datablations
1.0.0
พื้นที่เก็บข้อมูลนี้ให้ภาพรวมของส่วนประกอบทั้งหมดจากรายงาน Scaling Data-Constrained Language Models พูดคุยบนกระดาษ:
เราตรวจสอบแบบจำลองภาษาที่ปรับขนาดในระบบที่มีข้อจำกัดด้านข้อมูล เราทำการทดลองชุดใหญ่ซึ่งมีขอบเขตของการทำซ้ำข้อมูลและงบประมาณในการประมวลผลที่แตกต่างกันออกไป โดยมีโทเค็นการฝึกอบรมสูงถึง 900 พันล้านโทเค็นและโมเดลพารามิเตอร์ 9 พันล้านรายการ จากการรันของเรา เราได้เสนอและตรวจสอบกฎการปรับขนาดเพื่อเพิ่มประสิทธิภาพในการประมวลผลโดยพิจารณาจากค่าที่ลดลงของโทเค็นที่ซ้ำกันและพารามิเตอร์ที่มากเกินไป นอกจากนี้เรายังทดลองแนวทางในการบรรเทาความขาดแคลนข้อมูล รวมถึงการเพิ่มชุดข้อมูลการฝึกอบรมด้วยข้อมูลโค้ด การกรองความยุ่งยาก และการขจัดข้อมูลซ้ำซ้อน โมเดลและชุดข้อมูลจากการฝึกอบรม 400 ครั้งของเรามีให้ใช้งานผ่านพื้นที่เก็บข้อมูลนี้
เราทดลองกับข้อมูลซ้ำบน C4 และการแยก OSCAR ภาษาอังกฤษที่ไม่ซ้ำกัน สำหรับแต่ละชุดข้อมูล เราจะดาวน์โหลดข้อมูลและแปลงเป็นไฟล์ jsonl ไฟล์เดียว c4.jsonl และ oscar_en.jsonl ตามลำดับ
จากนั้นเราจะตัดสินใจเกี่ยวกับจำนวนโทเค็นที่ไม่ซ้ำกันและจำนวนตัวอย่างตามลำดับที่เราต้องการจากชุดข้อมูล โปรดทราบว่า C4 มีโทเค็น 478.625834583 ต่อตัวอย่าง และ OSCAR มี 1312.0951072 พร้อม GPT2Tokenizer ซึ่งคำนวณโดยการโทเค็นชุดข้อมูลทั้งหมดและหารจำนวนโทเค็นด้วยจำนวนตัวอย่าง เราใช้ตัวเลขเหล่านี้เพื่อคำนวณตัวอย่างที่ต้องการ
ตัวอย่างเช่น สำหรับโทเค็นที่ไม่ซ้ำกัน 1.9B เราต้องการตัวอย่าง 1.9B / 478.625834583 = 3969697.96178 สำหรับ C4 และ 1.9B / 1312.0951072 = 1448065.76107 ตัวอย่างสำหรับ OSCAR หากต้องการสร้างข้อมูลเป็นโทเค็น อันดับแรกเราต้องโคลนพื้นที่เก็บข้อมูล Megatron-DeepSpeed และปฏิบัติตามคำแนะนำในการตั้งค่า จากนั้นเราเลือกตัวอย่างเหล่านี้และทำโทเค็นดังต่อไปนี้:
ค4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64ออสการ์:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 โดยที่ gpt2 ชี้ไปยังโฟลเดอร์ที่มีไฟล์ทั้งหมดจาก https://huggingface.co/gpt2/tree/main เมื่อใช้ head เราตรวจสอบให้แน่ใจว่าชุดย่อยที่แตกต่างกันจะมีตัวอย่างที่ทับซ้อนกันเพื่อลดการสุ่ม
สำหรับการประเมินระหว่างการฝึกอบรมและการประเมินขั้นสุดท้าย เราใช้ชุดการตรวจสอบสำหรับ C4:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 สำหรับ OSCAR ที่ไม่มีชุดการตรวจสอบอย่างเป็นทางการ เราจะเป็นส่วนหนึ่งของการฝึกอบรมที่กำหนดโดยทำ tail -364608 oscar_en.jsonl > oscarvalidation.jsonl จากนั้นทำโทเค็นดังต่อไปนี้:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2เราได้อัปโหลดชุดย่อยที่ประมวลผลล่วงหน้าหลายชุดสำหรับการใช้งานกับเมกะตรอน:
ไฟล์ bin บางไฟล์มีขนาดใหญ่เกินไปสำหรับ git จึงแยกโดยใช้ เช่น split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. และ split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. - หากต้องการใช้สำหรับการฝึก คุณต้องรวมเข้าด้วยกันอีกครั้งโดยใช้ cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin และ cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin
เราทดลองผสมโค้ดกับข้อมูลภาษาธรรมชาติโดยใช้การแยก Python จาก the-stack-dedup เราดาวน์โหลดข้อมูล แปลงเป็นไฟล์ jsonl ไฟล์เดียว และประมวลผลล่วงหน้าโดยใช้แนวทางเดียวกับที่อธิบายไว้ข้างต้น
เราได้อัปโหลดเวอร์ชันที่ประมวลผลล่วงหน้าสำหรับการใช้งานกับเมกะตรอนที่นี่: https://huggingface.co/datasets/datablations/python-megatron เราได้แยกไฟล์ bin โดยใช้ split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. ดังนั้นคุณจึงต้องรวมเข้าด้วยกันอีกครั้งโดยใช้ cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin สำหรับการฝึกอบรม
เราสร้างเวอร์ชันของ C4 และ OSCAR ที่มีความฉงนสนเท่ห์และการกรองข้อมูลเมตาที่เกี่ยวข้องกับการขจัดข้อมูลซ้ำซ้อน:
หากต้องการสร้างชุดข้อมูลเมตาดาต้าเหล่านี้ขึ้นใหม่ มีคำแนะนำอยู่ที่ filtering/README.md
เรามีเวอร์ชันโทเค็นที่สามารถใช้สำหรับการฝึกอบรมกับ Megatron ได้ที่:
ไฟล์ .bin ถูกแบ่งโดยใช้สิ่งที่ต้องการ split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. ดังนั้นคุณต้องต่อกลับเข้าด้วยกันผ่าน cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin
หากต้องการสร้างเวอร์ชันโทเค็นที่กำหนดชุดข้อมูลเมตาขึ้นมาใหม่
filtering/deduplication/filter_oscar_jsonl.pyเมื่อต้องการสร้างเปอร์เซ็นไทล์ความฉงนสนเท่ห์ ให้ทำตามคำแนะนำด้านล่าง
ค4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )ออสการ์:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )จากนั้น คุณสามารถโทเค็นไฟล์ jsonl ที่เป็นผลลัพธ์สำหรับการฝึกกับ Megatron ตามที่อธิบายไว้ในส่วนการทำซ้ำ
C4: สำหรับ C4 คุณเพียงแค่ต้องลบตัวอย่างทั้งหมดที่มีการเติมฟิลด์ repetitions เช่น
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: สำหรับ OSCAR เรามีสคริปต์ที่ filtering/filter_oscar_jsonl.py เพื่อสร้างชุดข้อมูลที่กรองข้อมูลที่ซ้ำกันออก โดยให้ชุดข้อมูลที่มีการกรองข้อมูลเมตา
จากนั้น คุณสามารถโทเค็นไฟล์ jsonl ที่เป็นผลลัพธ์สำหรับการฝึกกับ Megatron ตามที่อธิบายไว้ในส่วนการทำซ้ำ
สามารถดาวน์โหลดทุกรุ่นได้ที่ https://huggingface.co/datablations
โดยทั่วไปแล้ว โมเดลจะมีชื่อดังนี้: lm1-{parameters}-{tokens}-{unique_tokens} โดยเฉพาะแต่ละโมเดลในโฟลเดอร์จะมีชื่อว่า: {parameters}{tokens}{unique_tokens}{optional specifier} เช่น 1b12b8100m จะเป็น 1.1 พันล้านพารามิเตอร์ 2.8 พันล้านโทเค็น 100 ล้านโทเค็นที่ไม่ซ้ำกัน อนุสัญญา xby ( 1b1 , 2b8 ฯลฯ ) ทำให้เกิดความคลุมเครือว่าตัวเลขเป็นของพารามิเตอร์หรือโทเค็น แต่คุณสามารถตรวจสอบสคริปต์ sbatch ในโฟลเดอร์ที่เกี่ยวข้องได้ตลอดเวลาเพื่อดูพารามิเตอร์ / โทเค็น / โทเค็นเฉพาะที่แน่นอน หากคุณต้องการแปลงโมเดลที่ยังไม่ได้แปลงเป็น huggingface/transformers คุณสามารถทำตามคำแนะนำในการฝึกอบรม
วิธีที่ง่ายที่สุดในการดาวน์โหลดโมเดลเดียวคือ:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 หากใช้เวลานานเกินไป คุณสามารถใช้ wget เพื่อดาวน์โหลดไฟล์แต่ละไฟล์จากโฟลเดอร์ได้โดยตรง เช่น:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.ptสำหรับแบบจำลองที่สอดคล้องกับการทดลองในรายงาน ให้ศึกษาจากแหล่งเก็บข้อมูลต่อไปนี้:
lm1-misc/*dedup* สำหรับการเปรียบเทียบการขจัดความซ้ำซ้อนกับโทเค็นที่ไม่ซ้ำกัน 100M ในภาคผนวกรุ่นอื่นๆ ที่ไม่ได้วิเคราะห์ในรายงาน:
เราฝึกโมเดลด้วย Megatron-DeepSpeed ที่ทำงานร่วมกับ AMD GPU (ผ่าน ROCm): https://github.com/TurkuNLP/Megatron-DeepSpeed หากคุณต้องการใช้ NVIDIA GPU (ผ่าน cuda) คุณสามารถใช้ ห้องสมุดดั้งเดิม: https://github.com/bigscience-workshop/Megatron-DeepSpeed
คุณต้องปฏิบัติตามคำแนะนำในการตั้งค่าของพื้นที่เก็บข้อมูลแห่งใดแห่งหนึ่งเพื่อสร้างสภาพแวดล้อมของคุณ (การตั้งค่าของเราเฉพาะสำหรับ LUMI มีรายละเอียดอยู่ใน training/megdssetup.md )
แต่ละโฟลเดอร์โมเดลจะมีสคริปต์ชุดงานที่ใช้ในการฝึกโมเดล คุณสามารถใช้สิ่งเหล่านี้เป็นข้อมูลอ้างอิงเพื่อฝึกโมเดลของคุณเองโดยปรับใช้ตัวแปรสภาพแวดล้อมที่จำเป็น สคริปต์ satch อ้างอิงไฟล์เพิ่มเติมบางไฟล์:
*txt ที่ระบุเส้นทางข้อมูล คุณสามารถค้นหาได้ที่ utils/datapaths/* อย่างไรก็ตาม คุณอาจต้องปรับเส้นทางให้ชี้ไปยังชุดข้อมูลของคุณmodel_params.sh ซึ่งอยู่ที่ utils/model_params.sh และมีการตั้งค่าสถาปัตยกรรมล่วงหน้าlaunch.sh ที่คุณสามารถหาได้ที่ training/launch.sh ประกอบด้วยคำสั่งเฉพาะสำหรับการตั้งค่าของเรา ซึ่งคุณอาจต้องการลบออก หลังการฝึกอบรม คุณสามารถแปลงโมเดลของคุณเป็นหม้อแปลงได้ด้วย เช่น python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1
สำหรับโมเดลที่ทำซ้ำ เรายังอัปโหลดเทนเซอร์บอร์ดหลังการฝึกโดยใช้ เช่น tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" ซึ่งทำให้ง่ายต่อการใช้สำหรับการแสดงภาพในรายงาน
สำหรับการระเหย muP ในภาคผนวก เราใช้สคริปต์ที่ training_scripts/mup.py มันมีคำแนะนำในการตั้งค่า
คุณสามารถใช้สูตรของเราในการคำนวณการสูญเสียที่คาดหวังโดยพิจารณาจากพารามิเตอร์ ข้อมูล และโทเค็นที่ไม่ซ้ำกันดังนี้:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
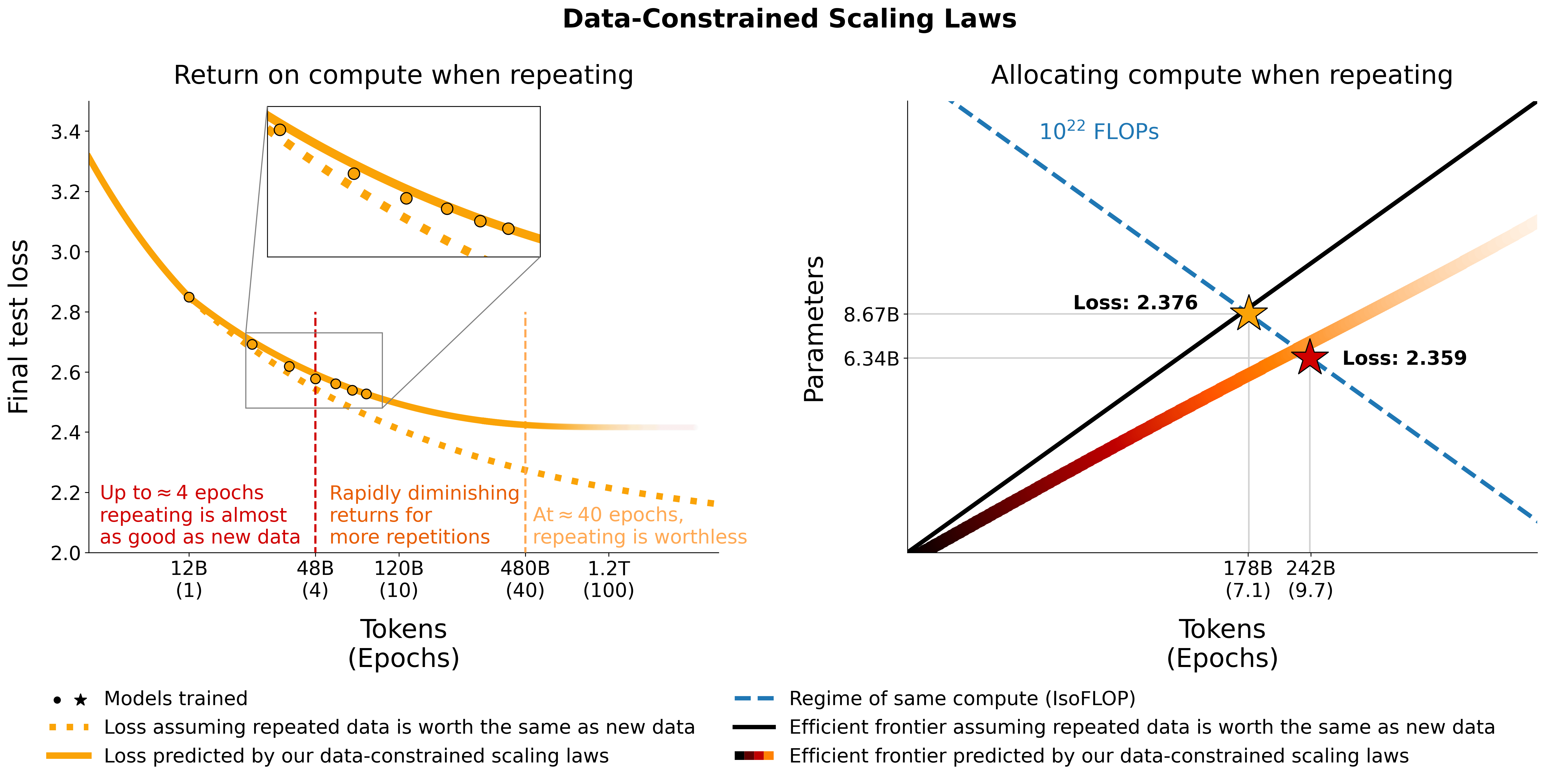
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867โปรดทราบว่าค่าการสูญเสียที่เกิดขึ้นจริงไม่น่าจะมีประโยชน์ แต่เป็นแนวโน้มของการสูญเสีย เช่น จำนวนพารามิเตอร์ที่เพิ่มขึ้น หรือเพื่อเปรียบเทียบสองแบบจำลองเหมือนในตัวอย่างข้างต้น เพื่อคำนวณการจัดสรรที่เหมาะสมที่สุด คุณสามารถใช้การค้นหากริดแบบง่ายๆ:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test หากคุณได้รับนิพจน์รูปแบบปิดเพื่อการจัดสรรที่เหมาะสมที่สุดแทนการค้นหาตารางด้านบน โปรดแจ้งให้เราทราบ :) เราเหมาะสมกับกฎหมายการปรับขนาดที่จำกัดด้วยข้อมูลและค่าสัมประสิทธิ์การปรับขนาด C4 โดยใช้โค้ดที่ utils/parametric_fit.ipynb เทียบเท่ากับ colab นี้ .
Training > Regular models เพื่อตั้งค่าสภาพแวดล้อมการฝึกอบรมpip install git+https://github.com/EleutherAI/lm-evaluation-harness.git เราใช้เวอร์ชัน 0.2.0 แต่เวอร์ชันที่ใหม่กว่าก็ควรใช้งานได้เช่นกันsbatch utils/eval_rank.sh โดยแก้ไขตัวแปรที่จำเป็นในสคริปต์ก่อนpython Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.jsonaddtasks ของชุดประเมินผล: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 เช่นข้อกำหนดทั้งหมดยกเว้น promptsource ซึ่งติดตั้งจากทางแยกพร้อมแจ้งที่ถูกต้องsbatch utils/eval_generative.sh โดยแก้ไขตัวแปรที่จำเป็นในสคริปต์ก่อนpython utils/merge_generative.py จากนั้นแปลงเป็น csv ด้วย python utils/csv_generative.py merged.jsonbabi ของสายรัดประเมินผล: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (โปรดทราบว่าสาขานี้เข้ากันไม่ได้กับสาขา addtasks สำหรับงานกำเนิดเนื่องจากมันมาจาก EleutherAI/lm-evaluation-harness ในขณะที่ addtasks จะขึ้นอยู่กับ bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh โดยแก้ไขตัวแปรที่จำเป็นในสคริปต์ก่อน plotstables/return_alloc.pdf , plotstables/return_alloc.ipynb , colabplotstables/dataset_setup.pdf , plotstables/dataset_setup.ipynb , colabplotstables/contours.pdf , plotstables/contours.ipynb , colabplotstables/isoflops_training.pdf , plotstables/isoflops_training.ipynb , colabplotstables/return.pdf , plotstables/return.ipynb , colabplotstables/strategies.pdf , plotstables/strategies.drawioplotstables/beyond.pdf , plotstables/beyond.ipynb , colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf & colab เดียวกันกับรูปที่ 3plotstables/mup.pdf , plotstables/dd.pdf , plotstables/dedup.pdf , plotstables/mup_dd_dd.ipynb , colabplotstables/isoloss_alphabeta_100m.pdf & colab เดียวกันกับรูปที่ 3plotstables/galactica.pdf , plotstables/galactica.ipynb , colabtraining_c4.pdf , validation_c4oscar.pdf , training_oscar.pdf , validation_epochs_c4oscar.pdf และ colab เดียวกันกับรูปที่ 4plotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf , plotstables/training_validation_filter.pdf , plotstables/beyond_losses.ipynb & colabutils/parametric_fit.ipynb ซึ่งเทียบเท่ากับ colab นี้plotstables/repetition.ipynb & colabplotstables/python.ipynb & colabplotstables/filtering.ipynb & colabโมเดลและรหัสทั้งหมดได้รับอนุญาตภายใต้ Apache 2.0 ชุดข้อมูลที่กรองแล้วจะถูกเผยแพร่โดยมีใบอนุญาตเดียวกันกับชุดข้อมูลที่มาจากชุดข้อมูลเหล่านั้น
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

