SwiftInfer
1.0.0
Streaming-LLM เป็นเทคนิคที่รองรับความยาวอินพุตที่ไม่สิ้นสุดสำหรับการอนุมาน LLM โดยใช้ประโยชน์จาก Attention Sink เพื่อป้องกันไม่ให้โมเดลล่มเมื่อหน้าต่างความสนใจเปลี่ยนไป งานต้นฉบับถูกนำไปใช้ใน PyTorch เรานำเสนอ SwiftInfer ซึ่งเป็นการใช้งาน TensorRT เพื่อทำให้ StreamingLLM มีระดับการผลิตมากขึ้น การใช้งานของเราสร้างขึ้นจากโครงการ TensorRT-LLM ที่เพิ่งเปิดตัว
เราใช้ API ใน TensorRT-LLM เพื่อสร้างโมเดลและเรียกใช้การอนุมาน เนื่องจาก API ของ TensorRT-LLM ไม่เสถียรและเปลี่ยนแปลงอย่างรวดเร็ว เราจึงผูกการใช้งานของเรากับ 42af740db51d6f11442fd5509ef745a4c043ce51 คอมมิตที่มีเวอร์ชันเป็น v0.6.0 เราอาจอัปเกรดพื้นที่เก็บข้อมูลนี้เนื่องจาก API ของ TensorRT-LLM มีเสถียรภาพมากขึ้น
หากคุณได้สร้าง TensorRT-LLM V0.6.0 เพียงเรียกใช้:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .มิฉะนั้น คุณควรติดตั้ง TensorRT-LLM ก่อน
หากใช้นักเทียบท่า คุณสามารถปฏิบัติตามการติดตั้ง TensorRT-LLM เพื่อติดตั้ง TensorRT-LLM V0.6.0
ด้วยการใช้นักเทียบท่า คุณสามารถติดตั้ง SwiftInfer ได้โดยเพียงแค่เรียกใช้:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . หากไม่ได้ใช้นักเทียบท่า เราจะจัดเตรียมสคริปต์เพื่อติดตั้ง TensorRT-LLM โดยอัตโนมัติ
ข้อกำหนดเบื้องต้น
โปรดตรวจสอบให้แน่ใจว่าคุณได้ติดตั้งแพ็คเกจต่อไปนี้:
ตรวจสอบให้แน่ใจว่าเวอร์ชันของ TensorRT >= 9.1.0 และชุดเครื่องมือ CUDA >= 12.2
ในการติดตั้ง tensorrt:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )หากต้องการดาวน์โหลด nccl ให้ทำตามหน้าดาวน์โหลด NCCL
หากต้องการดาวน์โหลด cudnn ให้ติดตามหน้าดาวน์โหลด cuDNN
คำสั่ง
ก่อนที่จะรันคำสั่งต่อไปนี้ โปรดตรวจสอบให้แน่ใจว่าคุณได้ตั้ง nvcc อย่างถูกต้อง หากต้องการตรวจสอบ ให้รัน:
nvcc --versionหากต้องการติดตั้ง TensorRT-LLM และ SwiftInfer ให้รัน:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . หากต้องการรันตัวอย่าง Llama ขั้นแรกคุณต้องโคลนพื้นที่เก็บข้อมูล Hugging Face สำหรับโมเดล meta-llama/Llama-2-7b-chat-hf หรือเวอร์ชันอื่นๆ ที่ใช้ Llama เช่น lmsys/vicuna-7b-v1.3 จากนั้น คุณสามารถเรียกใช้คำสั่งต่อไปนี้เพื่อสร้างกลไก TensorRT คุณต้องแทนที่ <model-dir> ด้วยเส้นทางจริงไปยังโมเดล Llama
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1ถัดไป คุณต้องดาวน์โหลดข้อมูล MT-Bench ที่ได้รับจาก LMSYS-FastChat
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonlในที่สุดคุณก็พร้อมที่จะรันตัวอย่าง Llama ด้วยคำสั่งต่อไปนี้
❗️❗️❗️ ก่อนหน้านั้น โปรดทราบว่า:
only_n_first ใช้เพื่อควบคุมจำนวนตัวอย่างที่จะประเมิน หากคุณต้องการประเมินตัวอย่างทั้งหมด โปรดลบอาร์กิวเมนต์นี้ python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5คุณควรคาดหวังที่จะเห็นรุ่นออกมาดังนี้:
เราได้เปรียบเทียบการใช้งาน Streaming-LLM กับเวอร์ชัน PyTorch ดั้งเดิม คำสั่งเกณฑ์มาตรฐานสำหรับการนำไปใช้งานของเรานั้นมีให้ในส่วน Run Llama Example ในขณะที่คำสั่งสำหรับการใช้ PyTorch ดั้งเดิมนั้นให้ไว้ในโฟลเดอร์ torch_streamingllm ฮาร์ดแวร์ที่ใช้มีดังต่อไปนี้:
ผลลัพธ์ (การสนทนา 20 รอบ) คือ:
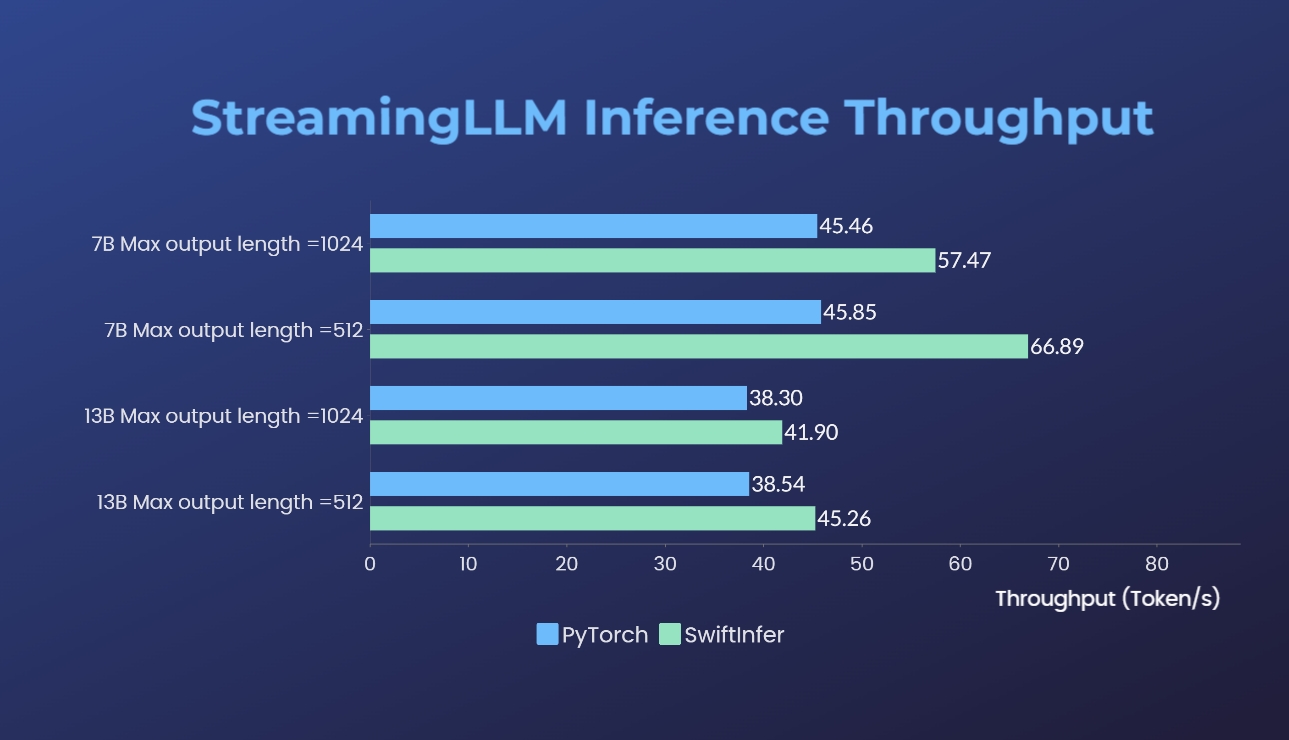
เรายังคงดำเนินการปรับปรุงประสิทธิภาพเพิ่มเติมและปรับให้เข้ากับ TensorRT V0.7.1 API นอกจากนี้เรายังสังเกตเห็นว่า TensorRT-LLM ได้รวม StreamingLLM ไว้ในตัวอย่างของพวกเขา แต่ดูเหมือนว่าจะเหมาะสำหรับการสร้างข้อความเดียวมากกว่าการสนทนาหลายรอบ
งานนี้ได้รับแรงบันดาลใจจาก Streaming-LLM เพื่อให้สามารถใช้งานได้จริง ตลอดการพัฒนา เราได้อ้างอิงเนื้อหาต่อไปนี้ และเราประสงค์ที่จะรับทราบถึงความพยายามและการมีส่วนร่วมของเนื้อหาเหล่านี้ต่อชุมชนโอเพ่นซอร์สและสถาบันการศึกษา
หากคุณพบว่า StreamingLLM และการใช้งาน TensorRT ของเรามีประโยชน์ โปรดอ้างอิงพื้นที่เก็บข้อมูลของเราและงานต้นฉบับที่เสนอโดย Xiao และคณะ จาก MIT Han Lab
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

