paxml
paxml release 1.4.0
Pax เป็นเฟรมเวิร์กสำหรับกำหนดค่าและรันการทดสอบแมชชีนเลิร์นนิงนอกเหนือจาก Jax
เราอ้างถึงหน้านี้เพื่อดูเอกสารประกอบโดยละเอียดเพิ่มเติมเกี่ยวกับการเริ่มต้นโปรเจ็กต์ Cloud TPU คำสั่งต่อไปนี้เพียงพอที่จะสร้าง Cloud TPU VM ที่มี 8 คอร์จากเครื่องของบริษัท
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR หากคุณใช้ชิ้น TPU Pod โปรดดูคู่มือนี้ เรียกใช้คำสั่งทั้งหมดจากเครื่องท้องถิ่นโดยใช้ gcloud ด้วยตัวเลือก --worker=all :
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "ส่วนการเริ่มต้นอย่างรวดเร็วต่อไปนี้ถือว่าคุณใช้งานบน TPU โฮสต์เดียว ดังนั้นคุณจึงสามารถ ssh ไปที่ VM และรันคำสั่งที่นั่นได้
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONEหลังจาก ssh ใช้ VM คุณสามารถติดตั้ง paxml รุ่นเสถียรจาก PyPI หรือเวอร์ชัน dev จาก github
สำหรับการติดตั้งรุ่นที่เสถียรจาก PyPI (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html หากคุณพบปัญหาเกี่ยวกับการขึ้นต่อกันแบบสกรรมกริยาและคุณกำลังใช้สภาพแวดล้อม Cloud TPU VM แบบเนทีฟ โปรดไปที่สาขาการเผยแพร่ rX.YZ ที่เกี่ยวข้อง และดาวน์โหลด paxml/pip_package/requirements.txt ไฟล์นี้รวมเวอร์ชันที่แน่นอนของการขึ้นต่อกันแบบสกรรมกริยาทั้งหมดที่จำเป็นในสภาพแวดล้อม Cloud TPU VM แบบเนทีฟ ซึ่งเราสร้าง/ทดสอบรุ่นที่เกี่ยวข้อง
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtสำหรับการติดตั้งเวอร์ชัน dev จาก github และเพื่อความสะดวกในการแก้ไขโค้ด:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=Trueโปรดไปที่โฟลเดอร์เอกสารของเราเพื่อดูเอกสารประกอบและบทช่วยสอน Jupyter Notebook โปรดดูคำแนะนำในการรัน Jupyter Notebooks บน Cloud TPU VM ในส่วนต่อไปนี้
คุณสามารถเรียกใช้สมุดบันทึกตัวอย่างใน TPU VM ที่คุณเพิ่งติดตั้ง paxml ####ขั้นตอนในการเปิดใช้งานสมุดบันทึกใน v4-8
ssh ใน TPU VM พร้อมการส่งต่อพอร์ต gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
ติดตั้งโน้ตบุ๊ก jupyter บน TPU vm และดาวน์เกรด markupsafe
pip install notebook
pip install markupsafe==2.0.1
ส่งออกเส้นทาง jupyter export PATH=/home/$USER/.local/bin:$PATH
scp ตัวอย่างโน้ตบุ๊กไปยัง TPU VM gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
เริ่มสมุดบันทึก jupyter จาก TPU VM และจดบันทึกโทเค็นที่สร้างโดยสมุดบันทึก jupyter jupyter notebook --no-browser --port=8080
จากนั้นในเบราว์เซอร์ท้องถิ่นของคุณไปที่: http://localhost:8080/ และป้อนโทเค็นที่ให้มา
หมายเหตุ: ในกรณีที่คุณจำเป็นต้องเริ่มใช้สมุดบันทึกเครื่องที่สองในขณะที่สมุดบันทึกเครื่องแรกยังคงครอบครอง TPU คุณสามารถเรียกใช้ pkill -9 python3 เพื่อเพิ่ม TPU ได้
หมายเหตุ: NVIDIA ได้เปิดตัว Pax เวอร์ชันอัปเดตพร้อมการรองรับ H100 FP8 และการปรับปรุงประสิทธิภาพ GPU ในวงกว้าง กรุณาเยี่ยมชมพื้นที่เก็บข้อมูล NVIDIA Rosetta เพื่อดูรายละเอียดเพิ่มเติมและคำแนะนำการใช้งาน
เวิร์กโฟลว์ Profile Guided Latency Estimator (PGLE) จะวัดเวลาทำงานจริงของการประมวลผลและส่วนรวม ข้อมูลโปรไฟล์จะถูกป้อนกลับเข้าไปในคอมไพเลอร์ XLA เพื่อการตัดสินใจด้านกำหนดเวลาที่ดีขึ้น
Profile Guided Latency Estimator สามารถใช้ได้ด้วยตนเองหรือโดยอัตโนมัติ ในโหมดอัตโนมัติ JAX จะรวบรวมข้อมูลโปรไฟล์และคอมไพล์โมดูลใหม่ในการรันครั้งเดียว ขณะที่อยู่ในโหมดกำหนดเอง คุณจะต้องรันงานสองครั้ง ครั้งแรกเพื่อรวบรวมและบันทึกโปรไฟล์ และครั้งที่สองเพื่อคอมไพล์และรันด้วยข้อมูลที่ให้มา
คุณสามารถเปิด PGLE อัตโนมัติได้โดยการตั้งค่าตัวแปรสภาพแวดล้อมต่อไปนี้:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
หรือใน JAX สามารถตั้งค่าได้ดังต่อไปนี้:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
คุณสามารถควบคุมจำนวนการเรียกใช้ซ้ำที่ใช้ในการรวบรวมข้อมูลโปรไฟล์ได้โดยการเปลี่ยน JAX_PGLE_PROFILING_RUNS การเพิ่มพารามิเตอร์นี้จะนำไปสู่ข้อมูลโปรไฟล์ที่ดีขึ้น แต่ยังจะเพิ่มจำนวนขั้นตอนการฝึกที่ไม่ได้รับการปรับให้เหมาะสมอีกด้วย
พารามิเตอร์ JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY อนุญาตให้ใช้การเรียกกลับโฮสต์ด้วย PGLE อัตโนมัติ
การลดพารามิเตอร์ JAX_PGLE_AGGREGATION_PERCENTILE อาจช่วยในกรณีที่ประสิทธิภาพระหว่างขั้นตอนดังเกินไปที่จะกรองการวัดที่ไม่เกี่ยวข้องออก
ข้อควรสนใจ: Auto PGLE ใช้ไม่ได้กับโมดูลที่คอมไพล์ไว้ล่วงหน้า เนื่องจาก JAX จำเป็นต้องคอมไพล์โมดูลใหม่ระหว่างการดำเนินการ auto PGLE จะไม่ทำงานสำหรับ AoT หรือในกรณีต่อไปนี้:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
หากคุณยังคงต้องการใช้ Profile Guided Latency Estimator ด้วยตนเอง ขั้นตอนการทำงานใน XLA/GPU คือ:
คุณสามารถทำได้โดยการตั้งค่า:
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) หลังจากขั้นตอนนี้ คุณจะได้ไฟล์ profile.pb ใต้ rundir ที่พิมพ์อยู่ในโค้ด
คุณต้องส่งไฟล์ profile.pb ไปยังแฟล็ก --xla_gpu_pgle_profile_file_or_directory_path
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " หากต้องการเปิดใช้งานการบันทึกใน XLA และตรวจสอบว่าโปรไฟล์ดีหรือไม่ ให้ตั้งค่าระดับการบันทึกให้รวม INFO :
export TF_CPP_MIN_LOG_LEVEL=0เรียกใช้เวิร์กโฟลว์จริง หากคุณพบการบันทึกเหล่านี้ในบันทึกที่กำลังทำงานอยู่ แสดงว่ามีการใช้ตัวสร้างโปรไฟล์ในตัวกำหนดเวลาการซ่อนเวลาแฝง:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax ทำงานบน Jax คุณสามารถดูรายละเอียดการรันงาน Jax บน Cloud TPU ได้ที่นี่ และดูรายละเอียดเกี่ยวกับการรันงาน Jax บนพ็อด Cloud TPU ได้ที่นี่
หากคุณพบข้อผิดพลาดในการขึ้นต่อกัน โปรดดูไฟล์ requirements.txt ในสาขาที่สอดคล้องกับรุ่นเสถียรที่คุณกำลังติดตั้ง ตัวอย่างเช่น สำหรับรีลีสเสถียร 0.4.0 ให้ใช้สาขา r0.4.0 และอ้างอิงถึงข้อกำหนด txt สำหรับเวอร์ชันที่แน่นอนของการขึ้นต่อกันที่ใช้สำหรับรีลีสที่เสถียร
นี่คือตัวอย่างการลู่เข้าบางส่วนที่ทำงานบนชุดข้อมูล c4
คุณสามารถเรียกใช้โมเดลพารามิเตอร์ 1B บนชุดข้อมูล c4 บน TPU v4-8 ได้โดยใช้การกำหนดค่า C4Spmd1BAdam4Replicas จาก c4.py ดังนี้:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket > คุณสามารถสังเกตเส้นโค้งการสูญเสียและบันทึกกราฟ log perplexity ได้ดังนี้:
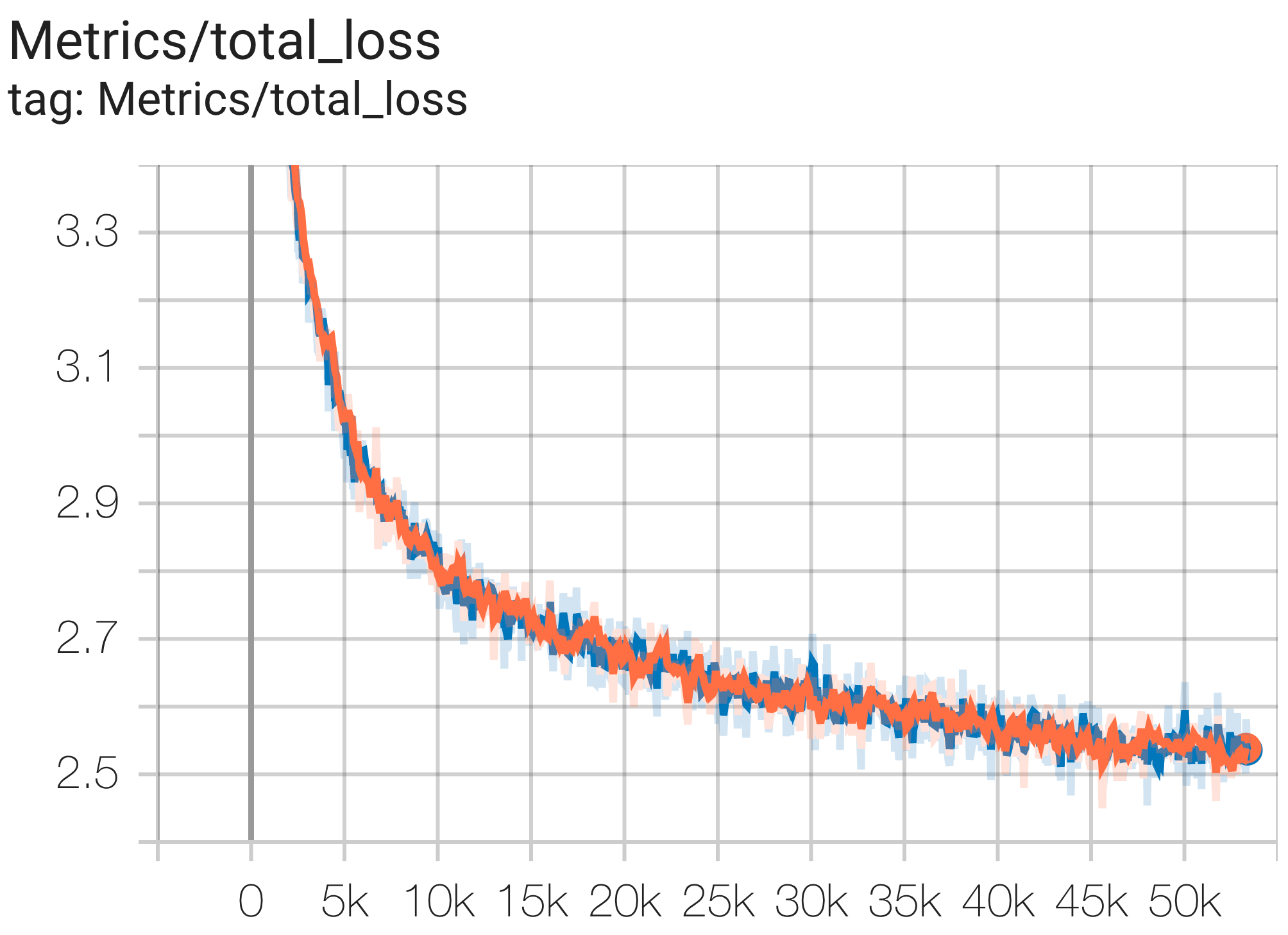
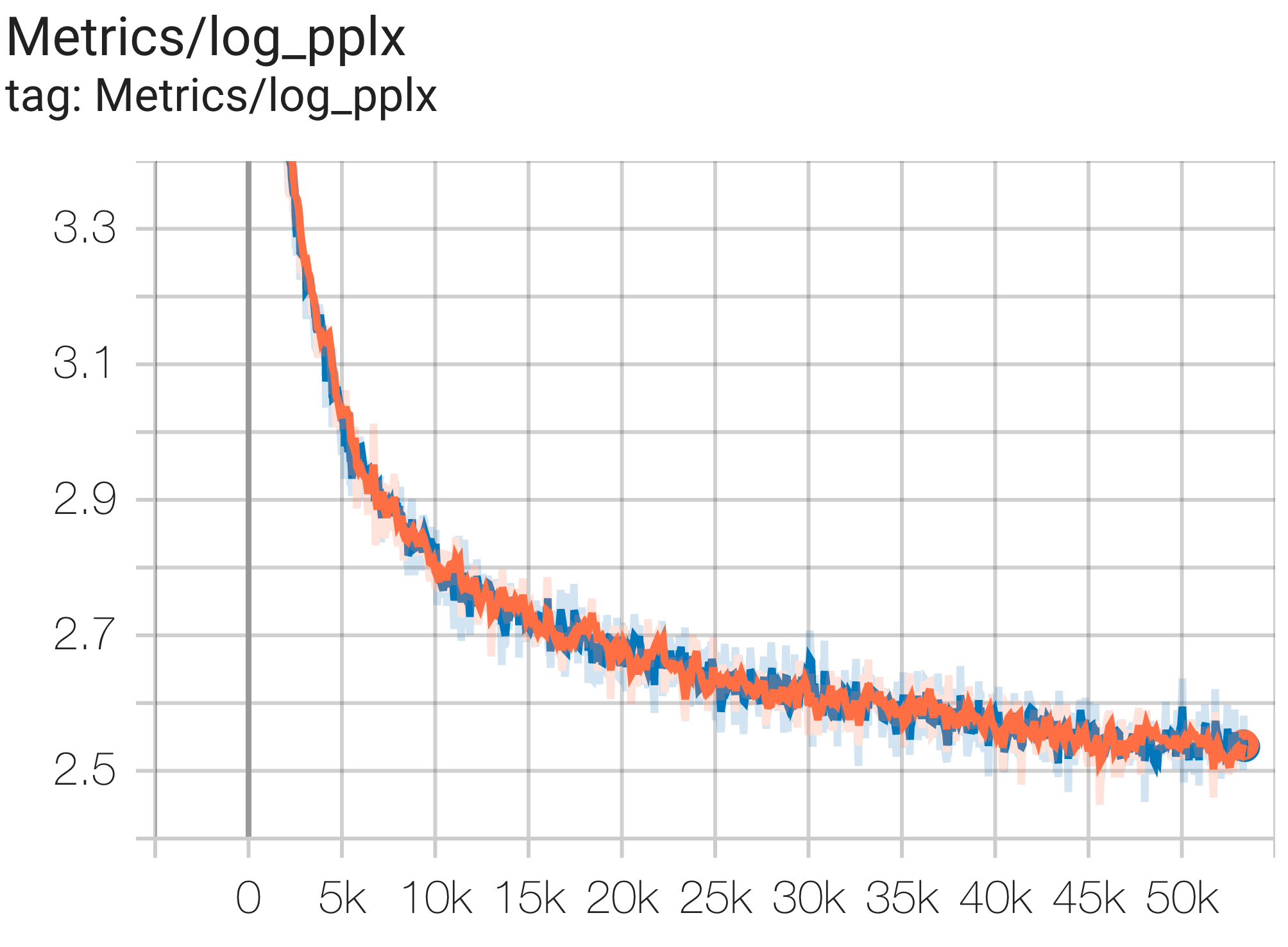
คุณสามารถเรียกใช้โมเดลพารามิเตอร์ 16B บนชุดข้อมูล c4 บน TPU v4-64 ได้โดยใช้การกำหนดค่า C4Spmd16BAdam32Replicas จาก c4.py ดังนี้:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket > คุณสามารถสังเกตเส้นโค้งการสูญเสียและบันทึกกราฟ log perplexity ได้ดังนี้:
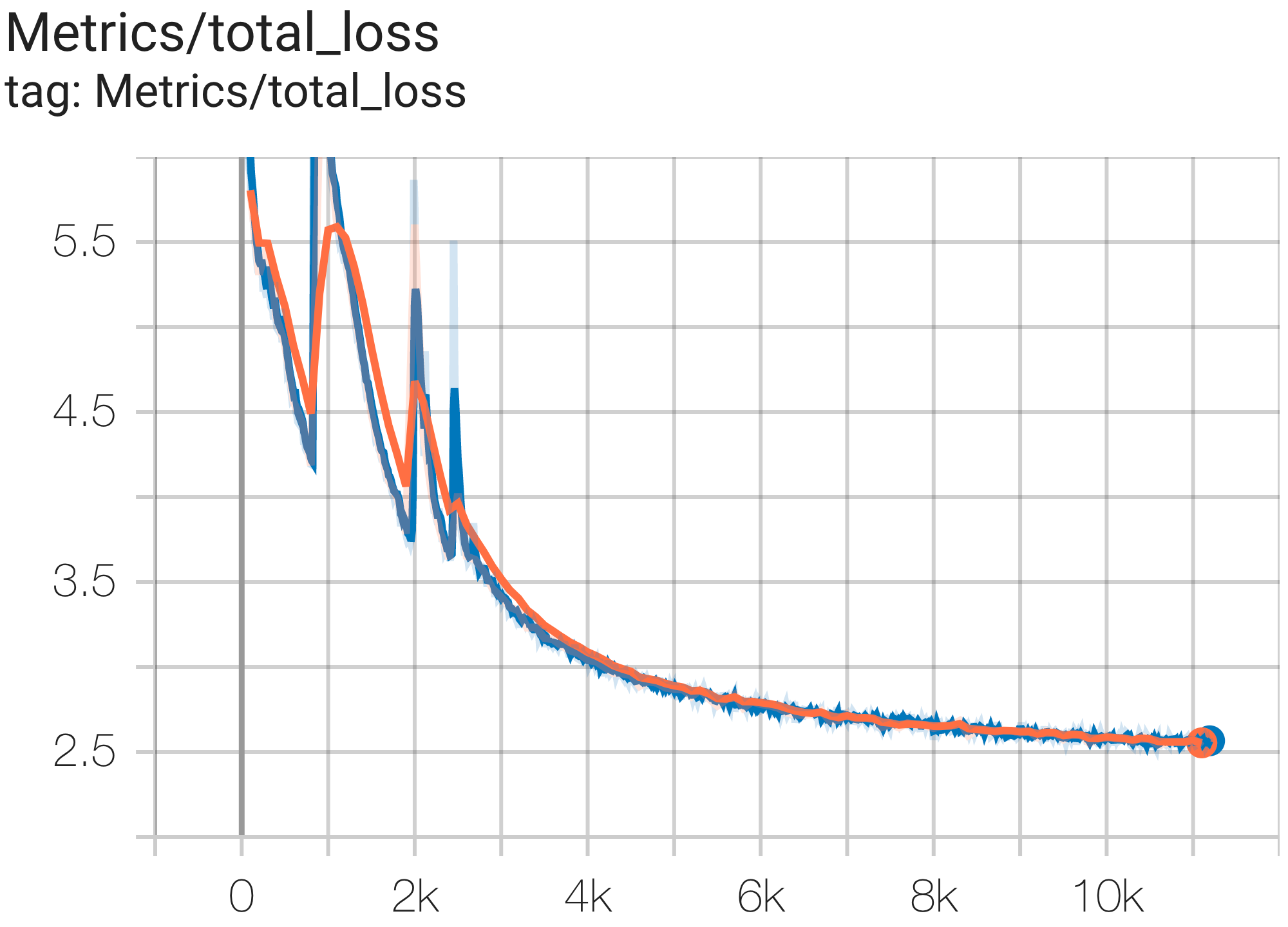
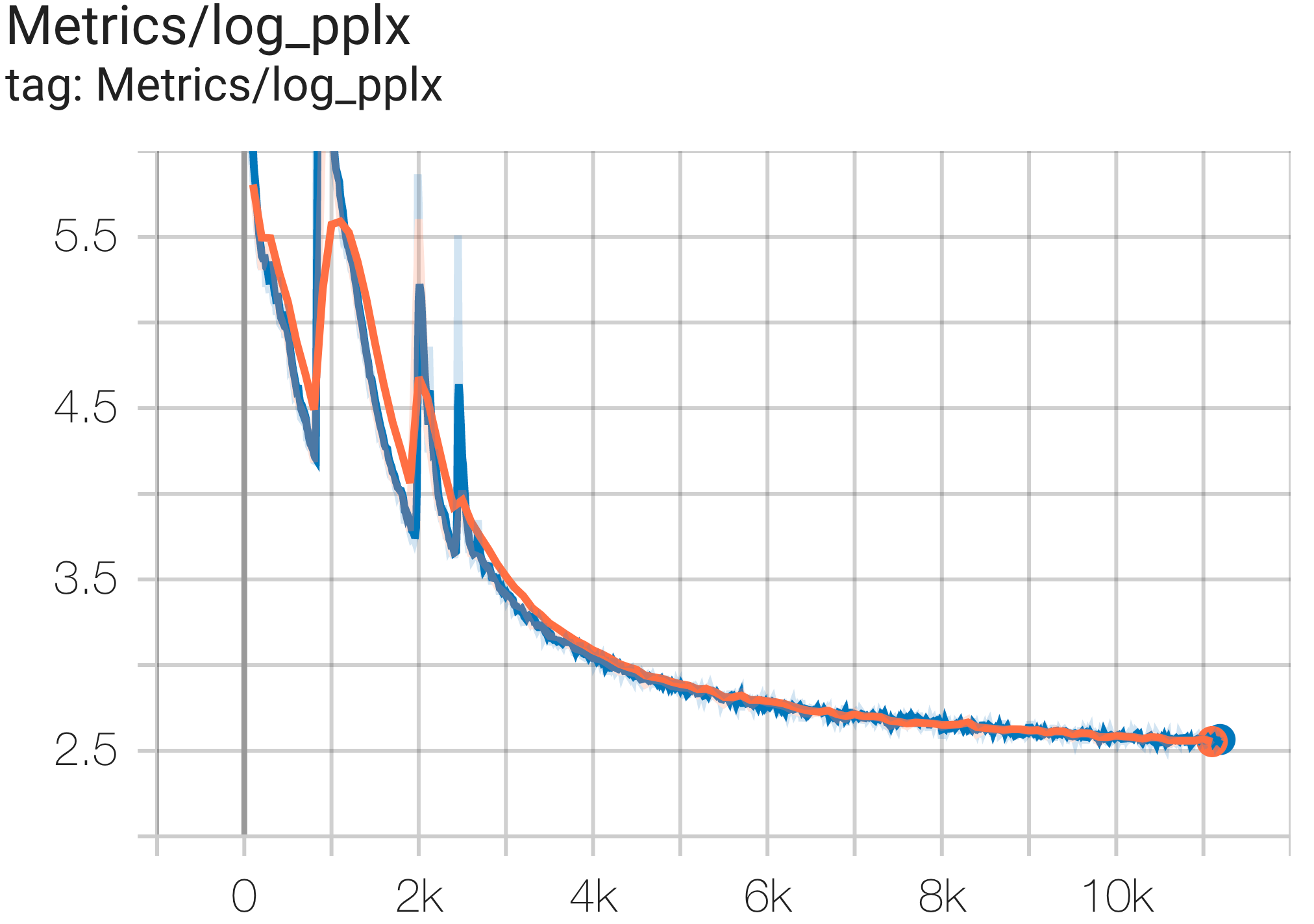
คุณสามารถเรียกใช้โมเดล GPT3-XL บนชุดข้อมูล c4 บน TPU v4-128 ได้โดยใช้การกำหนดค่า C4SpmdPipelineGpt3SmallAdam64Replicas จาก c4.py ดังนี้
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket > คุณสามารถสังเกตเส้นโค้งการสูญเสียและบันทึกกราฟ log perplexity ได้ดังนี้:
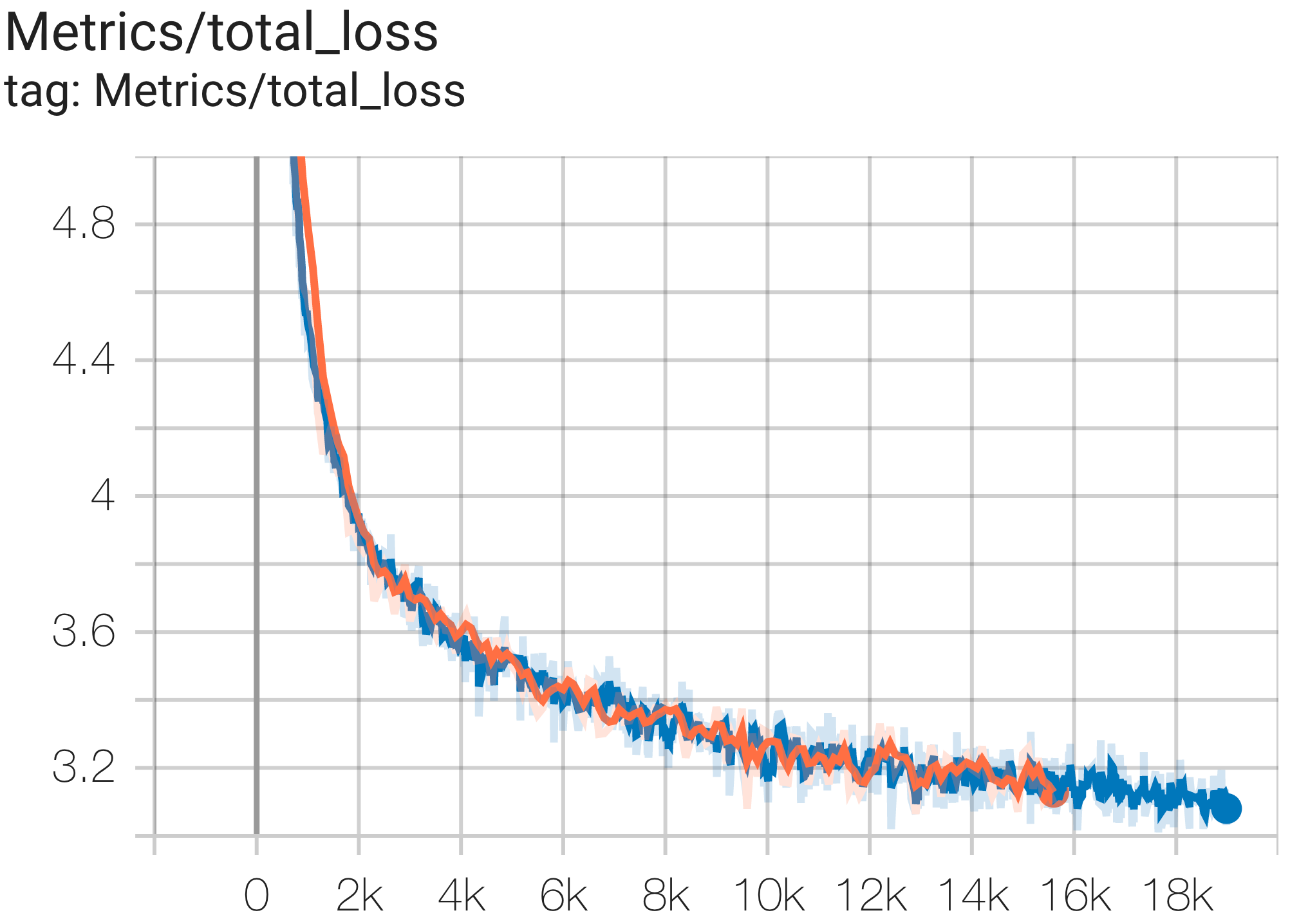
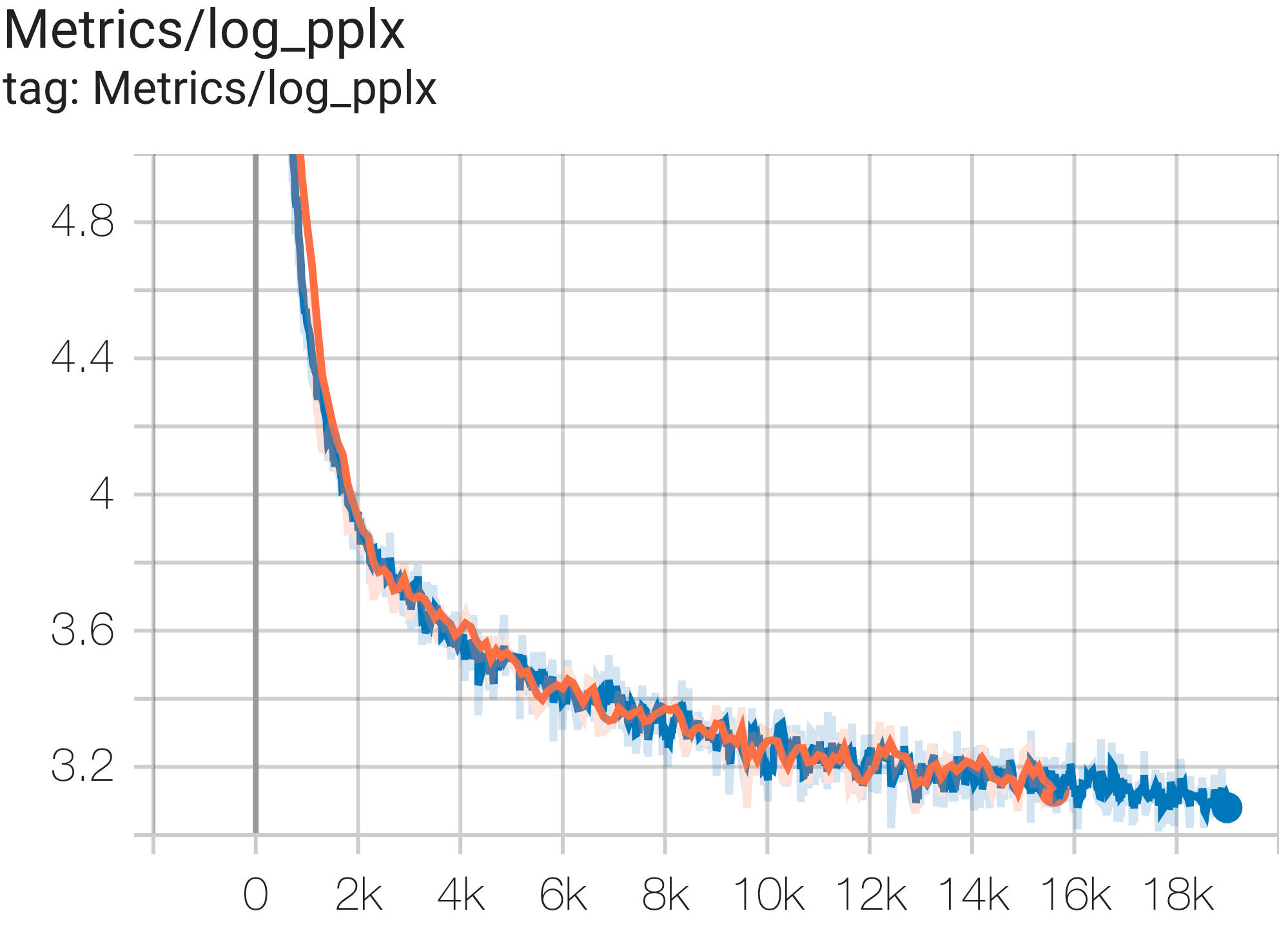
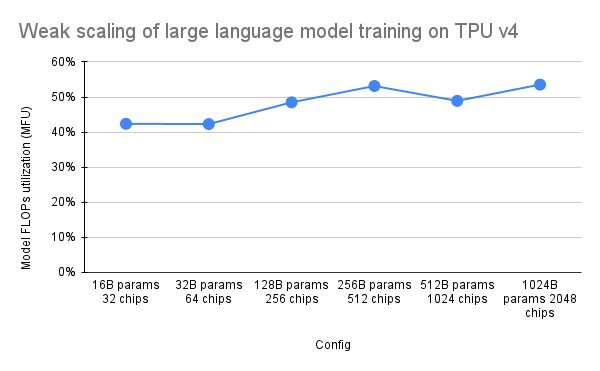
เอกสาร PaLM ได้แนะนำตัวชี้วัดประสิทธิภาพที่เรียกว่า Model FLOPs Utilization (MFU) สิ่งนี้ถูกวัดเป็นอัตราส่วนของปริมาณการประมวลผลที่สังเกตได้ (ใน เช่น โทเค็นต่อวินาทีสำหรับโมเดลภาษา) ต่อปริมาณการประมวลผลสูงสุดทางทฤษฎีของระบบที่ควบคุม 100% ของ FLOP สูงสุด มันแตกต่างจากวิธีอื่นๆ ในการวัดการใช้งานการประมวลผล เนื่องจากไม่รวม FLOP ที่ใช้ในการเปิดใช้งานการเปลี่ยนแปลงวัตถุในระหว่างการส่งกลับ ซึ่งหมายความว่าประสิทธิภาพที่วัดโดย MFU จะแปลงเป็นความเร็วการฝึกอบรมจากต้นทางถึงปลายทางโดยตรง
เพื่อประเมิน MFU ของคลาสหลักของปริมาณงานบน TPU v4 Pods ด้วย Pax เราได้จัดทำแคมเปญการวัดประสิทธิภาพเชิงลึกในชุดการกำหนดค่าโมเดลภาษา Transformer (GPT) ที่ใช้ตัวถอดรหัสเท่านั้น ซึ่งมีขนาดตั้งแต่พารามิเตอร์นับพันล้านไปจนถึงล้านล้านพารามิเตอร์ บนชุดข้อมูล c4 กราฟต่อไปนี้แสดงประสิทธิภาพการฝึกโดยใช้รูปแบบ "การปรับขนาดแบบอ่อนแอ" โดยที่เราขยายขนาดโมเดลตามสัดส่วนของจำนวนชิปที่ใช้
การกำหนดค่าหลายชิ้นใน repo นี้อ้างอิงถึง 1. การกำหนดค่าชิ้นเดียวสำหรับสถาปัตยกรรมไวยากรณ์ / โมเดล และ 2. repo MaxText สำหรับค่าการกำหนดค่า
เราจัดเตรียมตัวอย่างการทำงานภายใต้ c4_multislice.py` เพื่อเป็นจุดเริ่มต้นสำหรับ Pax บน multislice
เราอ้างถึงหน้านี้เพื่อดูเอกสารประกอบโดยละเอียดเพิ่มเติมเกี่ยวกับการใช้ทรัพยากรที่อยู่ในคิวสำหรับโปรเจ็กต์ Cloud TPU แบบหลายส่วน ต่อไปนี้แสดงขั้นตอนที่จำเป็นในการตั้งค่า TPU สำหรับการเรียกใช้การกำหนดค่าตัวอย่างใน Repo นี้
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run สมมติว่าสำหรับการรัน C4Spmd22BAdam2xv4_128 บน v4-128 จำนวน 2 สไลซ์ คุณจะต้องตั้งค่า TPU ด้วยวิธีต่อไปนี้:
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX คำสั่งการตั้งค่าที่อธิบายไว้ก่อนหน้านี้จำเป็นต้องรันกับพนักงานทุกคนในทุกสไลซ์ คุณสามารถ 1) ssh เข้าไปในผู้ปฏิบัติงานแต่ละคนและแต่ละส่วนแยกกัน หรือ 2) ใช้ for loop โดยมี --worker=all flag เป็นคำสั่งต่อไปนี้
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done หากต้องการเรียกใช้การกำหนดค่าหลายส่วน ให้เปิดเทอร์มินัลจำนวนเท่ากับ $NODE_COUNT ของคุณ สำหรับการทดลองของเราใน 2 ชิ้น ( C4Spmd22BAdam2xv4_128 ) ให้เปิดเทอร์มินัลสองเครื่อง จากนั้น รันแต่ละคำสั่งเหล่านี้ทีละคำสั่งจากแต่ละเทอร์มินัล
จากเทอร์มินัล 0 ให้รันคำสั่งการฝึกอบรมสำหรับสไลซ์ 0 ดังนี้:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "จากเทอร์มินัล 1 ให้รันคำสั่งการฝึกอบรมสำหรับส่วนที่ 1 ไปพร้อมๆ กันดังนี้:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "ตารางนี้ครอบคลุมรายละเอียดเกี่ยวกับวิธีการแปลชื่อตัวแปร MaxText เป็น Pax
โปรดทราบว่า MaxText มี "มาตราส่วน" ซึ่งจะคูณกับพารามิเตอร์หลายตัว (base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads) สำหรับค่าสุดท้าย
อีกสิ่งหนึ่งที่ต้องกล่าวถึงคือในขณะที่ Pax ครอบคลุม DCN และ ICN MESH_SHAPE เป็นอาร์เรย์ ใน MaxText จะมีตัวแปร data_parallelism, fsdp_parallelism และ tensor_parallelism ที่แยกจากกันสำหรับ DCN และ ICI เนื่องจากค่าเหล่านี้ถูกกำหนดเป็น 1 ตามค่าเริ่มต้น เฉพาะตัวแปรที่มีค่ามากกว่า 1 เท่านั้นจึงจะถูกบันทึกลงในตารางการแปลนี้
นั่นคือ ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] และ DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| พักซ์ C4Spmd22BAdam2xv4_128 | แม็กซ์ข้อความ 2xv4-128.sh | (หลังจากใช้สเกลแล้ว) | ||
|---|---|---|---|---|
| ขนาด (ใช้กับตัวแปร 4 ตัวถัดไป) | 3 | |||
| NUM_LAYERS | 48 | base_num_decoder_layers | 16 | 48 |
| MODEL_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| HIDDEN_DIMS | 24576 | MODEL_DIMS * 4 (= ฐาน_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | head_dim | 256 | |
| PERCORE_BATCH_SIZE | 16 | ต่อ_อุปกรณ์_ชุด_ขนาด | 16 | |
| MAX_SEQ_LEN | 1,024 | สูงสุด_เป้าหมาย_ความยาว | 1,024 | |
| VOCAB_SIZE | 32768 | คำศัพท์_ขนาด | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | ประเภท | bfloat16 | |
| USE_REPEATED_LAYER | จริง | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_parallelism | 64 | |
| DCN_MESH_SHAPE | [2, 1, 1] | dcn_data_parallelism | 2 |
อินพุตเป็นอินสแตนซ์ของคลาส BaseInput สำหรับรับข้อมูลเข้าสู่โมเดลสำหรับฝึกฝน/ประเมินผล/ถอดรหัส
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass มันทำหน้าที่เหมือนตัววนซ้ำ: get_next() ส่งคืน NestedMap โดยที่แต่ละฟิลด์เป็นอาร์เรย์ตัวเลขที่มีขนาดแบตช์เป็นมิตินำหน้า
แต่ละอินพุตได้รับการกำหนดค่าโดยคลาสย่อยของ BaseInput.HParams ในหน้านี้ เราใช้ p เพื่อแสดงอินสแตนซ์ของ BaseInput.Params และอินสแตนซ์ของ input
ใน Pax ข้อมูลจะเป็นหลายโฮสต์เสมอ: แต่ละกระบวนการ Jax จะมี input ที่แยกจากกันและเป็นอิสระที่สร้างอินสแตนซ์ พารามิเตอร์ของพวกเขาจะมี p.infeed_host_index ที่แตกต่างกัน ซึ่งตั้งค่าโดยอัตโนมัติโดย Pax
ดังนั้น ขนาดแบตช์โลคัลที่เห็นในแต่ละโฮสต์คือ p.batch_size และขนาดแบตช์ส่วนกลางคือ (p.batch_size * p.num_infeed_hosts) เรามักจะเห็น p.batch_size ตั้งค่าเป็น jax.local_device_count() * PERCORE_BATCH_SIZE
เนื่องจากลักษณะมัลติโฮสต์นี้ input จึงต้องถูกแบ่งส่วนอย่างเหมาะสม
สำหรับการฝึก แต่ละ input จะต้องไม่ปล่อยแบทช์ที่เหมือนกัน และสำหรับการประเมินชุดข้อมูลที่จำกัด แต่ละ input จะต้องสิ้นสุดหลังจากจำนวนแบตช์เท่ากัน ทางออกที่ดีที่สุดคือการใช้อินพุตในการแบ่งส่วนข้อมูลอย่างเหมาะสม โดยที่แต่ละ input บนโฮสต์ที่แตกต่างกันจะไม่ทับซ้อนกัน หากไม่สำเร็จ เราสามารถใช้เมล็ดสุ่มที่แตกต่างกันเพื่อหลีกเลี่ยงชุดที่ซ้ำกันระหว่างการฝึก
input.reset() ไม่เคยถูกเรียกใช้กับข้อมูลการฝึกอบรม แต่สามารถเรียกใช้ข้อมูล eval (หรือถอดรหัส) ได้
สำหรับการรัน eval (หรือถอดรหัส) แต่ละครั้ง Pax จะดึง N แบทช์จาก input โดยการเรียก input.get_next() N ครั้ง จำนวนแบตช์ที่ใช้ N อาจเป็นจำนวนคงที่ที่ระบุโดยผู้ใช้ ผ่านทาง p.eval_loop_num_batches ; หรือ N อาจเป็นไดนามิก ( p.eval_loop_num_batches=None ) เช่น เราเรียก input.get_next() จนกว่าเราจะใช้ข้อมูลทั้งหมดจนหมด (โดยเพิ่ม StopIteration หรือ tf.errors.OutOfRange )
หาก p.reset_for_eval=True ระบบจะละเว้น p.eval_loop_num_batches และ N จะถูกกำหนดแบบไดนามิกเป็นจำนวนแบตช์ที่ใช้ข้อมูลหมด ในกรณีนี้ p.repeat ควรตั้งค่าเป็น False เนื่องจากมิฉะนั้นจะนำไปสู่การถอดรหัส/eval ที่ไม่มีที่สิ้นสุด
หาก p.reset_for_eval=False Pax จะดึงข้อมูล p.eval_loop_num_batches แบทช์ ควรตั้งค่าด้วย p.repeat=True เพื่อให้ข้อมูลไม่หมดก่อนเวลาอันควร
โปรดทราบว่าอินพุต LingvoEvalAdaptor จำเป็นต้องมี p.reset_for_eval=True
N : คงที่ | N : ไดนามิก | |
|---|---|---|
p.reset_for_eval=True | การดำเนินการประเมินแต่ละครั้งจะใช้ | หนึ่งยุคต่อการดำเนินการประเมินผล |
: : N ชุดแรก ไม่ใช่ : eval_loop_num_batches : | ||
| : : รองรับแล้ว : ถูกละเลย ข้อมูลเข้าต้อง: | ||
| : : : มีขอบเขต : : : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | การเรียกใช้การประเมินแต่ละครั้งจะใช้ | ไม่รองรับ. |
: : ไม่ทับซ้อนกัน N : : | ||
| : : เป็นกลุ่มๆ กลิ้งๆ : : | ||
| : : พื้นฐาน ตาม : : | ||
: : eval_loop_num_batches : : | ||
| - การป้อนข้อมูลจะต้องทำซ้ำ : : | ||
| : : ตลอดไป : : | ||
: : ( p.repeat=True ) หรือ : : | ||
| : : มิฉะนั้นอาจเพิ่ม : : | ||
| : : ข้อยกเว้น : : |
หากรัน decode/eval บน epoch เดียวเท่านั้น (เช่น เมื่อ p.reset_for_eval=True ) อินพุตจะต้องจัดการการแบ่งส่วนอย่างถูกต้อง เพื่อให้แต่ละชาร์ดเพิ่มขึ้นในขั้นตอนเดียวกันหลังจากสร้างแบตช์ในจำนวนที่เท่ากันทุกประการ ซึ่งมักจะหมายความว่าอินพุตจะต้องวางข้อมูลการประเมิน ซึ่งจะดำเนินการโดยอัตโนมัติโดย SeqIOInput และ LingvoEvalAdaptor (ดูเพิ่มเติมด้านล่าง)
สำหรับอินพุตส่วนใหญ่ เราจะเรียกเฉพาะ get_next() เพื่อดึงข้อมูลเป็นชุด ข้อมูลการประเมินประเภทหนึ่งเป็นข้อยกเว้น โดยที่ "วิธีคำนวณเมตริก" ถูกกำหนดไว้บนออบเจ็กต์อินพุตด้วยเช่นกัน
สิ่งนี้รองรับเฉพาะกับ SeqIOInput ที่กำหนดเกณฑ์มาตรฐาน eval ตามรูปแบบบัญญัติบางประการ โดยเฉพาะอย่างยิ่ง Pax ใช้ predict_metric_fns และ score_metric_fns() ที่กำหนดไว้ในงาน SeqIO เพื่อคำนวณตัววัดประเมินผล (แม้ว่า Pax จะไม่ขึ้นอยู่กับผู้ประเมิน SeqIO โดยตรง)
เมื่อแบบจำลองใช้อินพุตหลายอินพุต ทั้งระหว่างการฝึก/การประเมิน หรือข้อมูลการฝึกที่แตกต่างกันระหว่างการฝึกล่วงหน้า/การปรับแต่งอย่างละเอียด ผู้ใช้จะต้องตรวจสอบให้แน่ใจว่าโทเค็นที่ใช้โดยอินพุตนั้นเหมือนกัน โดยเฉพาะอย่างยิ่งเมื่อนำเข้าอินพุตที่แตกต่างกันที่นำไปใช้โดยผู้อื่น
ผู้ใช้สามารถตรวจสอบโทเค็นไนเซอร์ได้โดยการถอดรหัสรหัสบางส่วนด้วย input.ids_to_strings()
เป็นความคิดที่ดีเสมอที่จะตรวจสอบข้อมูลโดยดูจากแบทช์สองสามชุด ผู้ใช้สามารถสร้างพารามิเตอร์ซ้ำใน colab และตรวจสอบข้อมูลได้อย่างง่ายดาย:
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) โดยทั่วไปข้อมูลการฝึกอบรมไม่ควรใช้การสุ่มตัวอย่างแบบตายตัว เนื่องจากถ้างานการฝึกถูกยึดไว้ก่อน ข้อมูลการฝึกจะเริ่มทำซ้ำเอง โดยเฉพาะอย่างยิ่งสำหรับอินพุต Lingvo เราขอแนะนำให้ตั้งค่า p.input.file_random_seed = 0 สำหรับข้อมูลการฝึก
เพื่อทดสอบว่าการแบ่งส่วนได้รับการจัดการอย่างถูกต้องหรือไม่ ผู้ใช้สามารถตั้งค่าที่แตกต่างกันสำหรับ p.num_infeed_hosts, p.infeed_host_index ด้วยตนเอง และดูว่าอินพุตที่สร้างอินสแตนซ์ปล่อยแบตช์ที่แตกต่างกันหรือไม่
Pax รองรับอินพุต 3 ประเภท: SeqIO, Lingvo และกำหนดเอง
SeqIOInput สามารถใช้เพื่อนำเข้าชุดข้อมูลได้
อินพุต SeqIO จัดการการแบ่งส่วนและการขยายข้อมูลการประเมินที่ถูกต้องโดยอัตโนมัติ
สามารถใช้ LingvoInputAdaptor เพื่อนำเข้าชุดข้อมูลได้
อินพุตได้รับการมอบหมายอย่างเต็มที่ให้กับการใช้งาน Lingvo ซึ่งอาจจัดการการแบ่งส่วนโดยอัตโนมัติหรือไม่ก็ได้
สำหรับการนำอินพุต Lingvo ที่ใช้ GenericInput ไปใช้โดยใช้ packing_factor แบบคงที่ เราขอแนะนำให้ใช้ LingvoInputAdaptorNewBatchSize เพื่อระบุขนาดแบตช์ที่ใหญ่กว่าสำหรับอินพุต Lingvo ภายใน และใส่ขนาดแบตช์ที่ต้องการ (โดยปกติจะเล็กกว่ามาก) ลงใน p.batch_size
สำหรับข้อมูล eval เราขอแนะนำให้ใช้ LingvoEvalAdaptor เพื่อจัดการชาร์ดดิ้งและแพดดิ้งสำหรับการรัน eval มากกว่าหนึ่งยุค
คลาสย่อยที่กำหนดเองของ BaseInput ผู้ใช้ใช้คลาสย่อยของตนเอง โดยทั่วไปจะใช้ tf.data หรือ SeqIO
ผู้ใช้ยังสามารถสืบทอดคลาสอินพุตที่มีอยู่เพื่อปรับแต่งเฉพาะการประมวลผลภายหลังของแบตช์เท่านั้น ตัวอย่างเช่น:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchไฮเปอร์พารามิเตอร์เป็นส่วนสำคัญในการกำหนดโมเดลและการกำหนดค่าการทดลอง
เพื่อผสานรวมกับเครื่องมือ Python ได้ดียิ่งขึ้น Pax/Praxis จะใช้รูปแบบการกำหนดค่าตามคลาสข้อมูล pythonic สำหรับไฮเปอร์พารามิเตอร์
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0นอกจากนี้ยังเป็นไปได้ที่จะซ้อนคลาสข้อมูล HParams ในตัวอย่างด้านล่าง คุณลักษณะ linear_tpl คือ Linear.HParams ที่ซ้อนกัน
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )เลเยอร์แสดงถึงฟังก์ชันที่กำหนดเองโดยอาจมีพารามิเตอร์ที่ฝึกได้ เลเยอร์สามารถมีเลเยอร์อื่นเป็นเลเยอร์ย่อยได้ เลเยอร์เป็นส่วนสำคัญของโมเดล เลเยอร์สืบทอดมาจาก Flax nn.Module
โดยทั่วไปเลเยอร์จะกำหนดสองวิธี:
วิธีการนี้จะสร้างตุ้มน้ำหนักที่ฝึกได้และชั้นลูก
วิธีนี้จะกำหนดฟังก์ชันการเผยแพร่ไปข้างหน้า โดยคำนวณเอาต์พุตบางส่วนตามอินพุต นอกจากนี้ fprop อาจเพิ่มบทสรุปหรือติดตามการสูญเสียเสริม
Fiddle เป็นไลบรารีการกำหนดค่าแบบโอเพ่นซอร์สที่ใช้ Python เป็นอันดับแรก ซึ่งออกแบบมาสำหรับแอปพลิเคชัน ML Pax/Praxis รองรับการทำงานร่วมกันกับ Fiddle Config/Partial และคุณสมบัติขั้นสูงบางอย่าง เช่น การตรวจสอบข้อผิดพลาดที่กระตือรือร้นและพารามิเตอร์ที่ใช้ร่วมกัน
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )การใช้ Fiddle สามารถกำหนดค่าเลเยอร์ให้แชร์ได้ (เช่น สร้างอินสแตนซ์เพียงครั้งเดียวด้วยน้ำหนักที่ฝึกได้ที่ใช้ร่วมกัน)
โมเดลกำหนดเครือข่ายเพียงอย่างเดียว โดยทั่วไปจะเป็นคอลเลกชันของเลเยอร์และกำหนดอินเทอร์เฟซสำหรับการโต้ตอบกับโมเดล เช่น การถอดรหัส เป็นต้น
ตัวอย่างโมเดลพื้นฐานบางส่วนได้แก่:
งานประกอบด้วยแบบจำลองและผู้เรียน/เครื่องมือเพิ่มประสิทธิภาพอีกหนึ่งรายการ คลาสย่อยของงานที่ง่ายที่สุดคือ SingleTask ซึ่งต้องการ Hparams ต่อไปนี้:
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| เวอร์ชัน PPI | ให้สัญญา |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


