INTR
1.0.0
การซื้อคืนนี้เป็นการดำเนินการอย่างเป็นทางการของ INTR: A Simple Interpretable Transformer for Fine-grained Image Classification and Analysis ขณะนี้มีโค้ดและแบบจำลองสำหรับการตีความข้อมูลที่ละเอียด เราจะให้ลิงก์ไปยังการพิจารณาคดี ICLR 2024 ที่กำลังจะมีขึ้นสำหรับเอกสารนี้เมื่อเผยแพร่ทางออนไลน์
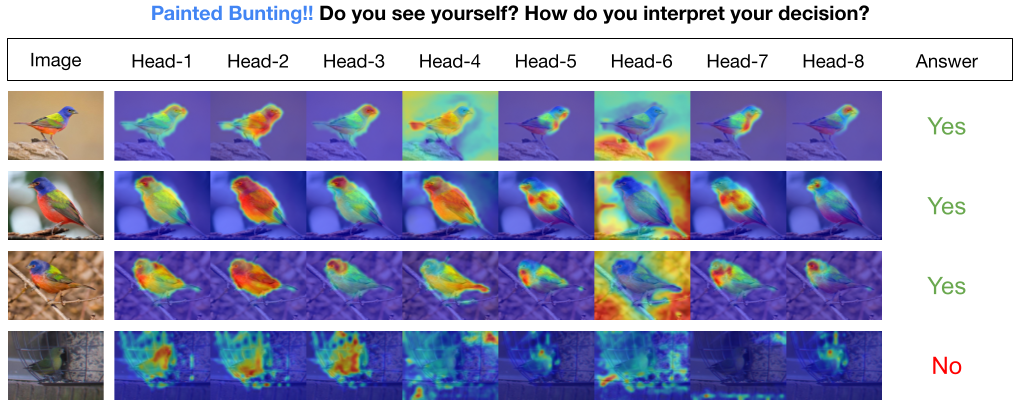
INTR เป็นการใช้ Transformers แบบใหม่เพื่อทำให้การจำแนกประเภทภาพสามารถตีความได้ ใน INTR เราตรวจสอบแนวทางเชิงรุกในการจัดหมวดหมู่ โดยขอให้แต่ละชั้นเรียนค้นหาตัวเองในภาพ เราเรียนรู้ข้อความค้นหาเฉพาะชั้นเรียน (หนึ่งรายการสำหรับแต่ละชั้นเรียน) เป็นอินพุตไปยังตัวถอดรหัส ช่วยให้พวกเขาสามารถค้นหาการมีอยู่ในภาพผ่านการสนใจแบบข้ามความสนใจ เราแสดงให้เห็นว่า INTR สนับสนุนให้แต่ละชั้นเรียนเข้าร่วมอย่างชัดเจน ตุ้มน้ำหนักข้ามความสนใจจึงเป็นการตีความที่มีความหมายของการทำนายของแบบจำลอง สิ่งที่น่าสนใจคือ จากการเอาใจใส่แบบหลายหัว INTR สามารถเรียนรู้ที่จะจำกัดคุณลักษณะต่างๆ ของคลาส ทำให้เหมาะอย่างยิ่งสำหรับการจำแนกประเภทและการวิเคราะห์แบบละเอียด
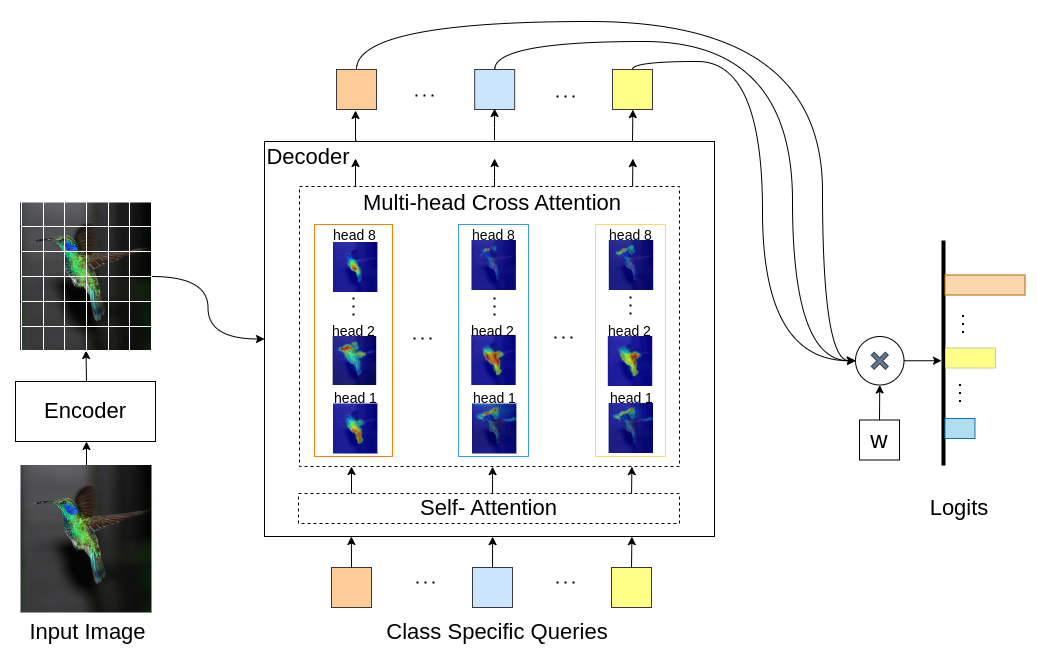
ในโมเดล INTR แต่ละแบบสอบถามในตัวถอดรหัสมีหน้าที่ในการทำนายคลาส ดังนั้น แบบสอบถามจะพิจารณาตัวเองเพื่อค้นหาคุณลักษณะเฉพาะของคลาสจากแผนผังคุณลักษณะ อันดับแรก เราจะเห็นภาพแผนผังคุณลักษณะ เช่น เมทริกซ์ค่าของสถาปัตยกรรมหม้อแปลงไฟฟ้า เพื่อดูส่วนสำคัญของวัตถุในภาพ ในการค้นหาคุณลักษณะเฉพาะที่โมเดลให้ความสนใจในเมทริกซ์ค่า เราจะแสดงแผนที่ความร้อนของความสนใจของโมเดล เพื่อหลีกเลี่ยงการรบกวนจากภายนอกในการจำแนกประเภท เราจะใช้เวกเตอร์น้ำหนักที่ใช้ร่วมกันในการจำแนกประเภท ดังนั้น น้ำหนักความสนใจจึงอธิบายการทำนายของแบบจำลอง
INTR บนแบ็คโบน DETR-R50 ประสิทธิภาพการจำแนก และแบบจำลองที่ได้รับการปรับแต่งบนชุดข้อมูลต่างๆ
| ชุดข้อมูล | บัญชี@1 | บัญชี@5 | แบบอย่าง |
|---|---|---|---|
| คิวบี | 71.8 | 89.3 | ดาวน์โหลดด่าน |
| นก | 97.4 | 99.2 | ดาวน์โหลดด่าน |
| ผีเสื้อ | 95.0 | 98.3 | ดาวน์โหลดด่าน |
สร้างสภาพแวดล้อมหลาม (ไม่บังคับ)
conda create -n intr python=3.8 -y
conda activate intrโคลนพื้นที่เก็บข้อมูล
git clone https://github.com/dipanjyoti/INTR.git
cd INTRติดตั้งการพึ่งพาหลาม
pip install -r requirements.txtทำตามรูปแบบด้านล่างสำหรับข้อมูล
datasets
├── dataset_name
│ ├── train
│ │ ├── class1
│ │ │ ├── img1.jpeg
│ │ │ ├── img2.jpeg
│ │ │ └── ...
│ │ ├── class2
│ │ │ ├── img3.jpeg
│ │ │ └── ...
│ │ └── ...
│ └── val
│ ├── class1
│ │ ├── img4.jpeg
│ │ ├── img5.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img6.jpeg
│ │ └── ...
│ └── ...
ในการประเมินประสิทธิภาพของ INTR บนชุดข้อมูล CUB บนการตั้งค่า multi-GPU (เช่น 4 GPUs) ให้ดำเนินการคำสั่งด้านล่าง จุดตรวจ INTR อยู่ที่การปรับแต่งโมเดลและผลลัพธ์
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > หากต้องการสร้างการแสดงภาพการตีความของ INTR ให้ดำเนินการคำสั่งที่ให้มาด้านล่าง คำสั่งนี้จะแสดงการตีความสำหรับคลาสเฉพาะด้วยดัชนี <class_number> โดยค่าเริ่มต้น จะแสดงการตีความจากหัวความสนใจทั้งหมด หากต้องการเน้นไปที่การตีความที่เกี่ยวข้องกับคำค้นหายอดนิยมที่มีป้ายกำกับเป็น top_q เช่นกัน ให้ตั้งค่าพารามิเตอร์ sim_query_heads เป็น 1 ใช้ขนาดแบทช์เป็น 1 สำหรับการแสดงภาพ
python -m tools.visualization --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --class_index < class_number >การคาดคะเนและการแสดงภาพด้วยภาพเดียวเวลาอนุมาน: นอกจากนี้เรายังได้จัดเตรียม Jupyter Notebook, demo.ipynb ซึ่งออกแบบมาเพื่อการคาดคะเนและการแสดงภาพภาพเดียวในระหว่างกระบวนการอนุมาน โปรดทราบว่าการสาธิตจะเน้นไปที่ชุดข้อมูล CUB
หากต้องการเตรียม INTR สำหรับการฝึก ให้ใช้รุ่น DETR-R50 ที่ผ่านการฝึกมาแล้ว หากต้องการฝึกชุดข้อมูลใดชุดหนึ่ง ให้แก้ไข '--num_queries' โดยตั้งค่าเป็นจำนวนคลาสในชุดข้อมูล ภายในสถาปัตยกรรม INTR แต่ละแบบสอบถามในตัวถอดรหัสจะได้รับมอบหมายงานในการจับภาพคุณลักษณะเฉพาะของคลาส ซึ่งหมายความว่าทุกแบบสอบถามสามารถปรับได้ผ่านกระบวนการเรียนรู้ ดังนั้น จำนวนพารามิเตอร์โมเดลทั้งหมดจะเพิ่มขึ้นตามสัดส่วนของจำนวนคลาสในชุดข้อมูล หากต้องการฝึก INTR บนระบบหลาย GPU (เช่น 4 GPU) ให้ดำเนินการคำสั่งด้านล่าง
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --finetune < path/to/detr-r50-e632da11.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --num_queries < num_of_classes > แบบจำลองของเราได้รับแรงบันดาลใจจากวิธี DEtection TRansformer (DETR)
เราขอขอบคุณผู้เขียน DETR สำหรับการทำงานที่ยอดเยี่ยมเช่นนี้
หากคุณพบว่างานของเรามีประโยชน์สำหรับการวิจัยของคุณ โปรดพิจารณาอ้างอิงรายการ BibTeX
@inproceedings{paul2024simple,
title={A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis},
author={Paul, Dipanjyoti and Chowdhury, Arpita and Xiong, Xinqi and Chang, Feng-Ju and Carlyn, David and Stevens, Samuel and Provost, Kaiya and Karpatne, Anuj and Carstens, Bryan and Rubenstein, Daniel and Stewart, Charles and Berger-Wolf, Tanya and Su, Yu and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations},
year={2024}
}

