายทาง
ขั้นตอนที่ 4: IP datagram จะถูกเพิ่มส่วนหัว MAC ที่ data link layer พร้อมด้วยที่อยู่ MAC ต้นทาง/ปลายทาง
ขั้นตอนที่ 5: เฟรมที่ห่อหุ้มจะถูกส่งไปยังเลเยอร์ทางกายภาพและส่งผ่านเครือข่ายในรูปแบบไบนารีบิต
ขั้นตอนที่ 6-10: เมื่ออุปกรณ์ B ได้รับบิตจากเครือข่าย อุปกรณ์จะดำเนินการกระบวนการยกเลิกการห่อหุ้ม ซึ่งเป็นการประมวลผลแบบย้อนกลับของกระบวนการห่อหุ้ม ส่วนหัวจะถูกลบออกทีละชั้น และในที่สุด อุปกรณ์ B ก็สามารถอ่านข้อมูลได้
เราต้องการเลเยอร์ในโมเดลเครือข่ายเพราะแต่ละเลเยอร์มุ่งเน้นไปที่ความรับผิดชอบของตัวเอง แต่ละเลเยอร์สามารถพึ่งพาส่วนหัวสำหรับคำแนะนำในการประมวลผล และไม่จำเป็นต้องทราบความหมายของข้อมูลจากเลเยอร์สุดท้าย
แผนภาพด้านล่างแสดงความแตกต่างระหว่าง ???????? - และ ???????? -
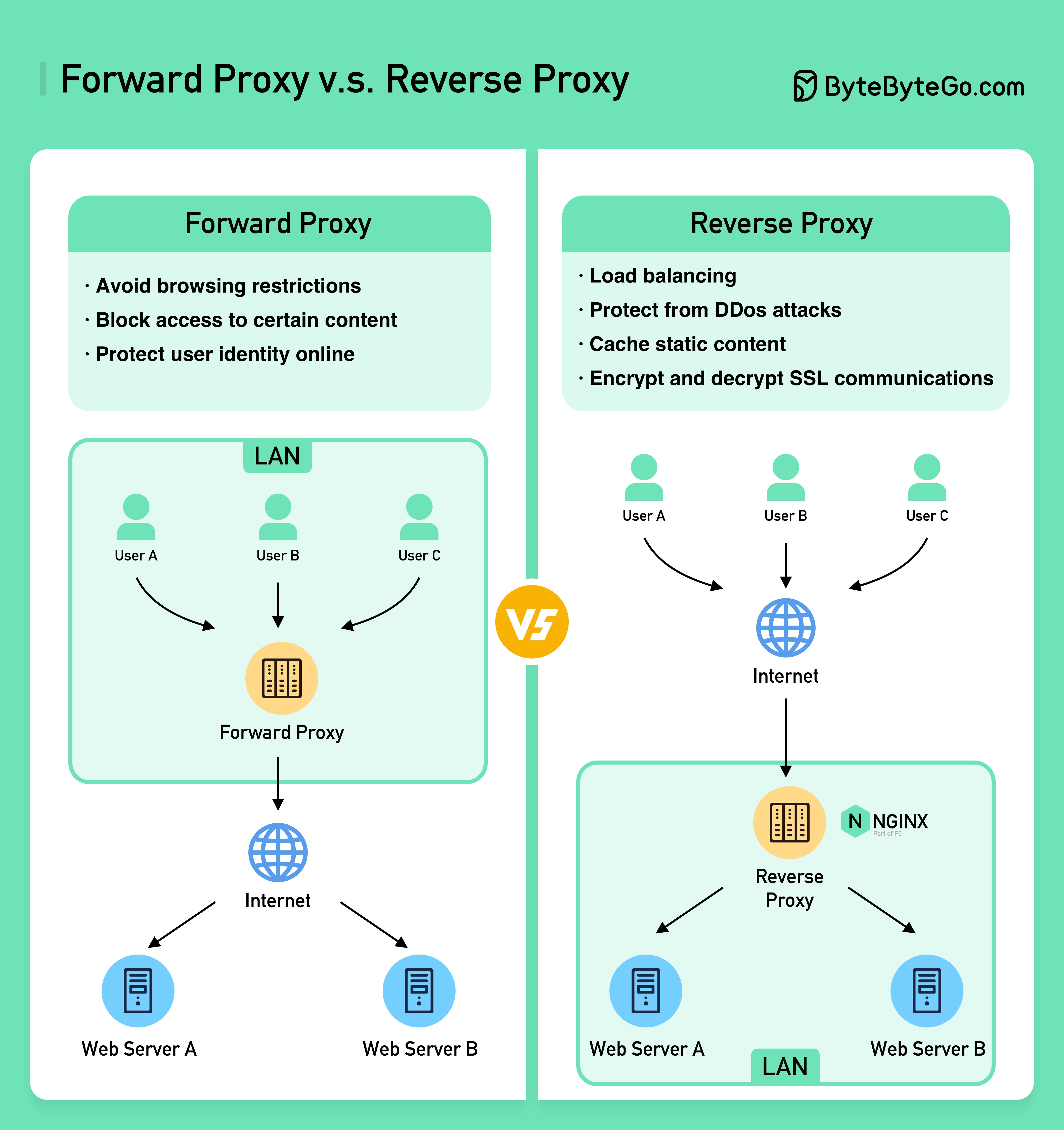
Forward Proxy คือเซิร์ฟเวอร์ที่อยู่ระหว่างอุปกรณ์ของผู้ใช้กับอินเทอร์เน็ต
โดยทั่วไปจะใช้ Forward Proxy สำหรับ:
Reverse Proxy คือเซิร์ฟเวอร์ที่ยอมรับคำขอจากไคลเอนต์ ส่งต่อคำขอไปยังเว็บเซิร์ฟเวอร์ และส่งผลลัพธ์กลับไปยังไคลเอนต์ราวกับว่าพร็อกซีเซิร์ฟเวอร์ได้ประมวลผลคำขอแล้ว
Reverse proxy เหมาะสำหรับ:
แผนภาพด้านล่างแสดงอัลกอริธึมทั่วไป 6 แบบ
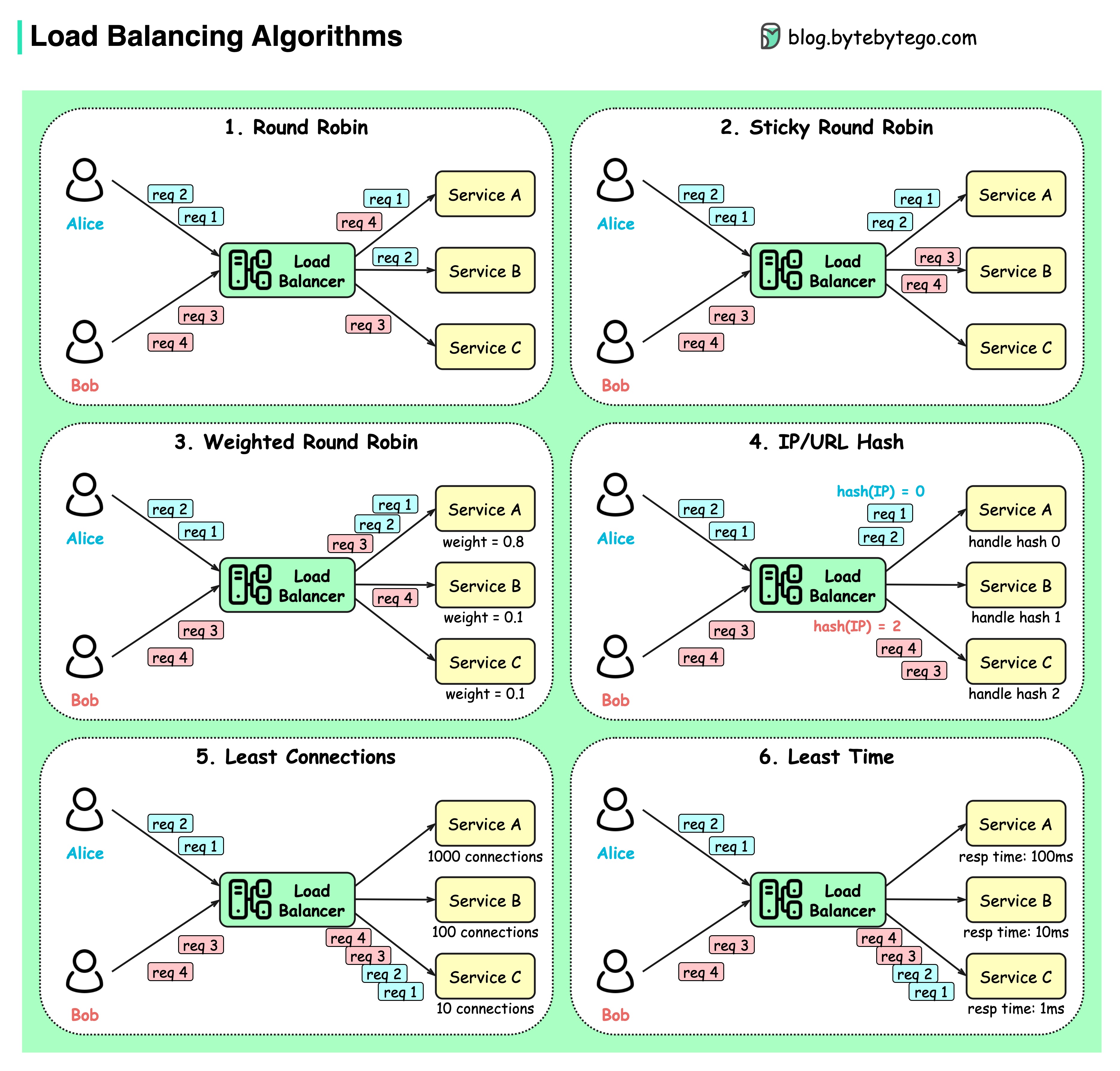
โรบินตัวกลม
คำขอของลูกค้าจะถูกส่งไปยังอินสแตนซ์บริการที่แตกต่างกันตามลำดับ โดยปกติแล้วบริการต่างๆ จะต้องเป็นแบบไร้สัญชาติ
โรบินตัวกลมเหนียว
นี่คือการปรับปรุงอัลกอริธึมแบบ Round-robin หากคำขอแรกของอลิซไปที่บริการ A คำขอต่อไปนี้จะไปยังบริการ A เช่นกัน
โรบินกลมถ่วงน้ำหนัก
ผู้ดูแลระบบสามารถระบุน้ำหนักของแต่ละบริการได้ รายการที่มีน้ำหนักสูงกว่าจะจัดการคำขอได้มากกว่ารายการอื่นๆ
กัญชา
อัลกอริทึมนี้ใช้ฟังก์ชันแฮชกับ IP หรือ URL ของคำขอที่เข้ามา คำขอจะถูกส่งไปยังอินสแตนซ์ที่เกี่ยวข้องตามผลลัพธ์ของฟังก์ชันแฮช
การเชื่อมต่อน้อยที่สุด
คำขอใหม่จะถูกส่งไปยังอินสแตนซ์บริการที่มีการเชื่อมต่อพร้อมกันน้อยที่สุด
เวลาตอบสนองน้อยที่สุด
คำขอใหม่จะถูกส่งไปยังอินสแตนซ์บริการด้วยเวลาตอบสนองที่เร็วที่สุด
แผนภาพด้านล่างแสดงการเปรียบเทียบ URL, URI และ URN
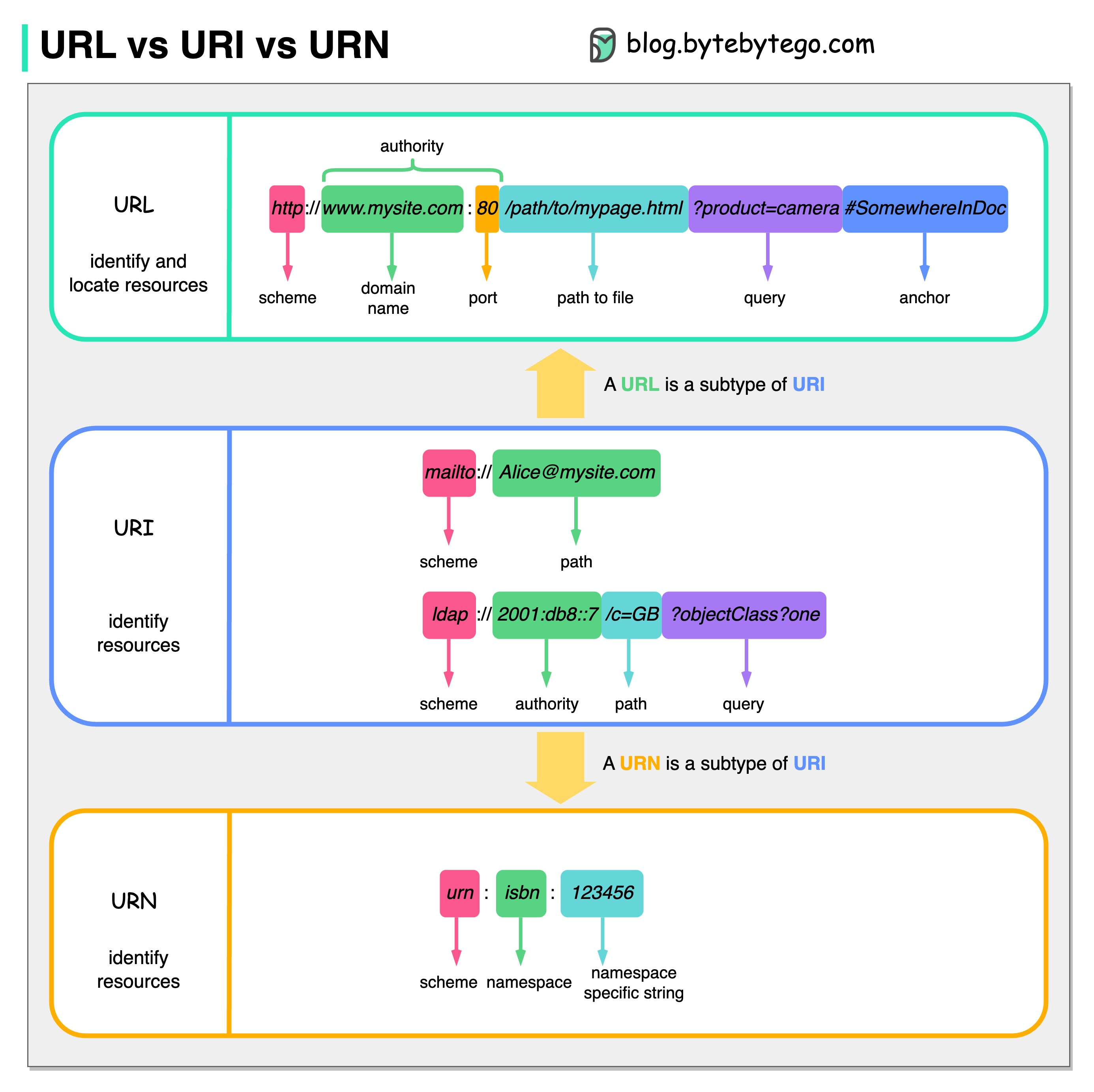
URI ย่อมาจาก Uniform Resource Identifier โดยจะระบุทรัพยากรเชิงตรรกะหรือทางกายภาพบนเว็บ URL และ URN เป็นประเภทย่อยของ URI URL ค้นหาทรัพยากร ในขณะที่ URN ตั้งชื่อทรัพยากร
URI ประกอบด้วยส่วนต่างๆ ดังต่อไปนี้: Scheme:[//authority]path[?query][#fragment]
URL ย่อมาจาก Uniform Resource Locator ซึ่งเป็นแนวคิดหลักของ HTTP เป็นที่อยู่ของแหล่งข้อมูลที่ไม่ซ้ำใครบนเว็บ สามารถใช้ได้กับโปรโตคอลอื่นเช่น FTP และ JDBC
URN ย่อมาจากชื่อทรัพยากรที่เหมือนกัน มันใช้รูปแบบโกศ ไม่สามารถใช้ URN เพื่อค้นหาทรัพยากรได้ ตัวอย่างง่ายๆ ที่ให้ไว้ในแผนภาพประกอบด้วยเนมสเปซและสตริงเฉพาะเนมสเปซ
หากคุณต้องการเรียนรู้รายละเอียดเพิ่มเติมเกี่ยวกับเรื่องนี้ ฉันขอแนะนำคำชี้แจงของ W3C
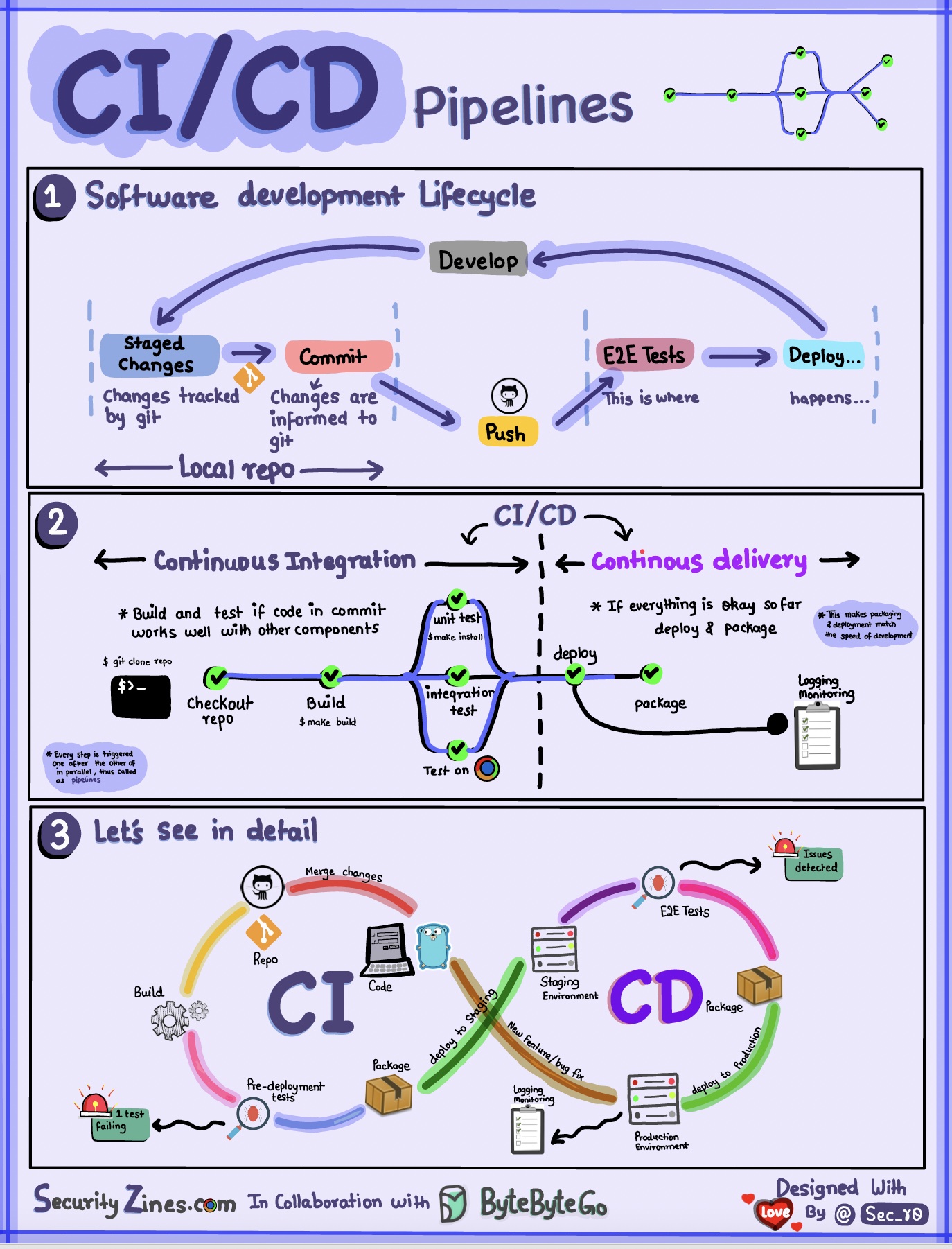
ส่วนที่ 1 - SDLC พร้อม CI/CD
วงจรชีวิตการพัฒนาซอฟต์แวร์ (SDLC) ประกอบด้วยขั้นตอนสำคัญหลายขั้นตอน: การพัฒนา การทดสอบ การปรับใช้ และการบำรุงรักษา CI/CD ดำเนินการและรวมขั้นตอนเหล่านี้โดยอัตโนมัติเพื่อให้สามารถเผยแพร่ได้รวดเร็วและเชื่อถือได้มากขึ้น
เมื่อโค้ดถูกส่งไปยังที่เก็บ git มันจะทริกเกอร์กระบวนการสร้างและทดสอบแบบอัตโนมัติ กรณีทดสอบแบบ end-to-end (e2e) ถูกเรียกใช้เพื่อตรวจสอบโค้ด หากการทดสอบผ่าน โค้ดจะถูกปรับใช้โดยอัตโนมัติในการจัดเตรียม/การผลิต หากพบปัญหา รหัสจะถูกส่งกลับไปยังฝ่ายพัฒนาเพื่อแก้ไขข้อบกพร่อง ระบบอัตโนมัตินี้ให้ผลตอบรับที่รวดเร็วแก่นักพัฒนาและลดความเสี่ยงของจุดบกพร่องในการใช้งานจริง
ส่วนที่ 2 - ความแตกต่างระหว่าง CI และ CD
การบูรณาการอย่างต่อเนื่อง (CI) ทำให้กระบวนการสร้าง ทดสอบ และผสานเป็นไปโดยอัตโนมัติ โดยจะทำการทดสอบทุกครั้งที่โค้ดมุ่งมั่นที่จะตรวจพบปัญหาการรวมระบบตั้งแต่เนิ่นๆ สิ่งนี้กระตุ้นให้เกิดการคอมมิตโค้ดบ่อยครั้งและการตอบรับอย่างรวดเร็ว
การจัดส่งแบบต่อเนื่อง (CD) ทำให้กระบวนการเผยแพร่เป็นแบบอัตโนมัติ เช่น การเปลี่ยนแปลงโครงสร้างพื้นฐานและการปรับใช้ ช่วยให้มั่นใจได้ว่าซอฟต์แวร์สามารถเผยแพร่ได้อย่างน่าเชื่อถือตลอดเวลาผ่านขั้นตอนการทำงานอัตโนมัติ ซีดียังอาจทำให้ขั้นตอนการทดสอบและการอนุมัติด้วยตนเองที่จำเป็นก่อนการใช้งานจริงเป็นไปโดยอัตโนมัติ
ส่วนที่ 3 - ไปป์ไลน์ CI/CD
ไปป์ไลน์ CI/CD ทั่วไปมีหลายขั้นตอนที่เชื่อมต่อกัน:
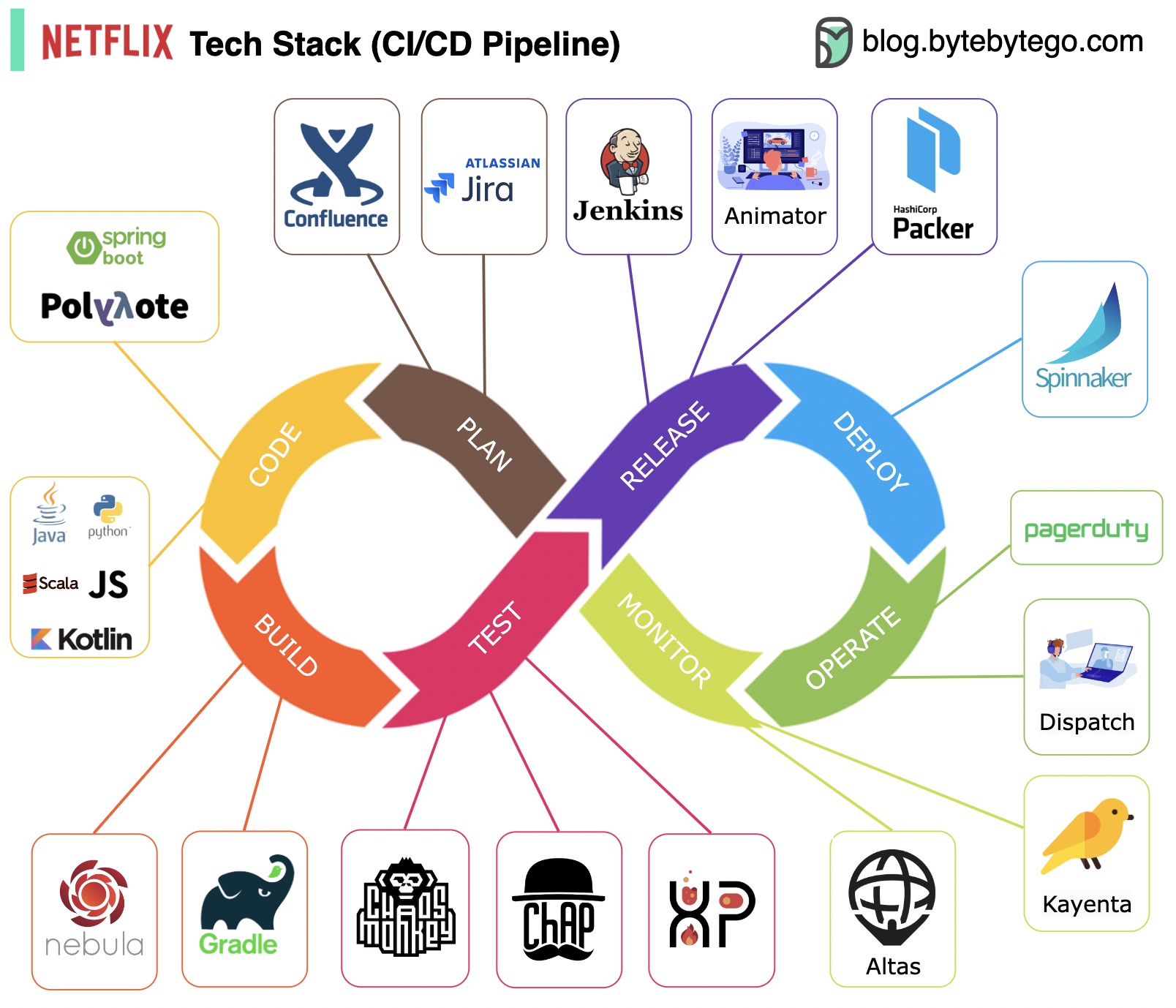
การวางแผน: Netflix Engineering ใช้ JIRA ในการวางแผนและ Confluence สำหรับเอกสาร
การเขียนโค้ด: Java เป็นภาษาการเขียนโปรแกรมหลักสำหรับบริการแบ็กเอนด์ ในขณะที่ภาษาอื่นๆ ใช้สำหรับกรณีการใช้งานที่แตกต่างกัน
โครงสร้าง: Gradle ส่วนใหญ่จะใช้สำหรับการสร้าง และปลั๊กอิน Gradle ถูกสร้างขึ้นเพื่อรองรับกรณีการใช้งานที่หลากหลาย
การบรรจุ: แพ็คเกจและการขึ้นต่อกันจะถูกบรรจุลงใน Amazon Machine Image (AMI) เพื่อการเปิดตัว
การทดสอบ: การทดสอบเน้นย้ำถึงการมุ่งเน้นของวัฒนธรรมการผลิตในการสร้างเครื่องมือที่ไม่เป็นระเบียบ
การปรับใช้: Netflix ใช้ Spinnaker ที่สร้างขึ้นเองสำหรับการปรับใช้การเปิดตัว Canary
การตรวจสอบ: ตัวชี้วัดการตรวจสอบจะรวมศูนย์ไว้ใน Atlas และ Kayenta ใช้เพื่อตรวจจับความผิดปกติ
รายงานเหตุการณ์: เหตุการณ์จะถูกส่งตามลำดับความสำคัญ และใช้ PagerDuty สำหรับการจัดการเหตุการณ์
รูปแบบสถาปัตยกรรมเหล่านี้เป็นหนึ่งในรูปแบบที่ใช้กันมากที่สุดในการพัฒนาแอพ ไม่ว่าจะบนแพลตฟอร์ม iOS หรือ Android นักพัฒนาได้แนะนำให้พวกเขาเอาชนะข้อจำกัดของรูปแบบก่อนหน้านี้ แล้วมันแตกต่างกันอย่างไร?
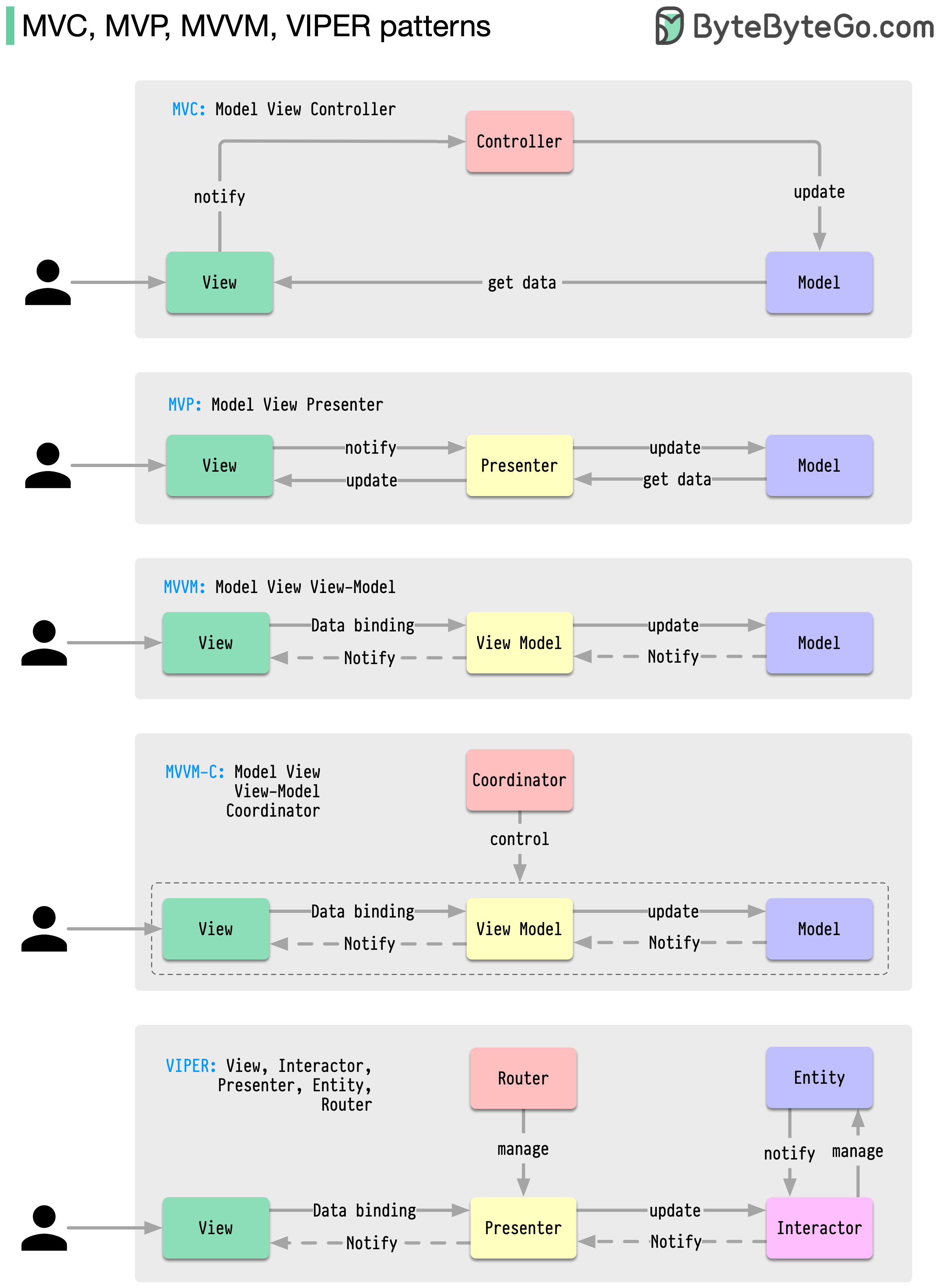
รูปแบบเป็นวิธีการแก้ปัญหาการออกแบบทั่วไปที่สามารถนำกลับมาใช้ใหม่ได้ ส่งผลให้กระบวนการพัฒนาราบรื่นและมีประสิทธิภาพมากขึ้น ทำหน้าที่เป็นพิมพ์เขียวสำหรับการสร้างโครงสร้างซอฟต์แวร์ที่ดีขึ้น นี่คือรูปแบบยอดนิยมบางส่วน:

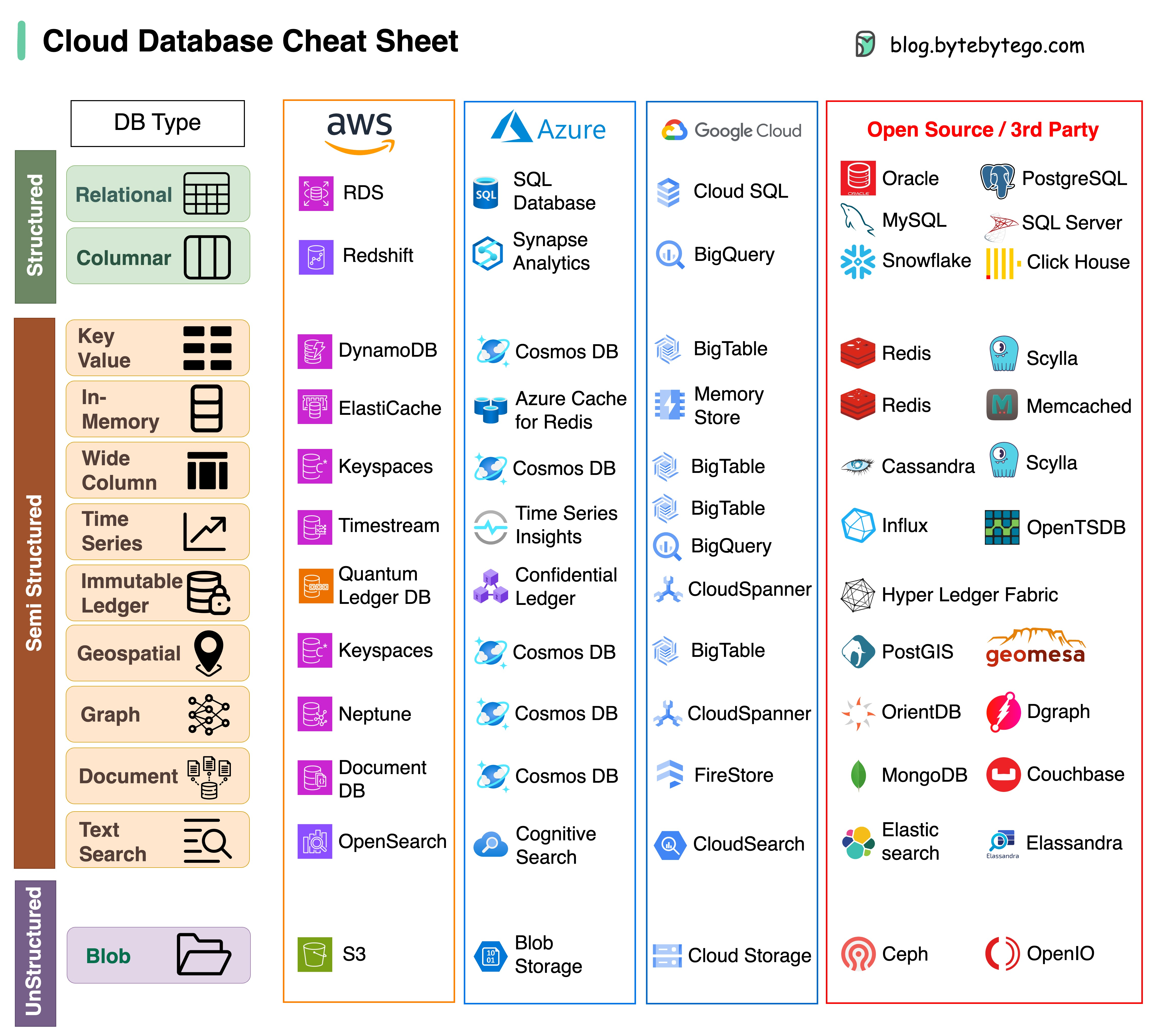
การเลือกฐานข้อมูลที่เหมาะสมสำหรับโครงการของคุณถือเป็นงานที่ซับซ้อน ตัวเลือกฐานข้อมูลจำนวนมาก ซึ่งแต่ละตัวเลือกเหมาะสมกับกรณีการใช้งานที่แตกต่างกัน อาจทำให้การตัดสินใจล่าช้าได้อย่างรวดเร็ว
เราหวังว่าเอกสารสรุปนี้จะให้คำแนะนำในระดับสูงเพื่อระบุบริการที่เหมาะสมซึ่งสอดคล้องกับความต้องการของโครงการของคุณและหลีกเลี่ยงข้อผิดพลาดที่อาจเกิดขึ้น
หมายเหตุ: Google มีเอกสารประกอบที่จำกัดสำหรับกรณีการใช้งานฐานข้อมูลของตน แม้ว่าเราจะพยายามอย่างเต็มที่เพื่อดูว่ามีอะไรว่างบ้างและได้ตัวเลือกที่ดีที่สุดแล้ว แต่บางรายการอาจจำเป็นต้องมีความแม่นยำมากขึ้น
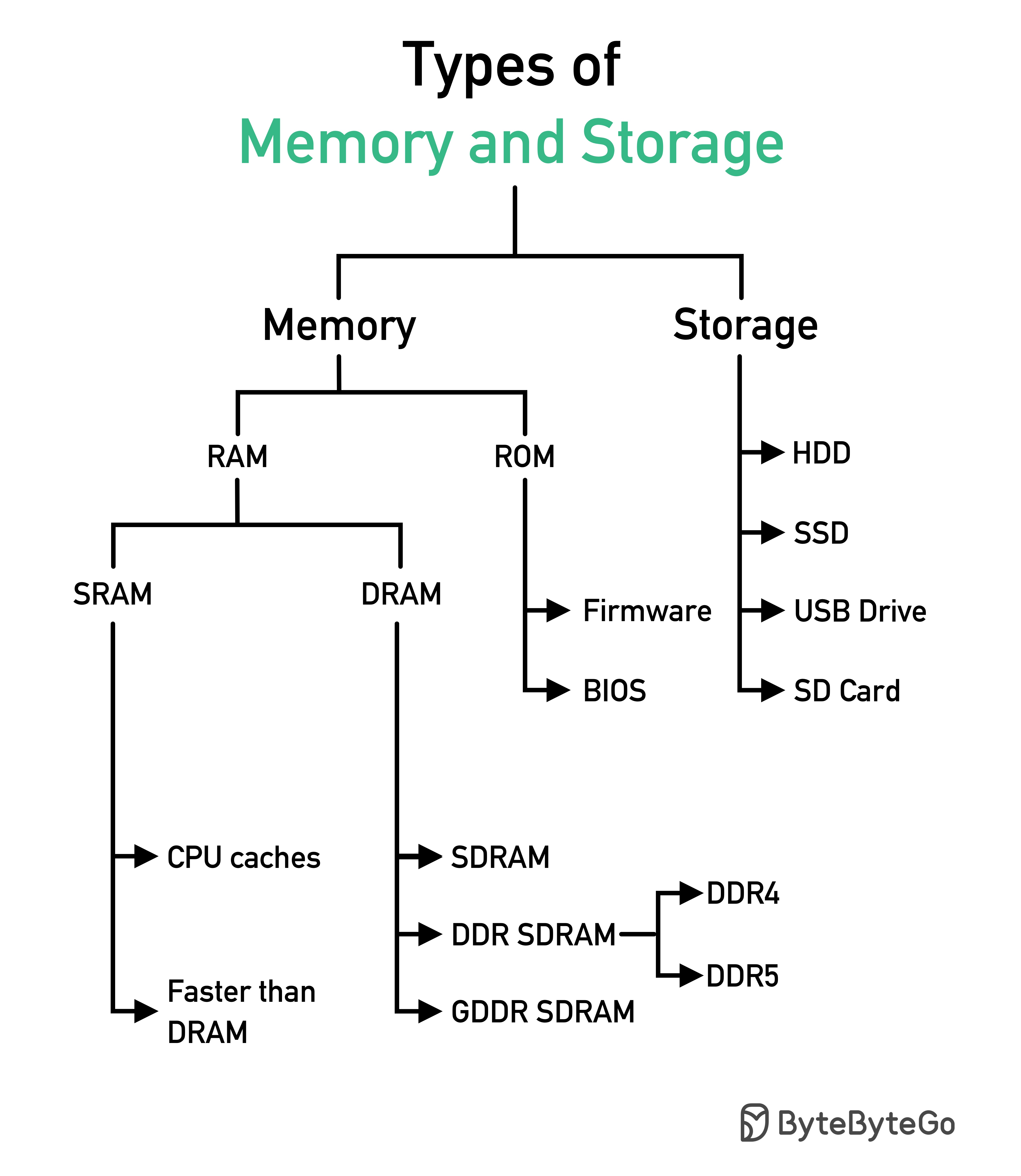
คำตอบจะแตกต่างกันไปขึ้นอยู่กับกรณีการใช้งานของคุณ ข้อมูลสามารถจัดทำดัชนีในหน่วยความจำหรือบนดิสก์ ในทำนองเดียวกัน รูปแบบข้อมูลจะแตกต่างกันไป เช่น ตัวเลข สตริง พิกัดทางภูมิศาสตร์ ฯลฯ ระบบอาจมีการเขียนจำนวนมากหรือการอ่านอย่างหนัก ปัจจัยทั้งหมดเหล่านี้ส่งผลต่อการเลือกรูปแบบดัชนีฐานข้อมูลของคุณ
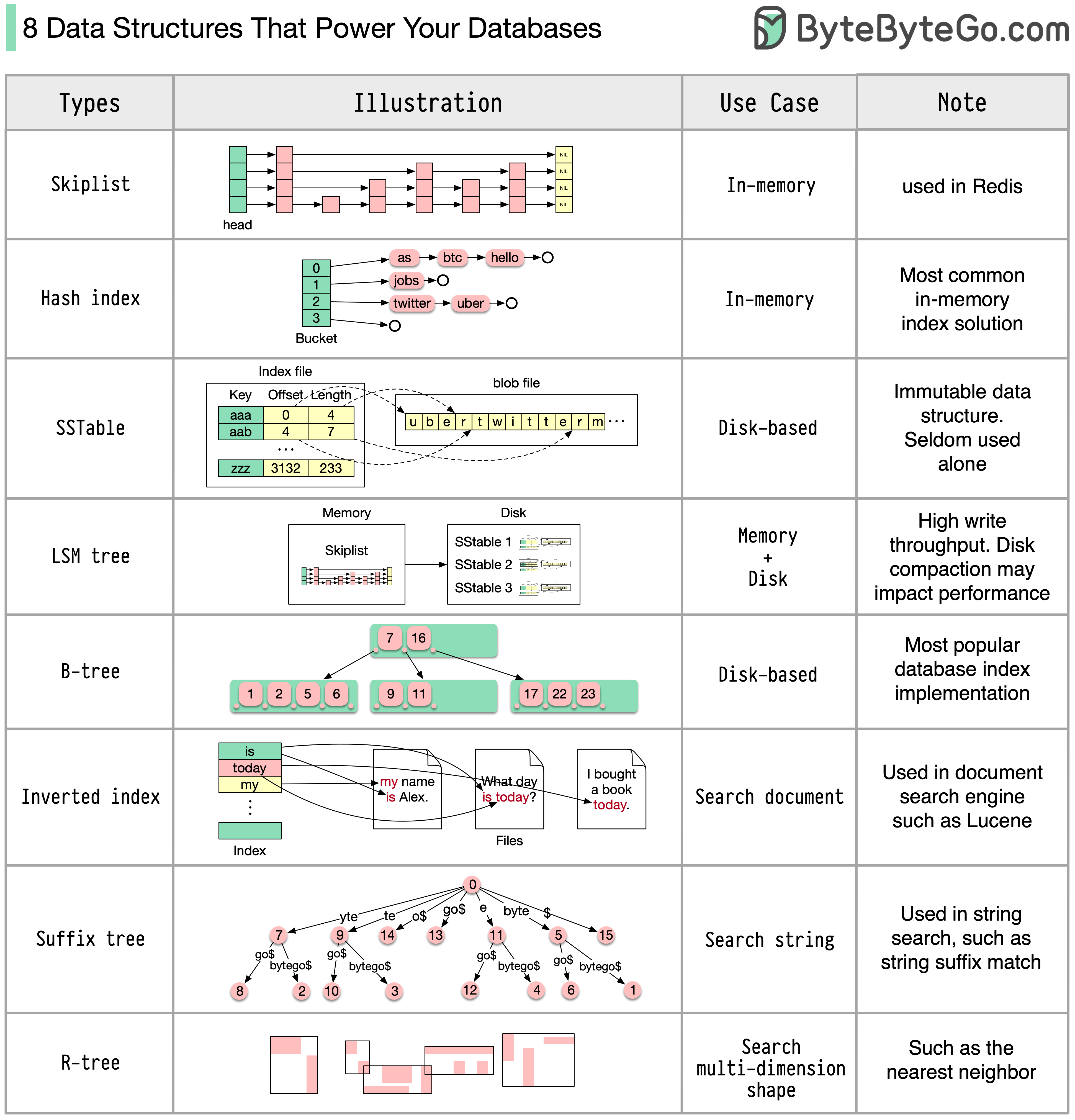
ต่อไปนี้คือโครงสร้างข้อมูลที่ได้รับความนิยมมากที่สุดบางส่วนที่ใช้สำหรับการจัดทำดัชนีข้อมูล:
แผนภาพด้านล่างแสดงกระบวนการ โปรดทราบว่าสถาปัตยกรรมสำหรับฐานข้อมูลที่แตกต่างกันจะแตกต่างกัน แผนภาพแสดงการออกแบบทั่วไปบางอย่าง
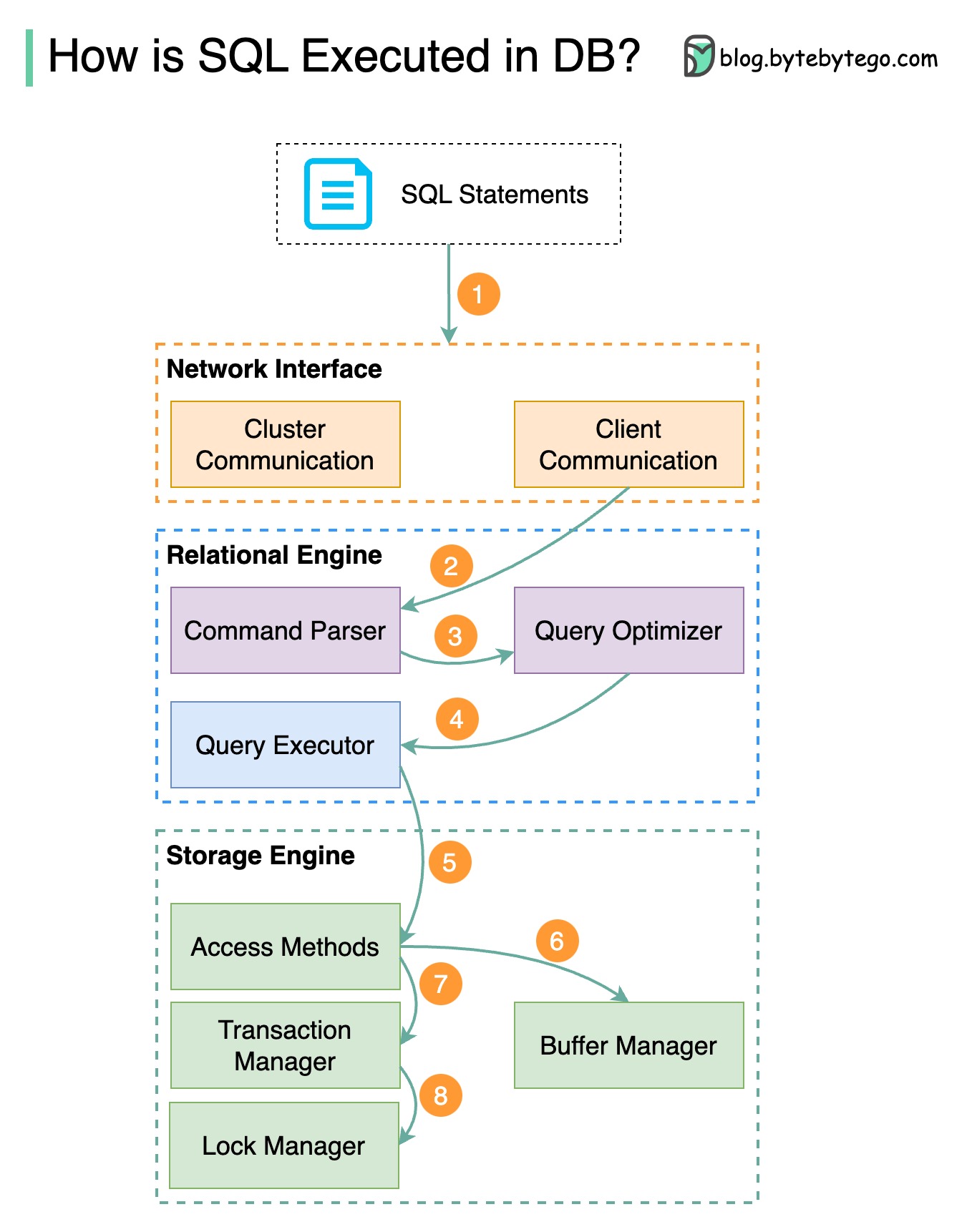
ขั้นตอนที่ 1 - คำสั่ง SQL จะถูกส่งไปยังฐานข้อมูลผ่าน Transport Layer Protocol (egTCP)
ขั้นตอนที่ 2 - คำสั่ง SQL จะถูกส่งไปยังตัวแยกวิเคราะห์คำสั่ง ซึ่งจะต้องผ่านการวิเคราะห์ทางวากยสัมพันธ์และความหมาย และแผนผังคิวรีจะถูกสร้างขึ้นในภายหลัง
ขั้นตอนที่ 3 - แผนผังแบบสอบถามจะถูกส่งไปยังเครื่องมือเพิ่มประสิทธิภาพ เครื่องมือเพิ่มประสิทธิภาพจะสร้างแผนการดำเนินการ
ขั้นตอนที่ 4 - แผนการดำเนินการจะถูกส่งไปยังผู้ดำเนินการ ผู้ดำเนินการดึงข้อมูลจากการดำเนินการ
ขั้นตอนที่ 5 - วิธีการเข้าถึงจะให้ตรรกะในการดึงข้อมูลที่จำเป็นสำหรับการดำเนินการ โดยดึงข้อมูลจากกลไกการจัดเก็บข้อมูล
ขั้นตอนที่ 6 - วิธีการเข้าถึงจะตัดสินว่าคำสั่ง SQL เป็นแบบอ่านอย่างเดียวหรือไม่ หากแบบสอบถามเป็นแบบอ่านอย่างเดียว (คำสั่ง SELECT) แบบสอบถามจะถูกส่งไปยังตัวจัดการบัฟเฟอร์เพื่อประมวลผลต่อไป ตัวจัดการบัฟเฟอร์ค้นหาข้อมูลในแคชหรือไฟล์ข้อมูล
ขั้นตอนที่ 7 - หากคำสั่งนั้นเป็น UPDATE หรือ INSERT คำสั่งนั้นจะถูกส่งไปยังผู้จัดการธุรกรรมเพื่อดำเนินการต่อไป
ขั้นตอนที่ 8 - ในระหว่างการทำธุรกรรม ข้อมูลจะอยู่ในโหมดล็อค สิ่งนี้รับประกันโดยผู้จัดการล็อค นอกจากนี้ยังรับประกันคุณสมบัติ ACID ของธุรกรรมอีกด้วย
ทฤษฎีบท CAP เป็นหนึ่งในคำศัพท์ที่มีชื่อเสียงที่สุดในสาขาวิทยาการคอมพิวเตอร์ แต่ฉันพนันได้เลยว่านักพัฒนาแต่ละคนมีความเข้าใจที่แตกต่างกัน ลองตรวจสอบว่ามันคืออะไรและเหตุใดจึงทำให้เกิดความสับสน
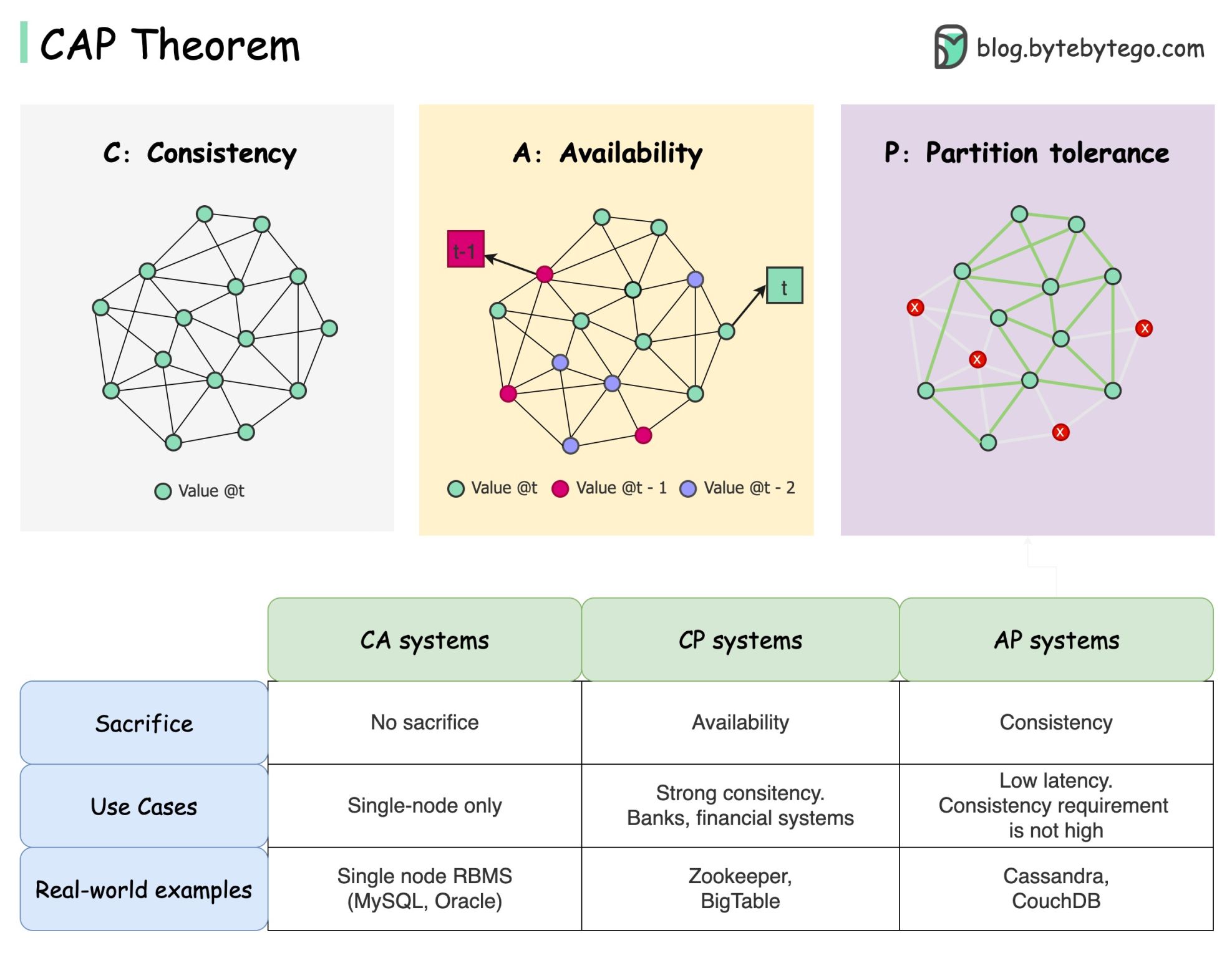
ทฤษฎีบท CAP ระบุว่าระบบแบบกระจายไม่สามารถให้การรับประกันมากกว่าสองในสามข้อนี้พร้อมกันได้
ความสอดคล้อง : ความสอดคล้องหมายถึงไคลเอนต์ทั้งหมดเห็นข้อมูลเดียวกันในเวลาเดียวกันไม่ว่าพวกเขาจะเชื่อมต่อกับโหนดใดก็ตาม
ความพร้อมใช้งาน : ความพร้อมใช้งานหมายความว่าไคลเอนต์ใด ๆ ที่ร้องขอข้อมูลจะได้รับการตอบกลับแม้ว่าบางโหนดจะหยุดทำงานก็ตาม
Partition Tolerance : พาร์ติชันบ่งชี้ว่าการสื่อสารขาดระหว่างสองโหนด ความทนทานต่อพาร์ติชั่นหมายความว่าระบบยังคงทำงานต่อไปแม้จะมีพาร์ติชั่นเครือข่ายก็ตาม
สูตร "2 จาก 3" อาจมีประโยชน์ แต่การลดความซับซ้อนนี้อาจทำให้เข้าใจผิด
การเลือกฐานข้อมูลไม่ใช่เรื่องง่าย การพิสูจน์ทางเลือกของเราตามทฤษฎีบท CAP เพียงอย่างเดียวนั้นไม่เพียงพอ ตัวอย่างเช่น บริษัทไม่เลือก Cassandra สำหรับแอปพลิเคชันแชทเพียงเพราะเป็นระบบ AP มีรายการคุณสมบัติที่ดีที่ทำให้ Cassandra เป็นตัวเลือกที่ต้องการสำหรับการจัดเก็บข้อความแชท เราจำเป็นต้องขุดลึกลงไป
“CAP ห้ามมิให้มีเพียงส่วนเล็กๆ ของพื้นที่การออกแบบ: ความพร้อมใช้งานที่สมบูรณ์แบบและความสม่ำเสมอเมื่อมีพาร์ติชัน ซึ่งหาได้ยาก” อ้างจากบทความ: CAP สิบสองปีต่อมา: “กฎ” มีการเปลี่ยนแปลงอย่างไร
ทฤษฎีบทนี้มีความพร้อมใช้งานและความสม่ำเสมอประมาณ 100% การสนทนาที่สมจริงยิ่งขึ้นคือการแลกเปลี่ยนระหว่างเวลาแฝงและความสม่ำเสมอเมื่อไม่มีพาร์ติชันเครือข่าย ดูทฤษฎีบท PACELC สำหรับรายละเอียดเพิ่มเติม
ทฤษฎีบท CAP มีประโยชน์จริงหรือ?
ฉันคิดว่ามันยังมีประโยชน์เพราะมันเปิดใจของเราไปสู่การอภิปรายเรื่องการแลกเปลี่ยน แต่มันเป็นเพียงส่วนหนึ่งของเรื่องราวเท่านั้น เราจำเป็นต้องเจาะลึกลงไปเมื่อเลือกฐานข้อมูลที่ถูกต้อง
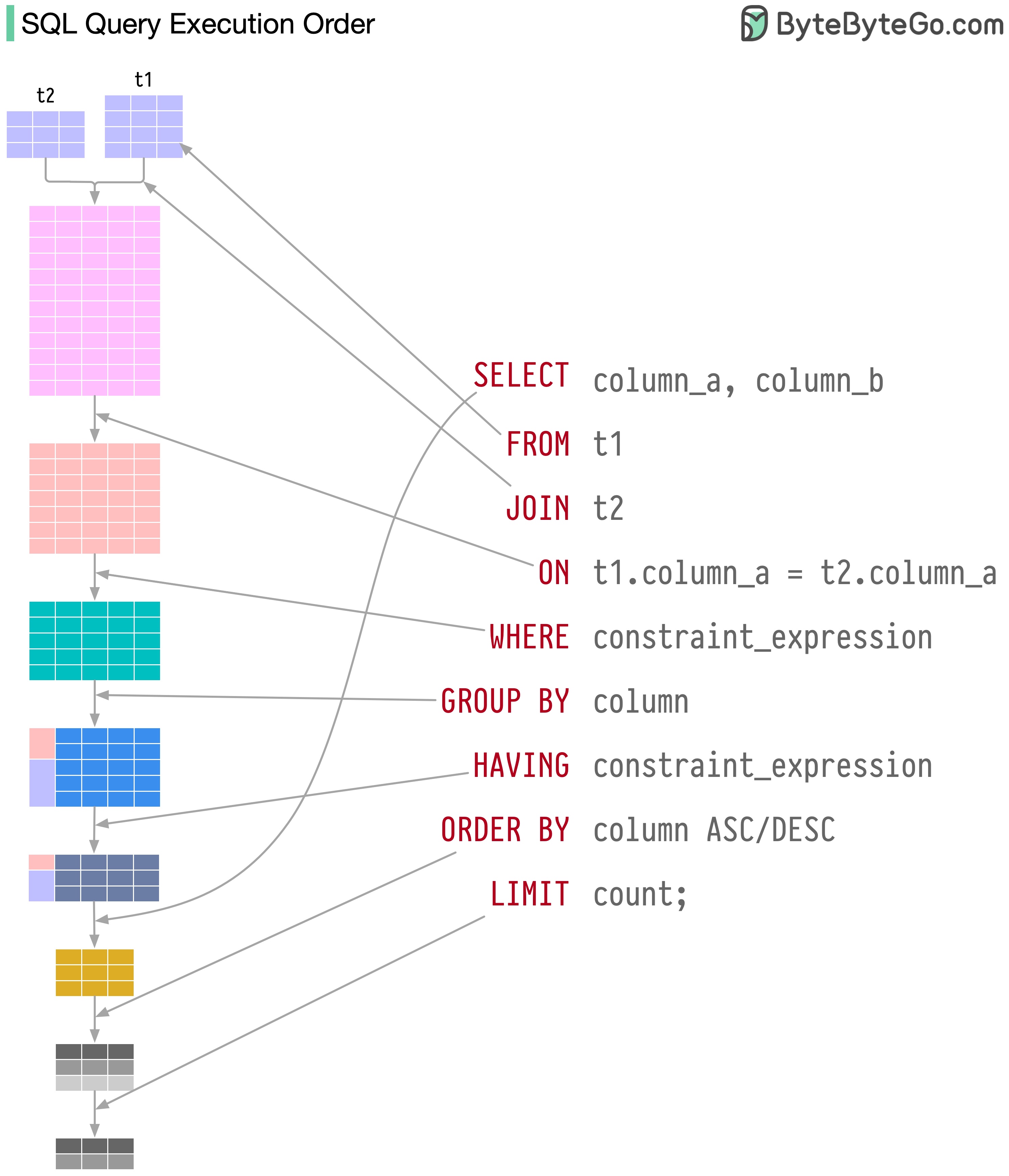
คำสั่ง SQL จะถูกดำเนินการโดยระบบฐานข้อมูลในหลายขั้นตอน รวมถึง:
การดำเนินการของ SQL มีความซับซ้อนสูงและเกี่ยวข้องกับข้อพิจารณาหลายประการ เช่น:
ในปี 1986 SQL (Structured Query Language) ได้กลายเป็นมาตรฐาน ในอีก 40 ปีข้างหน้า ภาษาดังกล่าวได้กลายเป็นภาษาที่โดดเด่นสำหรับระบบการจัดการฐานข้อมูลเชิงสัมพันธ์ การอ่านมาตรฐานล่าสุด (ANSI SQL 2016) อาจใช้เวลานาน ฉันจะเรียนรู้มันได้อย่างไร?
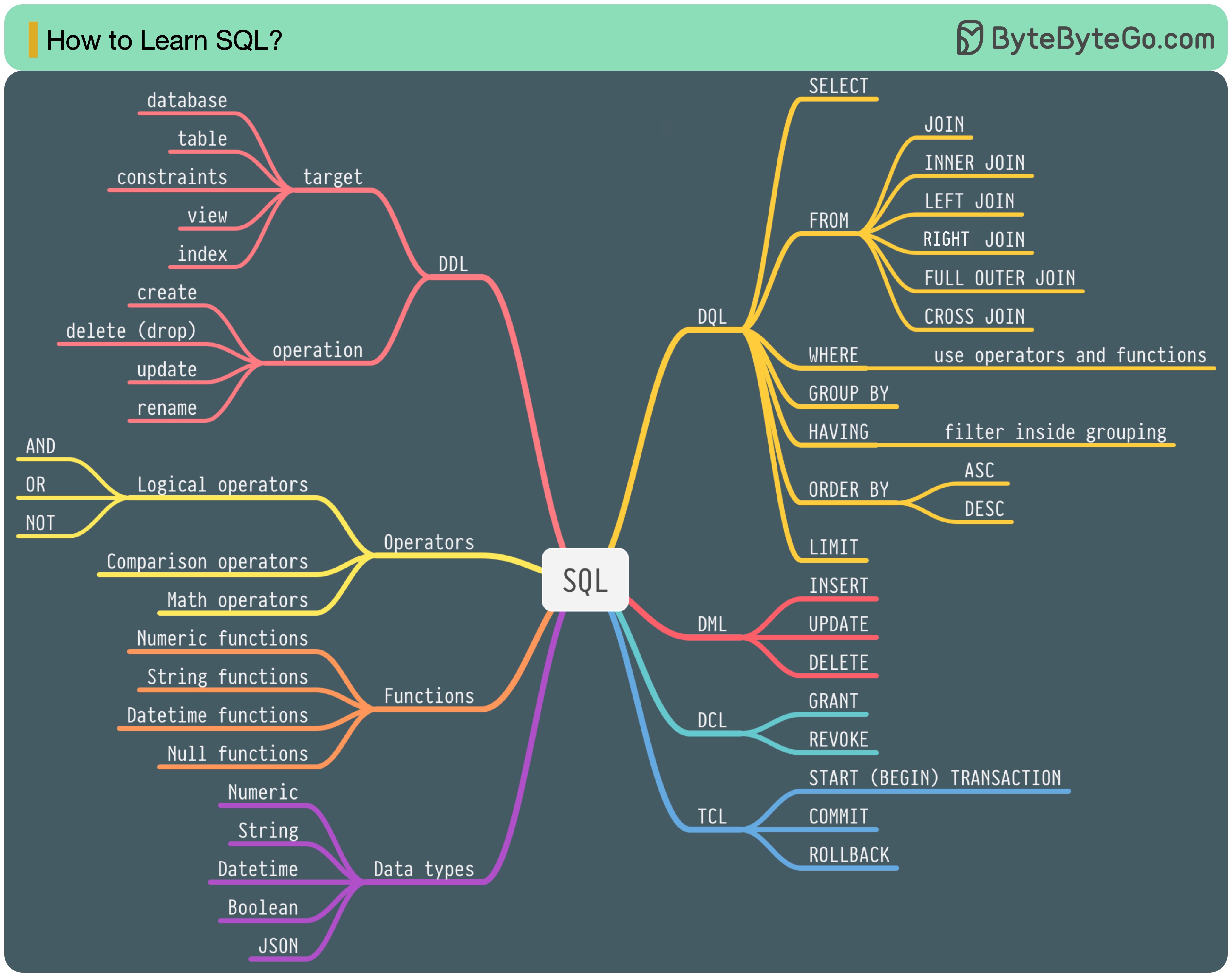
ภาษา SQL มี 5 ส่วนประกอบ:
สำหรับวิศวกรแบ็คเอนด์ คุณอาจต้องรู้ข้อมูลส่วนใหญ่ ในฐานะนักวิเคราะห์ข้อมูล คุณอาจจำเป็นต้องมีความเข้าใจ DQL เป็นอย่างดี เลือกหัวข้อที่เกี่ยวข้องกับคุณมากที่สุด
แผนภาพนี้แสดงตำแหน่งที่เราแคชข้อมูลในสถาปัตยกรรมทั่วไป
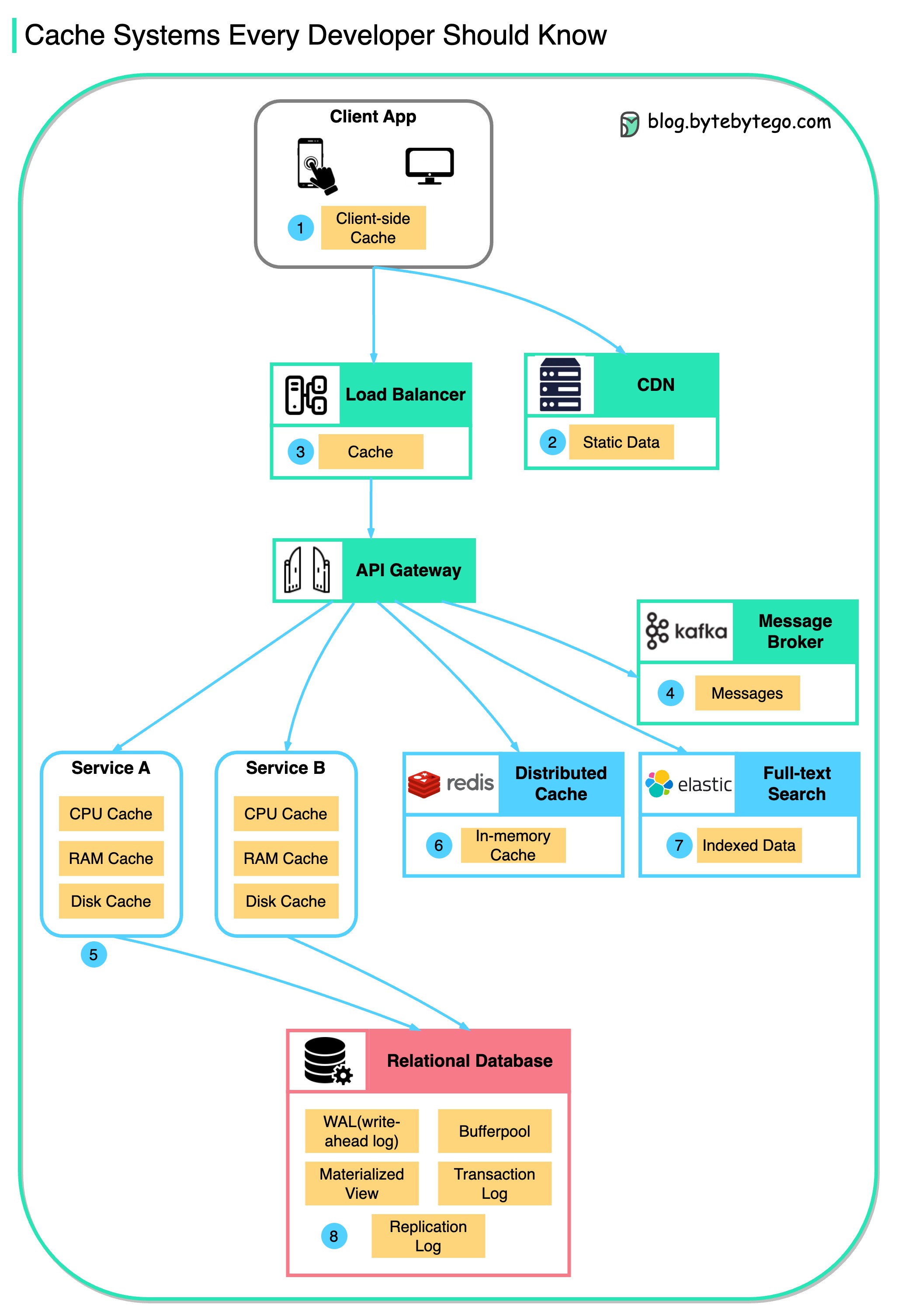
มี หลายชั้น ตามการไหล
มีสาเหตุหลักอยู่ 3 ประการดังแสดงในแผนภาพด้านล่าง
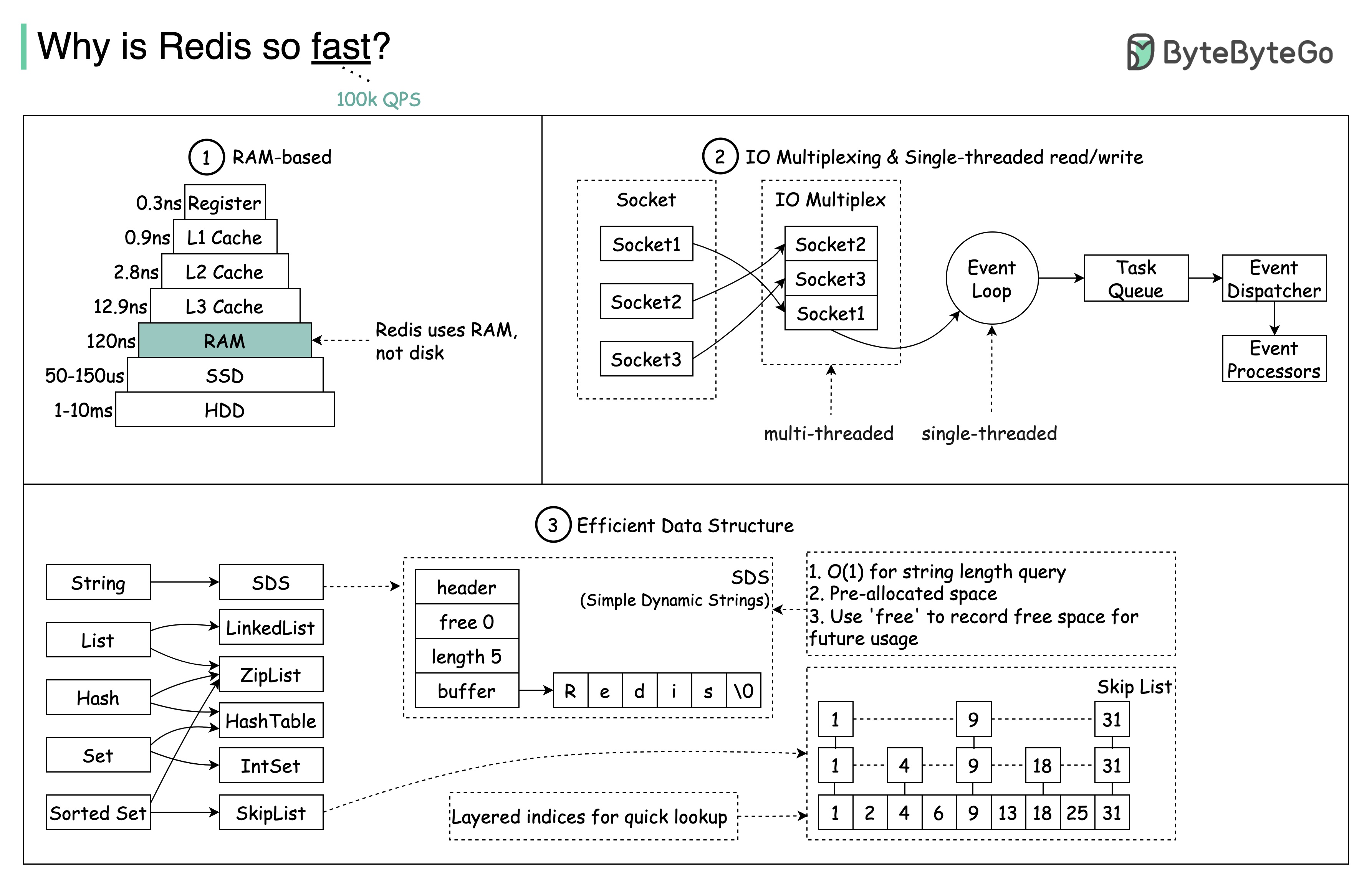
คำถาม: พื้นที่จัดเก็บในหน่วยความจำยอดนิยมอีกแห่งคือ Memcached คุณรู้ความแตกต่างระหว่าง Redis และ Memcached หรือไม่?
คุณอาจสังเกตเห็นสไตล์ของแผนภาพนี้แตกต่างจากโพสต์ก่อนหน้าของฉัน โปรดแจ้งให้เราทราบว่าคุณชอบอันไหน
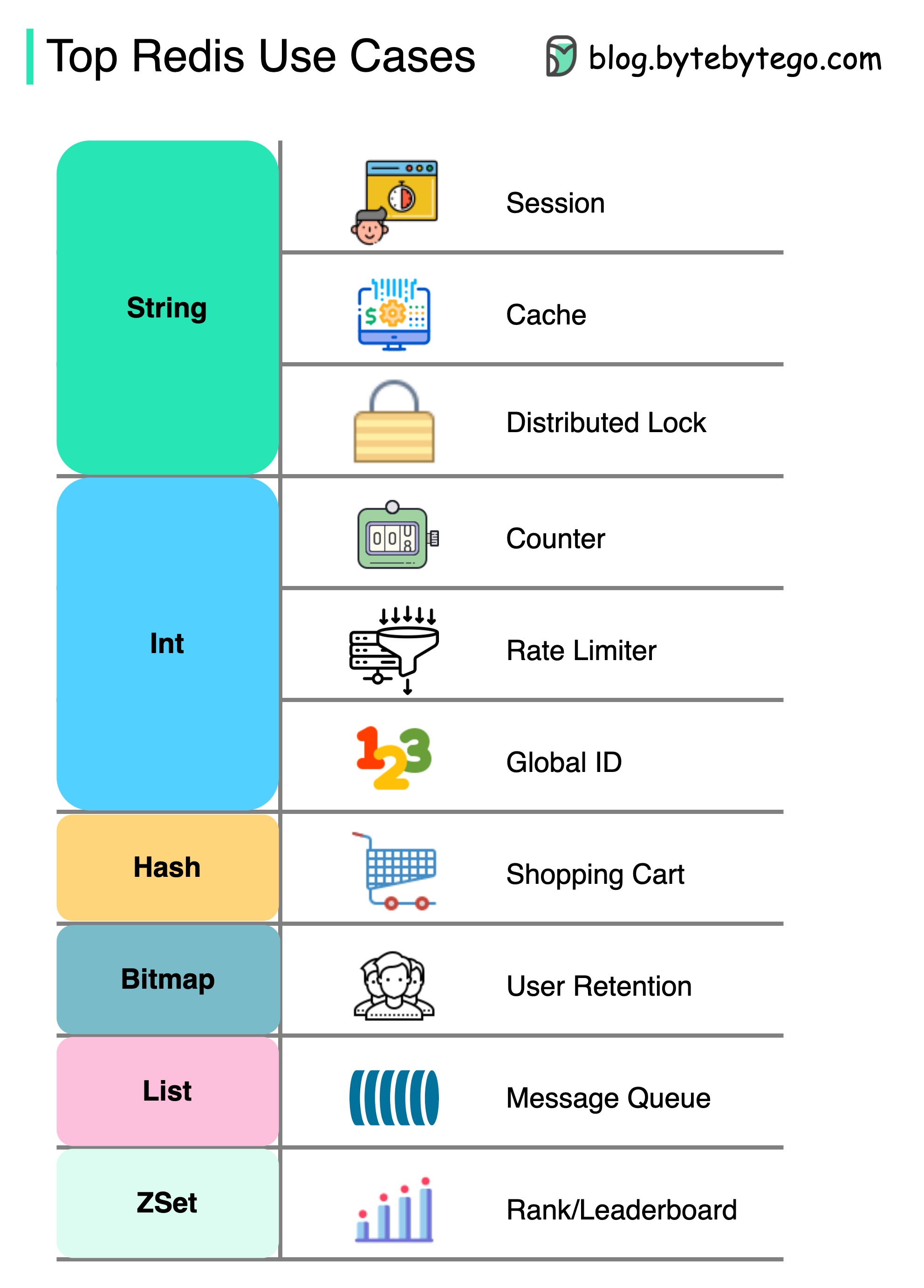
มี Redis มากกว่าแค่แคช
Redis สามารถใช้ในสถานการณ์ที่หลากหลายดังแสดงในแผนภาพ
การประชุม
เราสามารถใช้ REDIS เพื่อแบ่งปันข้อมูลเซสชันผู้ใช้ระหว่างบริการที่แตกต่างกัน
แคช
เราสามารถใช้ REDIS กับแคชวัตถุหรือหน้าโดยเฉพาะอย่างยิ่งสำหรับข้อมูลฮอตสปอต
ล็อคแบบกระจาย
เราสามารถใช้สตริง Redis เพื่อรับล็อคระหว่างบริการแบบกระจาย
เคาน์เตอร์
เราสามารถนับจำนวนไลค์หรือจำนวนการอ่านสำหรับบทความ
ตัว จำกัด อัตรา
เราสามารถใช้ตัว จำกัด อัตราสำหรับผู้ใช้ IP บางคน
เครื่องกำเนิด ID ทั่วโลก
เราสามารถใช้ Redis Int สำหรับ Global ID
ตะกร้าสินค้า
เราสามารถใช้ Redis Hash เพื่อแสดงคู่คีย์-ค่าในตะกร้าสินค้า
คำนวณการเก็บรักษาผู้ใช้
เราสามารถใช้บิตแมปเพื่อแสดงการเข้าสู่ระบบของผู้ใช้ทุกวันและคำนวณการเก็บรักษาผู้ใช้
คิวข้อความ
เราสามารถใช้รายการสำหรับคิวข้อความ
การจัดอันดับ
เราสามารถใช้ ZSET เพื่อจัดเรียงบทความ
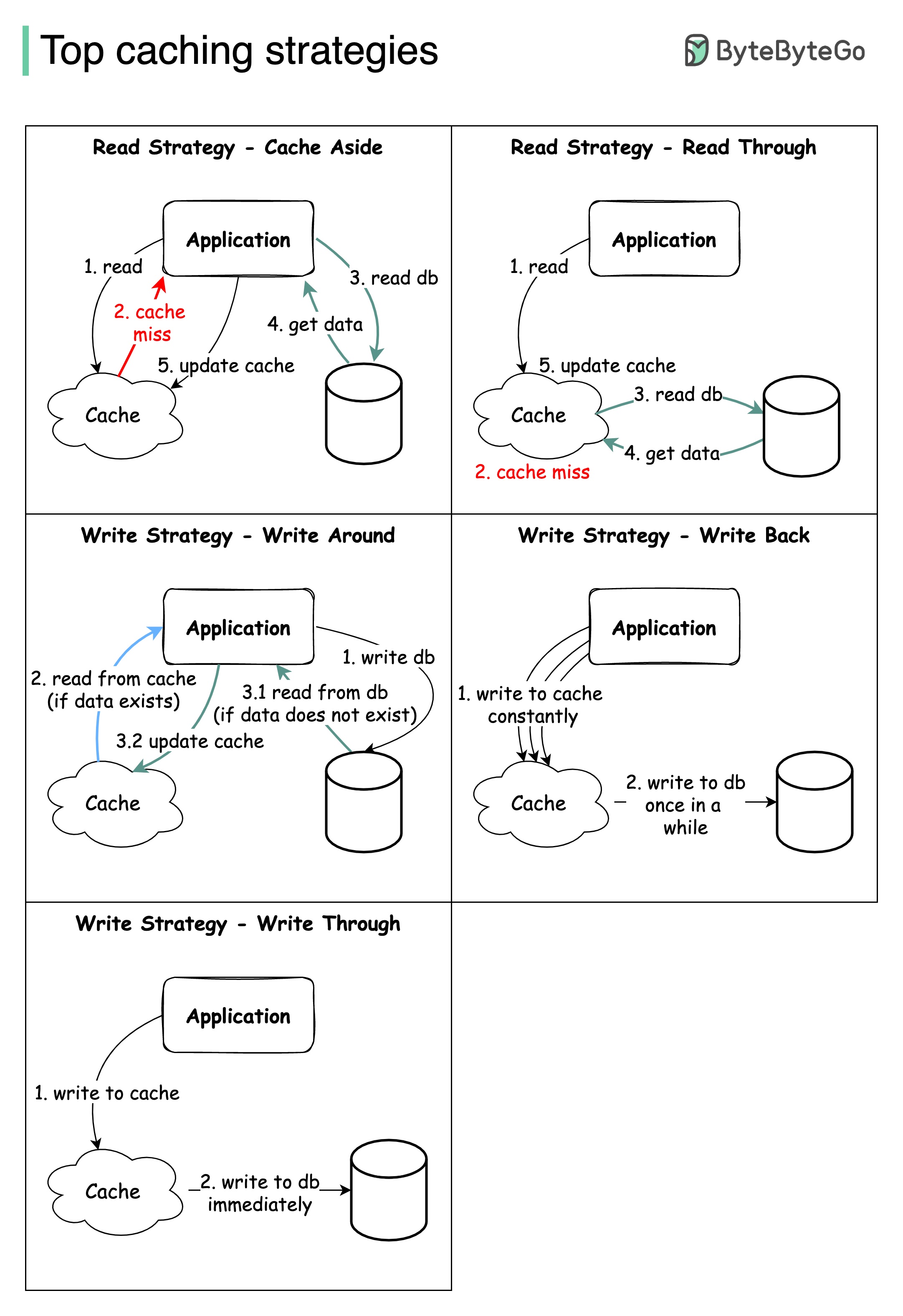
การออกแบบระบบขนาดใหญ่มักจะต้องพิจารณาอย่างรอบคอบเกี่ยวกับการแคช ด้านล่างนี้เป็นกลยุทธ์การแคชห้าที่ใช้บ่อย
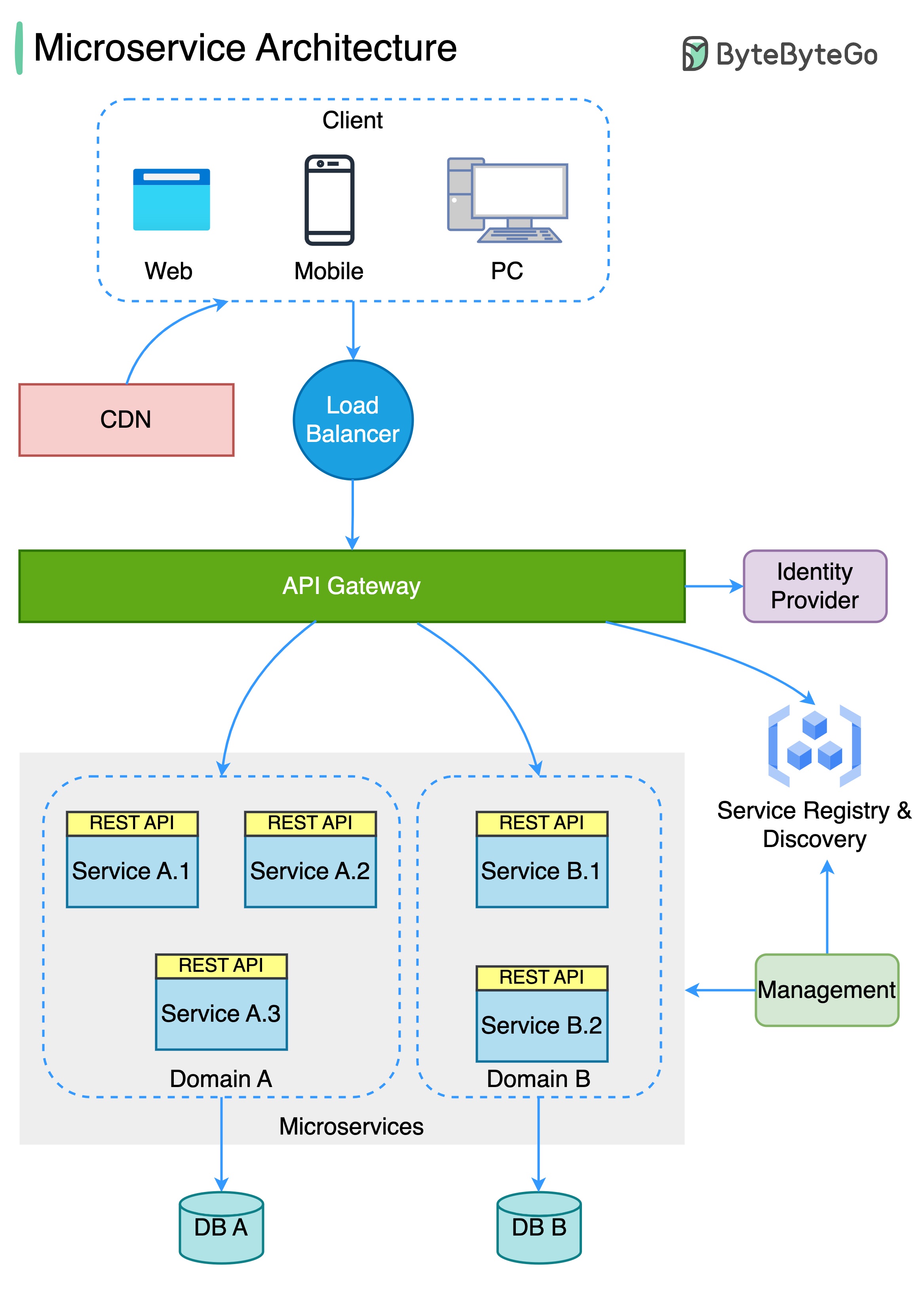
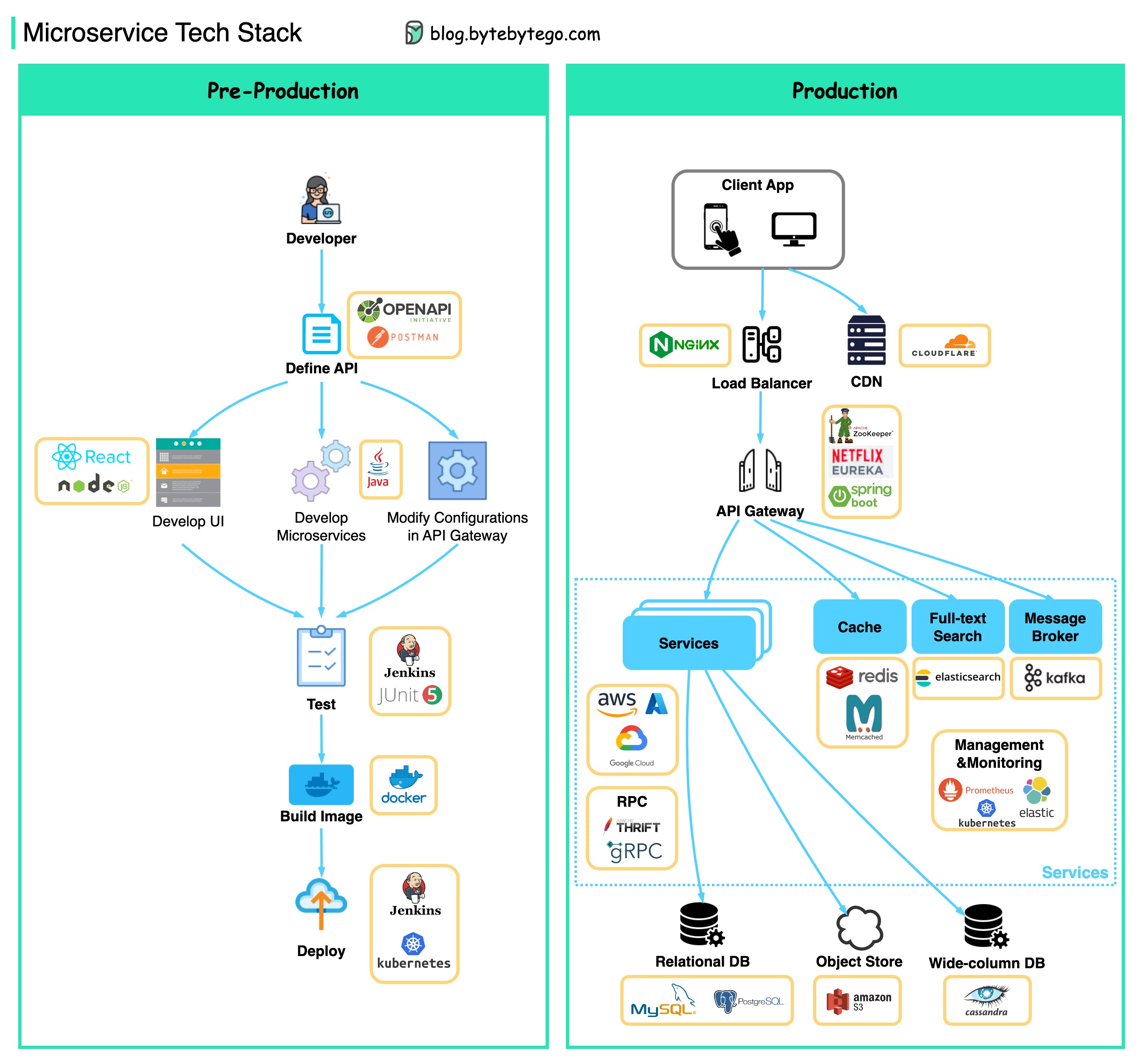
แผนภาพด้านล่างแสดงสถาปัตยกรรม microservice ทั่วไป
ประโยชน์ของ Microservices:
รูปภาพมีค่าหนึ่งพันคำ: 9 แนวทางปฏิบัติที่ดีที่สุดสำหรับการพัฒนาไมโครเซอ
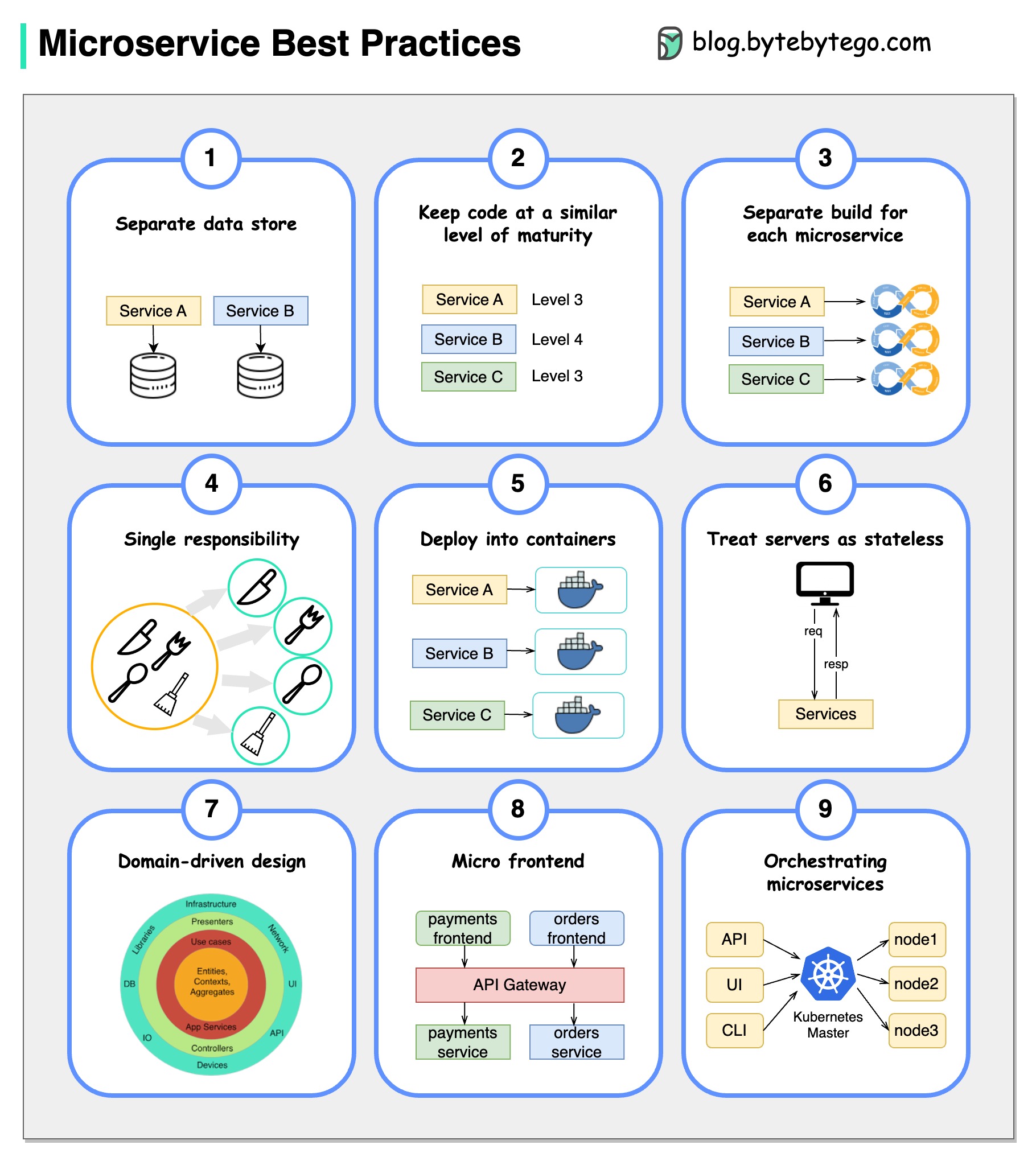
เมื่อเราพัฒนา microservices เราต้องปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดต่อไปนี้:
ด้านล่างนี้คุณจะพบไดอะแกรมที่แสดงสแต็คเทคโนโลยี Microservice ทั้งสำหรับขั้นตอนการพัฒนาและสำหรับการผลิต
มีการตัดสินใจออกแบบมากมายที่มีส่วนทำให้ประสิทธิภาพของคาฟคา ในโพสต์นี้เราจะมุ่งเน้นไปที่สอง เราคิดว่าทั้งสองมีน้ำหนักมากที่สุด
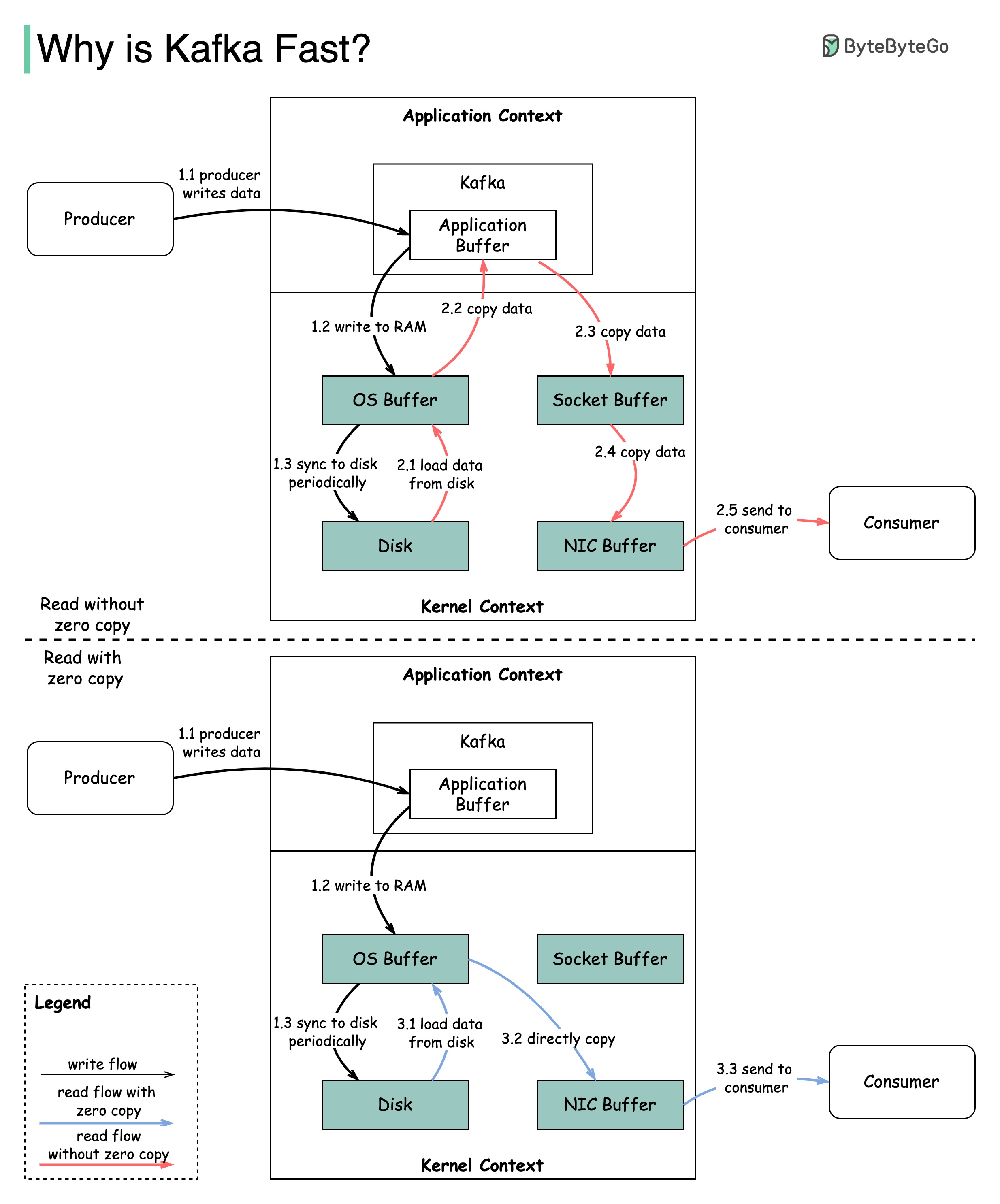
แผนภาพแสดงให้เห็นว่าข้อมูลถูกส่งระหว่างผู้ผลิตและผู้บริโภคอย่างไร
2.1 ข้อมูลถูกโหลดจากดิสก์ไปยัง CACHE CACHE
2.2 ข้อมูลถูกคัดลอกจากแอปพลิเคชัน OS ไปยัง Kafka
2.3 แอปพลิเคชัน Kafka คัดลอกข้อมูลลงในบัฟเฟอร์ซ็อกเก็ต
2.4 ข้อมูลถูกคัดลอกจากซ็อกเก็ตบัฟเฟอร์ไปยังการ์ดเครือข่าย
2.5 การ์ดเครือข่ายส่งข้อมูลไปยังผู้บริโภค
3.1: ข้อมูลถูกโหลดจากดิสก์ไปยัง OS CACHE 3.2 OS CACH
Zero Copy เป็นทางลัดในการบันทึกสำเนาข้อมูลหลายรายการระหว่างบริบทแอปพลิเคชันและบริบทเคอร์เนล
แผนภาพด้านล่างแสดงเศรษฐศาสตร์ของกระแสการชำระเงินด้วยบัตรเครดิต
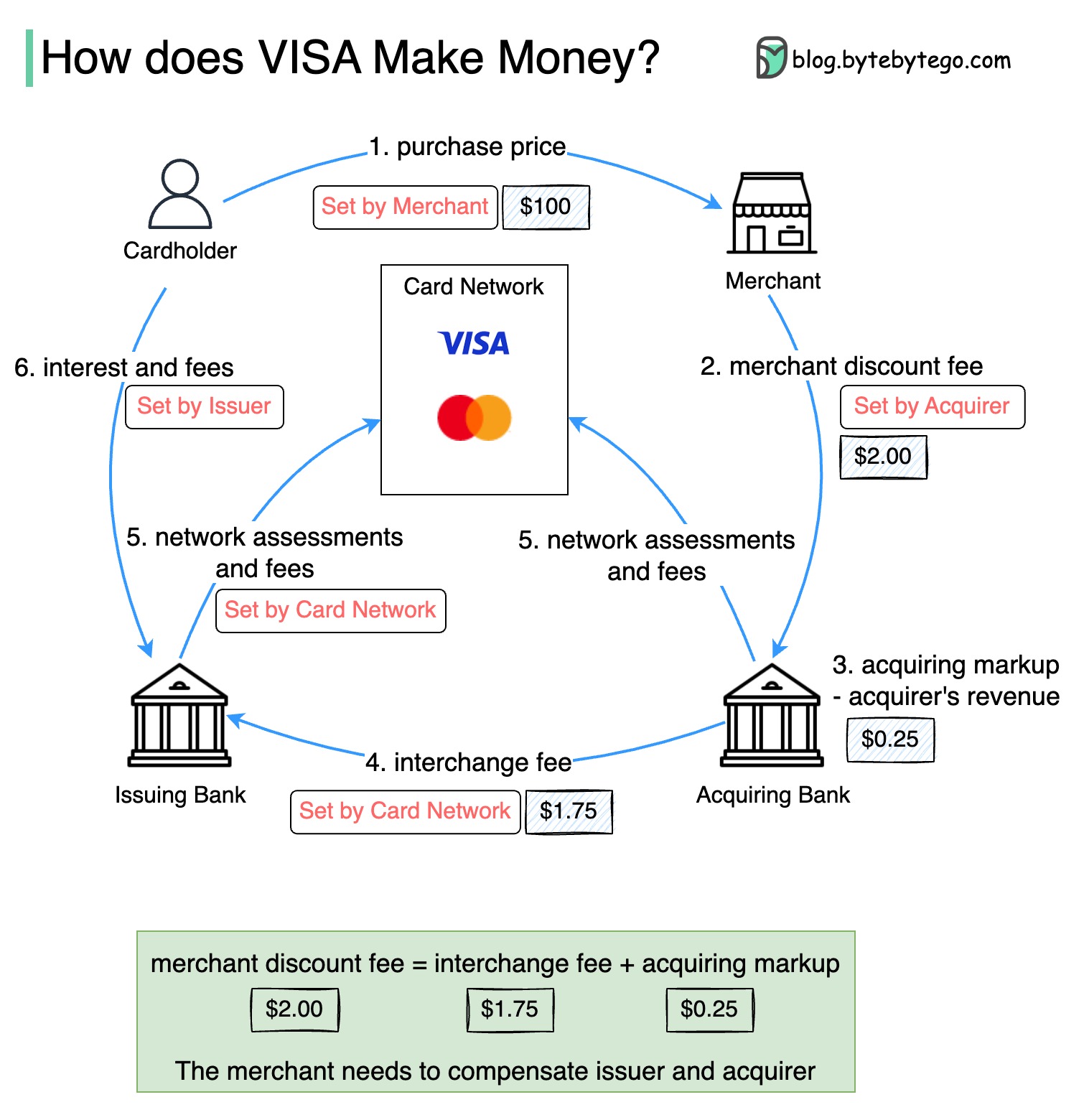
1. ผู้ถือบัตรจ่ายผู้ค้า $ 100 เพื่อซื้อผลิตภัณฑ์
2. ผลประโยชน์ของผู้ค้าจากการใช้บัตรเครดิตที่มีปริมาณการขายที่สูงขึ้นและจำเป็นต้องชดเชยผู้ออกและเครือข่ายบัตรสำหรับการให้บริการชำระเงิน ธนาคารที่ได้มากำหนดค่าธรรมเนียมกับผู้ค้าเรียกว่า "ค่าธรรมเนียมส่วนลดผู้ค้า"
3 - 4. ธนาคารที่ได้มาเก็บไว้ $ 0.25 เป็นมาร์กอัปที่ได้มาและ $ 1.75 จะจ่ายให้กับธนาคารที่ออกเป็นค่าธรรมเนียมการแลกเปลี่ยน ค่าธรรมเนียมส่วนลดการค้าควรครอบคลุมค่าธรรมเนียมการแลกเปลี่ยน
ค่าธรรมเนียมการแลกเปลี่ยนถูกกำหนดโดยเครือข่ายบัตรเนื่องจากมีประสิทธิภาพน้อยกว่าสำหรับแต่ละธนาคารที่ออกเงินเพื่อเจรจาค่าธรรมเนียมกับผู้ค้าแต่ละราย
5. เครือข่ายการ์ดตั้งค่าการประเมินเครือข่ายและค่าธรรมเนียมกับแต่ละธนาคารซึ่งจ่ายเครือข่ายบัตรสำหรับบริการทุกเดือน ตัวอย่างเช่นวีซ่าคิดค่าใช้จ่ายการประเมิน 0.11% รวมถึงค่าธรรมเนียมการใช้งาน $ 0.0195 สำหรับการกวาดทุกครั้ง
6. ผู้ถือบัตรจ่ายธนาคารที่ออกให้บริการ
เหตุใดธนาคารที่ออกผู้ออกจึงได้รับการชดเชย?
Visa, MasterCard และ American Express ทำหน้าที่เป็นเครือข่ายการ์ดสำหรับการล้างและการชำระเงิน บัตรที่ได้รับบัตรและธนาคารที่ออกบัตรสามารถทำได้ - และบ่อยครั้งที่แตกต่างกัน หากธนาคารต้องชำระธุรกรรมทีละคนโดยไม่มีตัวกลางแต่ละธนาคารจะต้องชำระธุรกรรมกับธนาคารอื่น ๆ ทั้งหมด นี่ค่อนข้างไม่มีประสิทธิภาพ
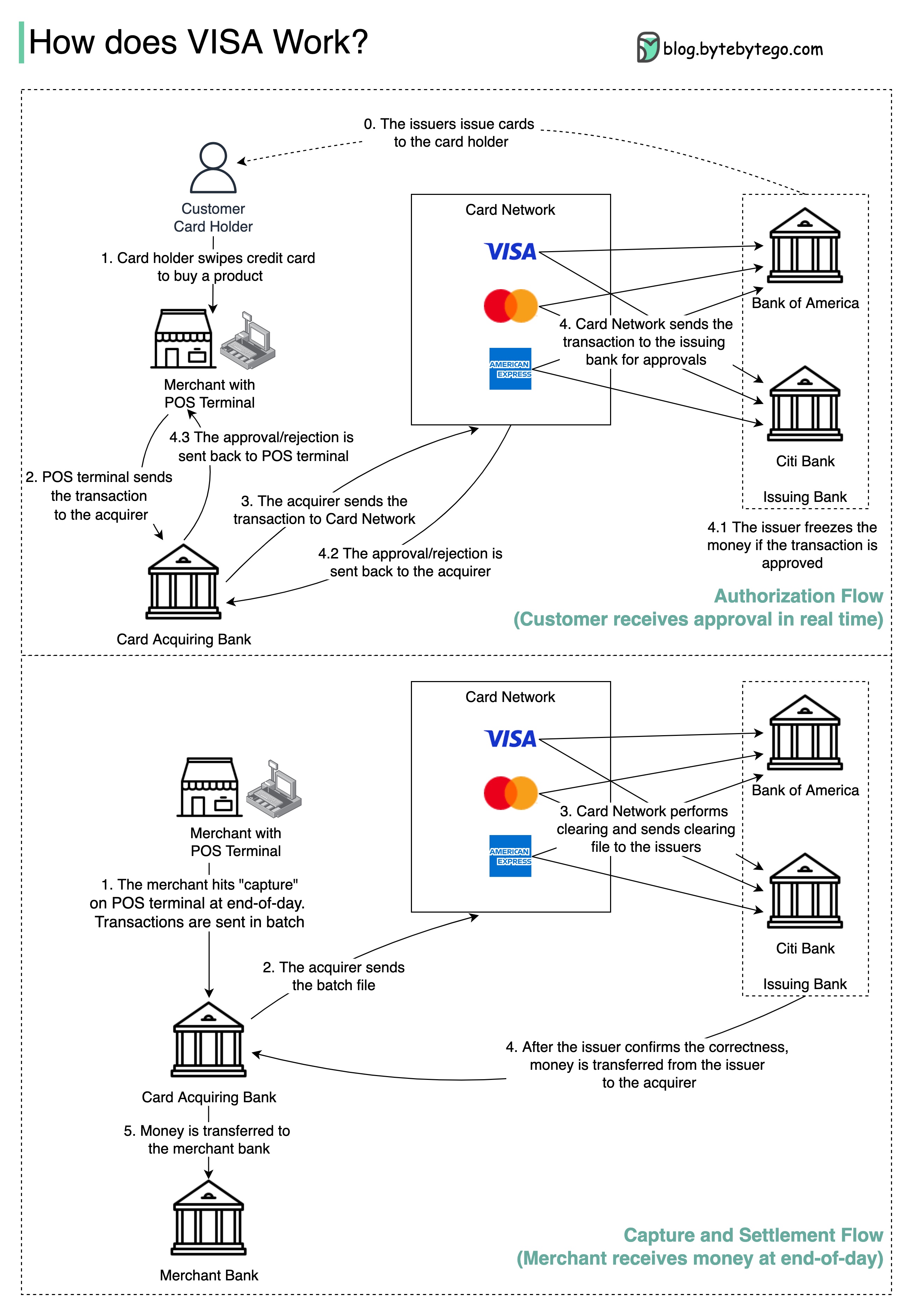
แผนภาพด้านล่างแสดงบทบาทของวีซ่าในกระบวนการชำระเงินด้วยบัตรเครดิต มีสองกระแสที่เกี่ยวข้อง กระแสการอนุญาตเกิดขึ้นเมื่อลูกค้ากวาดบัตรเครดิต การจับกุมและการตั้งถิ่นฐานเกิดขึ้นเมื่อผู้ค้าต้องการรับเงินในตอนท้ายของวัน
ขั้นตอนที่ 0: การออกบัตรของธนาคารออกบัตรเครดิตให้กับลูกค้า
ขั้นตอนที่ 1: ผู้ถือบัตรต้องการซื้อผลิตภัณฑ์และกวาดบัตรเครดิต ณ จุดขาย (POS) เทอร์มินัลในร้านค้าของผู้ค้า
ขั้นตอนที่ 2: เทอร์มินัล POS ส่งธุรกรรมไปยังธนาคารที่ได้มาซึ่งได้จัดเตรียมเทอร์มินัล POS
ขั้นตอนที่ 3 และ 4: ธนาคารที่ได้รับส่งธุรกรรมไปยังเครือข่ายบัตรหรือที่เรียกว่าโครงการ CARD เครือข่ายบัตรส่งธุรกรรมไปยังธนาคารที่ออกเพื่อขออนุมัติ
ขั้นตอนที่ 4.1, 4.2 และ 4.3: ธนาคารผู้ออกเงินจะค้างเงินหากการทำธุรกรรมได้รับการอนุมัติ การอนุมัติหรือการปฏิเสธจะถูกส่งกลับไปยังผู้ซื้อรวมถึงเทอร์มินัล POS
ขั้นตอนที่ 1 และ 2: ผู้ค้าต้องการเก็บเงินในตอนท้ายของวันดังนั้นพวกเขาจึงตี "จับ" บนเทอร์มินัล POS ธุรกรรมจะถูกส่งไปยังผู้ซื้อในแบทช์ ผู้ซื้อส่งไฟล์แบตช์พร้อมธุรกรรมไปยังเครือข่ายการ์ด
ขั้นตอนที่ 3: เครือข่ายการ์ดทำการล้างสำหรับธุรกรรมที่รวบรวมจากผู้ซื้อที่แตกต่างกันและส่งไฟล์การล้างไปยังธนาคารที่ออกอื่น ๆ
ขั้นตอนที่ 4: ธนาคารผู้ออกยืนยันความถูกต้องของไฟล์การล้างและโอนเงินไปยังธนาคารที่เกี่ยวข้อง
ขั้นตอนที่ 5: ธนาคารที่ได้มาจากนั้นโอนเงินไปยังธนาคารของผู้ค้า
ขั้นตอนที่ 4: เครือข่ายการ์ดล้างธุรกรรมจากธนาคารที่ได้มาต่าง ๆ การล้างเป็นกระบวนการที่ทำธุรกรรมชดเชยซึ่งกันและกันดังนั้นจำนวนธุรกรรมทั้งหมดจะลดลง
ในกระบวนการเครือข่ายบัตรจะต้องมีภาระในการพูดคุยกับแต่ละธนาคารและได้รับค่าธรรมเนียมบริการเป็นการตอบแทน
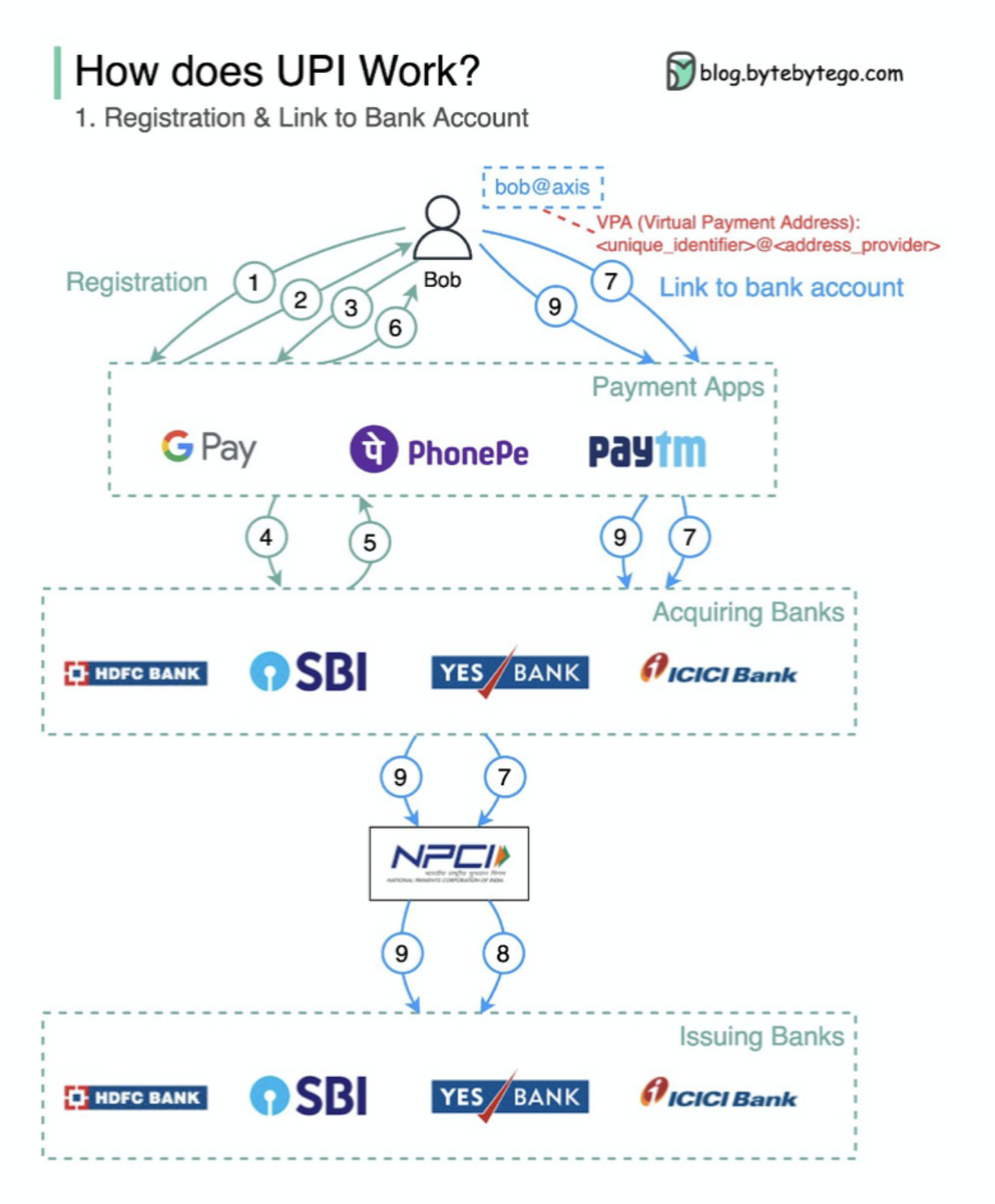
UPI คืออะไร? UPI เป็นระบบการชำระเงินแบบเรียลไทม์ที่พัฒนาโดย National Payments Corporation of India
มันคิดเป็น 60% ของธุรกรรมการค้าปลีกดิจิทัลในอินเดียวันนี้
UPI = ภาษามาร์กอัปการชำระเงิน + มาตรฐานสำหรับการชำระเงินระหว่างกัน
แนวคิดของ DevOps, SRE และวิศวกรรมแพลตฟอร์มได้เกิดขึ้นในเวลาที่ต่างกันและได้รับการพัฒนาโดยบุคคลและองค์กรต่าง ๆ
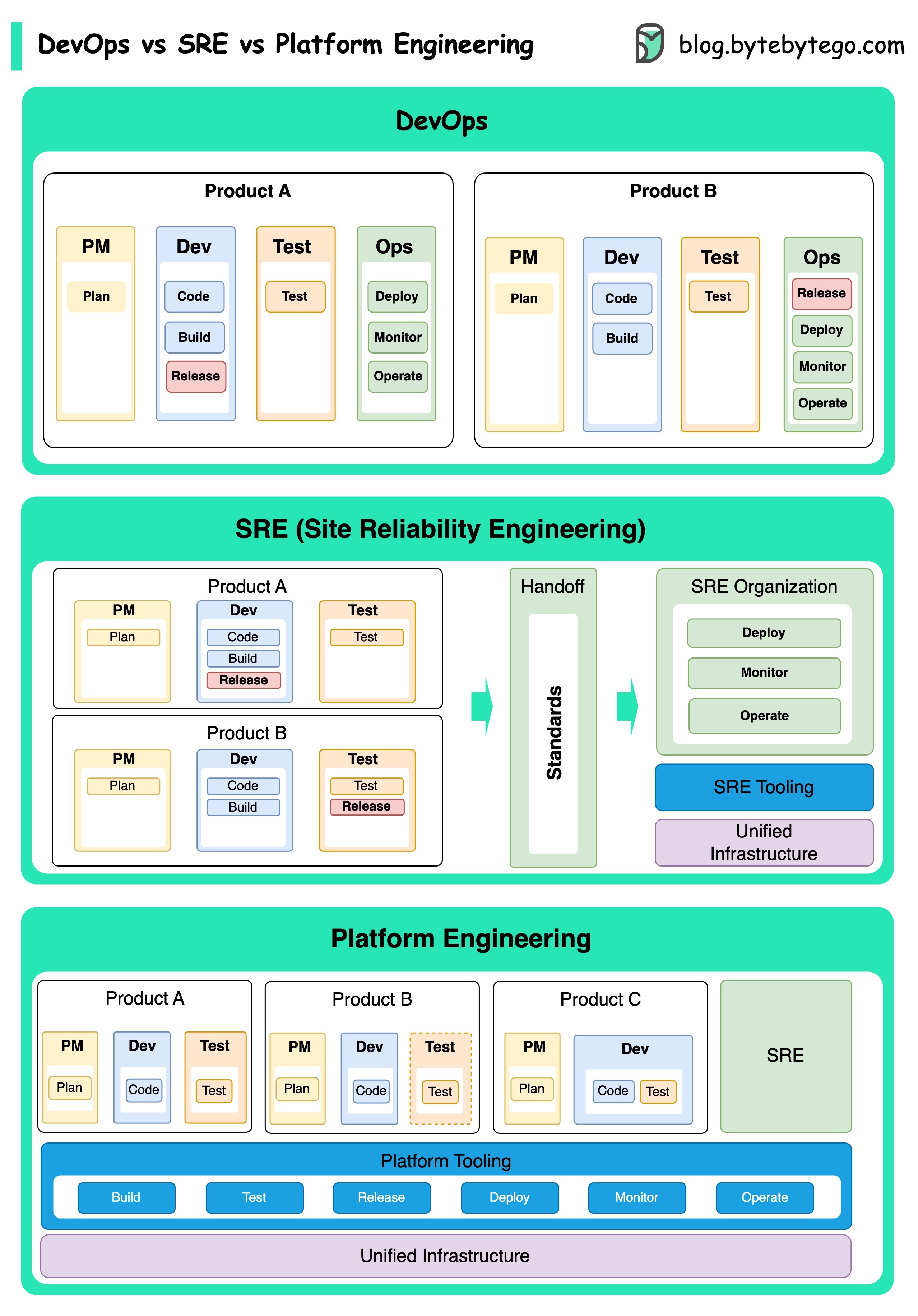
DevOps เป็นแนวคิดที่ได้รับการแนะนำในปี 2009 โดย Patrick DeBois และ Andrew Shafer ในการประชุม Agile พวกเขาพยายามที่จะเชื่อมช่องว่างระหว่างการพัฒนาซอฟต์แวร์และการดำเนินงานโดยการส่งเสริมวัฒนธรรมการทำงานร่วมกันและความรับผิดชอบร่วมกันสำหรับวงจรการพัฒนาซอฟต์แวร์ทั้งหมด
SRE หรือวิศวกรรมความน่าเชื่อถือของไซต์ได้รับการบุกเบิกโดย Google ในช่วงต้นยุค 2000 เพื่อจัดการกับความท้าทายในการดำเนินงานในการจัดการระบบขนาดใหญ่ที่ซับซ้อน Google พัฒนาวิธีปฏิบัติและเครื่องมือ SRE เช่นระบบการจัดการคลัสเตอร์ Borg และระบบตรวจสอบพระมหากษัตริย์เพื่อปรับปรุงความน่าเชื่อถือและประสิทธิภาพของบริการของพวกเขา
แพลตฟอร์มวิศวกรรมเป็นแนวคิดล่าสุดที่สร้างขึ้นจากรากฐานของวิศวกรรม SRE ต้นกำเนิดที่แม่นยำของวิศวกรรมแพลตฟอร์มนั้นมีความชัดเจนน้อยกว่า แต่โดยทั่วไปแล้วเป็นที่เข้าใจกันว่าเป็นส่วนขยายของการปฏิบัติของ DevOps และ SRE โดยมุ่งเน้นที่การส่งมอบแพลตฟอร์มที่ครอบคลุมสำหรับการพัฒนาผลิตภัณฑ์ที่สนับสนุนมุมมองทางธุรกิจทั้งหมด
เป็นที่น่าสังเกตว่าในขณะที่แนวคิดเหล่านี้เกิดขึ้นในเวลาที่ต่างกัน พวกเขาทั้งหมดเกี่ยวข้องกับแนวโน้มที่กว้างขึ้นของการปรับปรุงการทำงานร่วมกันระบบอัตโนมัติและประสิทธิภาพในการพัฒนาซอฟต์แวร์และการดำเนินงาน
K8S เป็นระบบประสานคอนเทนเนอร์ ใช้สำหรับการปรับใช้และการจัดการคอนเทนเนอร์ การออกแบบได้รับผลกระทบอย่างมากจากระบบภายในของ Google Borg
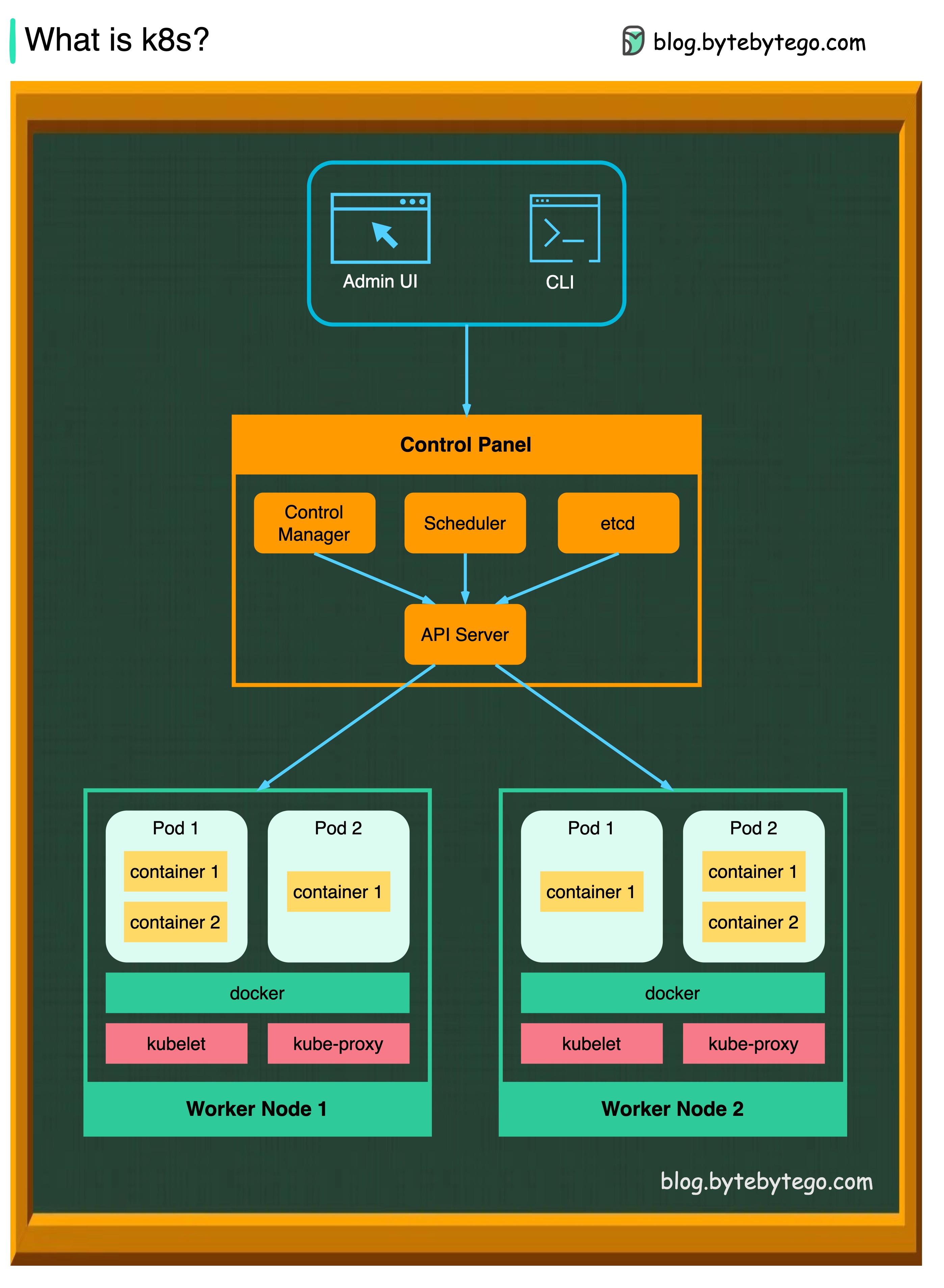
คลัสเตอร์ K8S ประกอบด้วยชุดเครื่องจักรคนงานที่เรียกว่าโหนดซึ่งใช้งานแอปพลิเคชันคอนเทนเนอร์ ทุกกลุ่มมีโหนดคนงานอย่างน้อยหนึ่งโหนด
โหนดคนงานโฮสต์พ็อดที่เป็นส่วนประกอบของปริมาณงานแอปพลิเคชัน ระนาบควบคุมจัดการโหนดคนงานและฝักในคลัสเตอร์ ในสภาพแวดล้อมการผลิตระนาบควบคุมมักจะวิ่งข้ามคอมพิวเตอร์หลายเครื่องและคลัสเตอร์มักจะทำงานหลายโหนดให้ความทนทานต่อความผิดพลาดและความพร้อมใช้งานสูง
เซิร์ฟเวอร์ API
เซิร์ฟเวอร์ API พูดคุยกับส่วนประกอบทั้งหมดในคลัสเตอร์ K8S การดำเนินการทั้งหมดของ POD จะดำเนินการโดยการพูดคุยกับเซิร์ฟเวอร์ API
ผู้จัดกำหนดการ
WOOLKLOFES POD WOOLDLOFS และกำหนดโหลดบนพ็อดที่สร้างขึ้นใหม่
ตัวจัดการคอนโทรลเลอร์
ตัวจัดการคอนโทรลเลอร์เรียกใช้คอนโทรลเลอร์รวมถึงคอนโทรลเลอร์โหนดตัวควบคุมงานคอนโทรลเลอร์ปลายทางและคอนโทรลเลอร์ ServiceAccount
ฯลฯ
ETCD เป็นร้านค้าคีย์-ค่าที่ใช้เป็นร้านค้าสำรองของ Kubernetes สำหรับข้อมูลคลัสเตอร์ทั้งหมด
ฝัก
ฝักเป็นกลุ่มของภาชนะและเป็นหน่วยที่เล็กที่สุดที่ K8S ดูแล พ็อดมีที่อยู่ IP เดียวที่ใช้กับคอนเทนเนอร์ทุกตัวภายใน POD
Kubelet
เอเจนต์ที่ทำงานในแต่ละโหนดในคลัสเตอร์ ช่วยให้มั่นใจได้ว่าตู้คอนเทนเนอร์กำลังทำงานอยู่ในฝัก
พร็อกซี Kube
Kube-Proxy เป็นพร็อกซีเครือข่ายที่ทำงานในแต่ละโหนดในคลัสเตอร์ของคุณ กำหนดเส้นทางการรับส่งข้อมูลที่เข้ามาในโหนดจากบริการ มันส่งต่อคำขอสำหรับการทำงานไปยังคอนเทนเนอร์ที่ถูกต้อง

นักเทียบท่าคืออะไร?
Docker เป็นแพลตฟอร์มโอเพนซอร์ซที่ช่วยให้คุณสามารถจัดจำหน่ายแจกจ่ายและเรียกใช้แอปพลิเคชันในคอนเทนเนอร์ที่แยกได้ มันมุ่งเน้นไปที่คอนเทนเนอร์การจัดหาสภาพแวดล้อมที่มีน้ำหนักเบาที่ห่อหุ้มแอปพลิเคชันและการพึ่งพาของพวกเขา
Kubernetes คืออะไร?
Kubernetes มักเรียกกันว่า K8S เป็นแพลตฟอร์มออเคสตร้าโอเพนซอร์ซ มันมีกรอบสำหรับการปรับใช้การปรับขนาดและการจัดการแอปพลิเคชันคอนเทนเนอร์โดยอัตโนมัติในคลัสเตอร์ของโหนด
ทั้งคู่ต่างกันอย่างไร?
Docker: Docker ทำงานที่ระดับคอนเทนเนอร์แต่ละตัวในโฮสต์ระบบปฏิบัติการเดียว
คุณต้องจัดการโฮสต์แต่ละโฮสต์ด้วยตนเองและการตั้งค่าเครือข่ายนโยบายความปลอดภัยและการจัดเก็บสำหรับคอนเทนเนอร์ที่เกี่ยวข้องหลายรายการอาจมีความซับซ้อน
Kubernetes: Kubernetes ทำงานที่ระดับคลัสเตอร์ มันจัดการแอพพลิเคชั่นคอนเทนเนอร์หลายตัวในหลายโฮสต์โดยให้ระบบอัตโนมัติสำหรับงานต่าง ๆ เช่นโหลดบาลานซ์การปรับขนาดและการรับรองสถานะที่ต้องการของแอปพลิเคชัน
ในระยะสั้น Docker มุ่งเน้นไปที่คอนเทนเนอร์และการรันคอนเทนเนอร์บนโฮสต์แต่ละตัวในขณะที่ Kubernetes มีความเชี่ยวชาญในการจัดการและจัดภาชนะบรรจุในระดับข้ามกลุ่มโฮสต์
แผนภาพด้านล่างแสดงสถาปัตยกรรมของ Docker และวิธีการทำงานเมื่อเราเรียกใช้“ Docker Build”,“ Docker Pull” และ“ Docker Run”
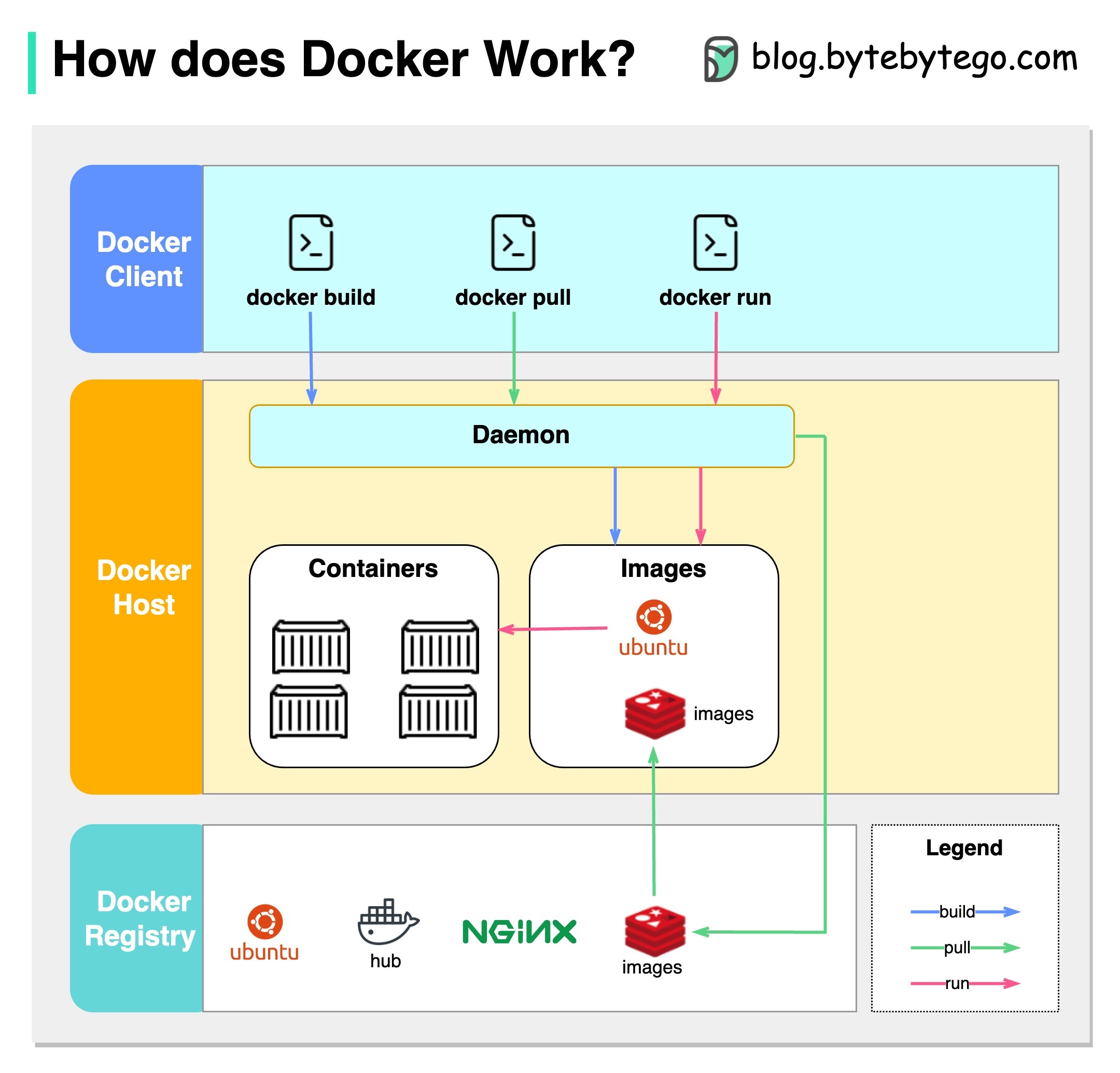
มี 3 องค์ประกอบในสถาปัตยกรรม Docker:
ลูกค้า Docker
ลูกค้า Docker พูดคุยกับ Docker Daemon
Host Docker
Docker Daemon รับฟังการร้องขอ Docker API และจัดการวัตถุ Docker เช่นรูปภาพคอนเทนเนอร์เครือข่ายและปริมาณ
Docker Registry
รีจิสทรี Docker เก็บภาพนักเทียบท่า Docker Hub เป็นรีจิสทรีสาธารณะที่ทุกคนสามารถใช้ได้
ลองใช้คำสั่ง“ Docker Run” เป็นตัวอย่าง
ในการเริ่มต้นมันเป็นสิ่งสำคัญที่จะระบุว่ารหัสของเราถูกเก็บไว้ที่ใด ข้อสันนิษฐานทั่วไปคือมีเพียงสองสถานที่ - หนึ่งแห่งในเซิร์ฟเวอร์ระยะไกลเช่น GitHub และอื่น ๆ ในเครื่องท้องถิ่นของเรา อย่างไรก็ตามสิ่งนี้ไม่ถูกต้องทั้งหมด GIT รักษาสามห้องพักในเครื่องของเราซึ่งหมายความว่ารหัสของเราสามารถพบได้ในสี่สถานที่:
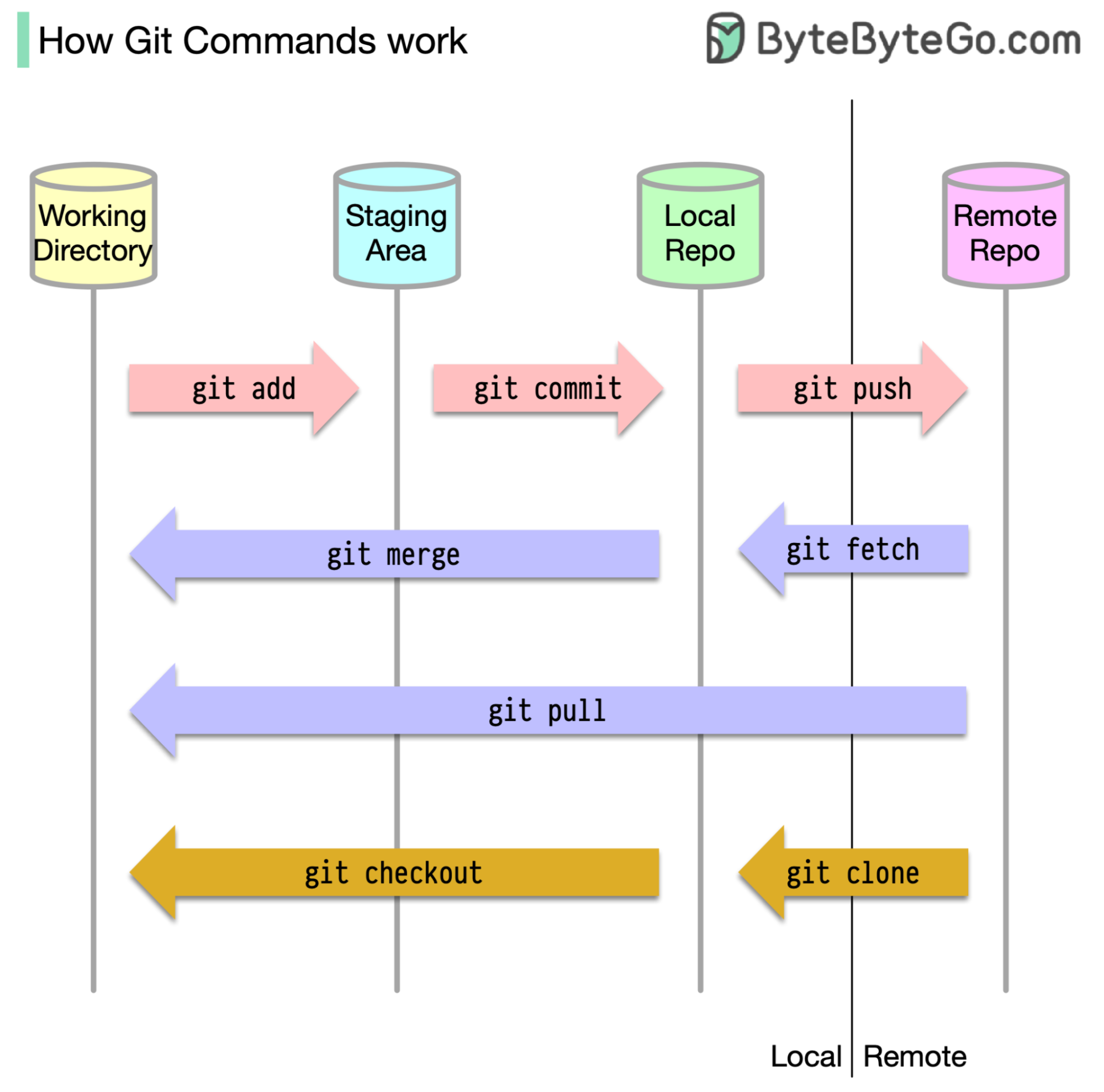
คำสั่ง GIT ส่วนใหญ่จะย้ายไฟล์ระหว่างสถานที่ทั้งสี่นี้เป็นหลัก
แผนภาพด้านล่างแสดงเวิร์กโฟลว์ Git
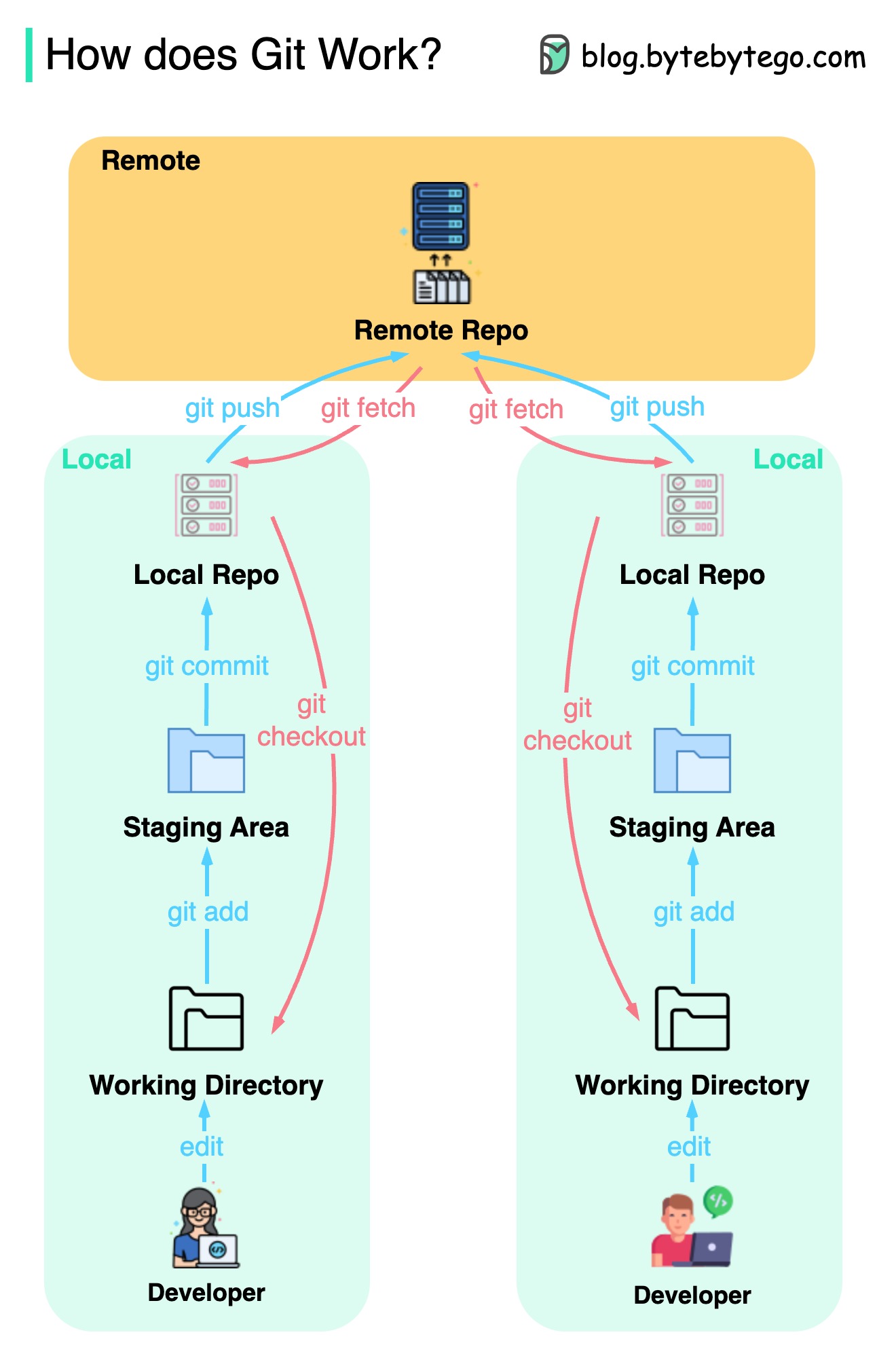
Git เป็นระบบควบคุมเวอร์ชันแบบกระจาย
นักพัฒนาทุกคนเก็บสำเนาท้องถิ่นของที่เก็บหลักและแก้ไขและมุ่งมั่นในสำเนาท้องถิ่น
การกระทำนั้นเร็วมากเนื่องจากการดำเนินการไม่โต้ตอบกับที่เก็บระยะไกล
หากพื้นที่เก็บข้อมูลระยะไกลล่มไฟล์สามารถกู้คืนได้จากที่เก็บในท้องถิ่น
อะไรคือความแตกต่าง?


