bida
v0.9.4
pip install -U bida from bida import ChatLLM
llm = ChatLLM (
model_type = 'openai' , # 调用openai的chat模型
model_name = 'gpt-4' ) # 设定模型为:gpt-4,默认是gpt3.5
result = llm . chat ( "从1加到100等于多少?只计算奇数相加呢?" )
print ( result ) from bida import ChatLLM
llm = ChatLLM (
model_type = "baidu" , # 调用百度文心一言
stream_callback = ChatLLM . stream_callback_func ) # 使用默认的流式输出函数
llm . chat ( "你好呀,请问你是谁?" ) | บริษัทต้นแบบ | ประเภทรุ่น | ชื่อรุ่น | ไม่ว่าจะสนับสนุน. | แสดงให้เห็น |
|---|---|---|---|---|
| OpenAI | แชท | gpt-3.5, gpt-4 | รองรับรุ่น gpt3.5 และ gpt4 ทั้งหมด | |
| กรอกข้อความ | ข้อความ-ดาวินชี-003 | แบบจำลองคลาสการสร้างข้อความ | ||
| การฝัง | การฝังข้อความ-ada-002 | โมเดลแบบเวกเตอร์ | ||
| ไป่ตู้-เหวิน ซิน ยี่หยาน | แชท | เออร์นี่-บอท, เออร์นี่-บอท-เทอร์โบ | รูปแบบการแชทเชิงพาณิชย์ของ Baidu | |
| การฝัง | การฝัง_v1 | แบบจำลองเวกเตอร์เชิงพาณิชย์ของ Baidu | ||
| โมเดลที่โฮสต์ | โอเพ่นซอร์สรุ่นต่างๆ | สำหรับโมเดลโอเพ่นซอร์สต่างๆ ที่โฮสต์โดย Baidu โปรดกำหนดค่าด้วยตนเองโดยใช้โปรโตคอลการเข้าถึงโมเดลบุคคลที่สามของ Baidu สำหรับรายละเอียด โปรดดูส่วนการเข้าถึงโมเดลด้านล่าง | ||
| อาลีบาบา คลาวด์-ตงอี้ เฉียนเหวิน | แชท | qwen-v1, qwen-plus-v1, qwen-7b-แชท-v1 | รูปแบบการแชทเชิงพาณิชย์และโอเพ่นซอร์สของ Alibaba Cloud | |
| การฝัง | การฝังข้อความ-v1 | โมเดลเวกเตอร์เชิงพาณิชย์ของ Alibaba Cloud | ||
| โมเดลที่โฮสต์ | โอเพ่นซอร์สรุ่นต่างๆ | สำหรับโมเดลโอเพ่นซอร์สประเภทอื่นๆ ที่โฮสต์โดย Alibaba Cloud โปรดกำหนดค่าด้วยตนเองโดยใช้โปรโตคอลการเข้าถึงโมเดลบุคคลที่สามของ Alibaba Cloud สำหรับรายละเอียด โปรดดูส่วนการเข้าถึงโมเดลด้านล่าง | ||
| มินิแม็กซ์ | แชท | เอบับ5, เอบับ5.5 | โมเดลแชทเชิงพาณิชย์ MiniMax | |
| แชทโปร | เอบับ5.5 | โมเดลการแชทเชิงพาณิชย์ MiniMax โดยใช้โหมด Chatcompletion pro แบบกำหนดเอง รองรับสถานการณ์การสนทนาแบบหลายคนและหลายบอท การสนทนาตัวอย่าง ข้อจำกัดรูปแบบการส่งคืน การเรียกใช้ฟังก์ชัน ปลั๊กอิน และฟังก์ชันอื่น ๆ | ||
| การฝัง | embo-01 | โมเดลเวกเตอร์เชิงพาณิชย์ MiniMax | ||
| ภูมิปัญญา AI-ChatGLM | แชท | ChatGLM-Pro, Std, Lite, characterglm | Zipu AI รุ่นใหญ่เชิงพาณิชย์หลายเวอร์ชัน | |
| การฝัง | การฝังข้อความ | โมเดลเวกเตอร์ข้อความเชิงพาณิชย์ Zipu AI | ||
| iFlytek-Spark | แชท | สปาร์คเดสก์ V1.5, V2.0 | iFlytek Spark Cognitive รุ่นใหญ่ | |
| การฝัง | การฝัง | โมเดลเวกเตอร์ข้อความ iFlytek Spark | ||
| SenseTime-RiRiXin | แชท | nova-ptc-xl-v1, nova-ptc-xs-v1 | SenseNova SenseTime รุ่นใหญ่ใหม่ทุกวัน | |
| Baichuan หน่วยสืบราชการลับ | แชท | ไป๋ชวน-53b-v1.0.0 | Baichuan 53B รุ่นใหญ่ | |
| เทนเซ็นต์-ฮุนหยวน | แชท | เทนเซ็นต์ ฮุนหยวน | Tencent Hunyuan รุ่นใหญ่ | |
| โมเดลโอเพ่นซอร์สที่ปรับใช้ด้วยตนเอง | แชท เสร็จสิ้น การฝัง | โอเพ่นซอร์สรุ่นต่างๆ | การใช้โมเดลโอเพ่นซอร์สที่ใช้งานโดย FastChat และการปรับใช้อื่นๆ อินเทอร์เฟซ Web API ที่ให้มาจะเป็นไปตาม RESTful API ที่เข้ากันได้กับ OpenAI และสามารถรองรับได้โดยตรง สำหรับรายละเอียด โปรดดูบทการเข้าถึงโมเดลด้านล่าง | |
สังเกต :
เทคโนโลยีทั้งสองของโมเดล LLM และ prompt word ใน AIGC นั้นใหม่มากและมีการพัฒนาอย่างรวดเร็ว ทฤษฎี บทช่วยสอน เครื่องมือ วิศวกรรม และด้านอื่น ๆ ยังขาดไปมาก เทคโนโลยีสแต็กที่ใช้แทบจะไม่ทับซ้อนกันกับประสบการณ์ของนักพัฒนากระแสหลักในปัจจุบัน : :
| การจำแนกประเภท | การพัฒนากระแสหลักในปัจจุบัน | โครงการด่วน | พัฒนาโมเดล ปรับแต่งโมเดล |
|---|---|---|---|
| ภาษาการพัฒนา | Java, .Net, Javscript, ABAP ฯลฯ | ภาษาธรรมชาติ, ไพธอน | หลาม |
| เครื่องมือในการพัฒนา | และเป็นผู้ใหญ่มาก | ไม่มี | เป็นผู้ใหญ่ |
| เกณฑ์การพัฒนา | ต่ำกว่าและเป็นผู้ใหญ่ | ต่ำแต่ยังไม่บรรลุนิติภาวะมาก | สูงมาก |
| เทคโนโลยีการพัฒนา | ชัดเจนและมั่นคง | ง่ายต่อการเริ่มต้น แต่ยากมากที่จะได้ผลลัพธ์ที่มั่นคง | ซับซ้อนและหลากหลาย |
| เทคนิคที่ใช้กันทั่วไป | เชิงวัตถุ ฐานข้อมูล ข้อมูลขนาดใหญ่ | การปรับแต่งแบบทันที, การเรียนรู้แบบไม่บริบท, การฝัง | หม้อแปลงไฟฟ้า, RLHF, การปรับแต่งแบบละเอียด, LoRA |
| การสนับสนุนโอเพ่นซอร์ส | รวยและเป็นผู้ใหญ่ | สับสนมากในระดับล่าง | รวยแต่ยังไม่บรรลุนิติภาวะ |
| ต้นทุนการพัฒนา | ต่ำ | สูงกว่า | สูงมาก |
| นักพัฒนา | รวย | หายากสุดๆ | หายากมาก |
| พัฒนารูปแบบการทำงานร่วมกัน | พัฒนาตามเอกสารที่ผู้จัดการผลิตภัณฑ์จัดส่ง | บุคคลเพียงคนเดียวหรือทีมงานที่เรียบง่ายสามารถจัดการการดำเนินงานทั้งหมดได้ตั้งแต่ข้อกำหนดไปจนถึงการส่งมอบ | พัฒนาตามทิศทางการวิจัยเชิงทฤษฎี |
ในปัจจุบัน บริษัทเทคโนโลยี บริษัทอินเทอร์เน็ต และบริษัท Big Data เกือบทั้งหมดล้วนอยู่ในทิศทางนี้ แต่บริษัทแบบดั้งเดิมจำนวนมากยังคงอยู่ในภาวะสับสน ไม่ใช่ว่าองค์กรแบบดั้งเดิมไม่ต้องการมัน แต่: 1) พวกเขาไม่มีความสามารถด้านเทคนิค ดังนั้นพวกเขาจึงไม่รู้ว่าต้องทำอย่างไร 2) พวกเขาไม่มีฮาร์ดแวร์สำรอง และพวกเขาไม่มี มีความสามารถที่จะทำสิ่งนั้นได้ 3) ระดับของการทำให้ธุรกิจเป็นดิจิทัลอยู่ในระดับต่ำ และการเปลี่ยนแปลงและการอัพเกรด AIGC มีวงจรที่ยาวนานและผลลัพธ์ที่ช้า
ปัจจุบันมีโมเดลเชิงพาณิชย์และโอเพ่นซอร์สมากเกินไปทั้งในประเทศและต่างประเทศ และพวกเขากำลังพัฒนาอย่างรวดเร็ว อย่างไรก็ตาม API และออบเจ็กต์ข้อมูลของโมเดลนั้นแตกต่างออกไป เมื่อเผชิญกับโมเดลใหม่ (หรือแม้แต่ เวอร์ชันใหม่) เราต้องอ่านเอกสารการพัฒนาและแก้ไขโค้ดแอปพลิเคชันของคุณเองเพื่อนำไปปรับใช้ ฉันเชื่อว่านักพัฒนาแอปพลิเคชันทุกคนได้ทดสอบโมเดลมากมายและต้องทนทุกข์ทรมานจากมัน
แม้ว่าความสามารถของโมเดลจะแตกต่างกัน แต่โดยทั่วไปแล้วโหมดสำหรับการมอบความสามารถจะเหมือนกัน ดังนั้น การมีเฟรมเวิร์กที่สามารถปรับให้เข้ากับ API ของโมเดลจำนวนมากและจัดให้มีโหมดการโทรแบบครบวงจรจึงกลายเป็นสิ่งจำเป็นเร่งด่วนสำหรับนักพัฒนาจำนวนมาก
ก่อนอื่น bida ไม่ได้มีจุดมุ่งหมายเพื่อแทนที่ langchain แต่แนวคิดการวางตำแหน่งเป้าหมายและการพัฒนาก็แตกต่างกันมากเช่นกัน:
| การจำแนกประเภท | แลงเชน | บิดา |
|---|---|---|
| กลุ่มเป้าหมาย | ฝูงชนพัฒนาเต็มรูปแบบในทิศทางของ AIGC | นักพัฒนาที่มีความจำเป็นเร่งด่วนในการรวม AIGC เข้ากับการพัฒนาแอปพลิเคชัน |
| รองรับโมเดล | รองรับโมเดลต่างๆ สำหรับการปรับใช้ภายในหรือระยะไกล | รองรับเฉพาะการเรียกโมเดลที่มี Web API เท่านั้น ปัจจุบันโมเดลเชิงพาณิชย์ส่วนใหญ่มีให้แล้ว |
| โครงสร้างเฟรม | เนื่องจากมีความสามารถมากมายและมีโครงสร้างที่ซับซ้อนมาก ณ เดือนสิงหาคม 2566 โค้ดหลักจึงมีไฟล์มากกว่า 1,700 ไฟล์และโค้ด 150,000 บรรทัด และมีเกณฑ์การเรียนรู้สูง | มีโค้ดหลักมากกว่า 10 โค้ดและโค้ดประมาณ 2,000 บรรทัด การเรียนรู้และแก้ไขโค้ดค่อนข้างง่าย |
| รองรับฟังก์ชั่น | นำเสนอความครอบคลุมเต็มรูปแบบของโมเดล เทคโนโลยี และสาขาการใช้งานต่างๆ ในทิศทางของ AIGC | ปัจจุบันมีการรองรับ ChatCompletions, Completions, Embeddings, Function Call และฟังก์ชันอื่นๆ เช่น เสียงและรูปภาพ จะเปิดตัวในอนาคตอันใกล้นี้ |
| พรอมต์ | มีการจัดเตรียมเทมเพลตพร้อมท์ไว้ แต่พร้อมท์ที่ใช้โดยฟังก์ชันของตัวเองจะฝังอยู่ในโค้ด ทำให้การดีบักและการแก้ไขทำได้ยาก | มีเทมเพลต Prompt ให้ไว้ ปัจจุบันไม่มีฟังก์ชันในตัวให้ใช้ Prompt หากใช้ในอนาคต โหมดหลังการโหลดตามการกำหนดค่าจะถูกนำมาใช้เพื่ออำนวยความสะดวกในการปรับเปลี่ยนของผู้ใช้ |
| การสนทนาและความทรงจำ | รองรับและจัดเตรียมวิธีการจัดการหน่วยความจำที่หลากหลาย | การสนับสนุน สนับสนุนการคงอยู่ของการสนทนา (บันทึกไปยัง duckdb) หน่วยความจำมีความสามารถในการเก็บถาวรเซสชันที่จำกัด และความสามารถอื่นๆ สามารถขยายได้โดยเฟรมเวิร์กส่วนขยาย |
| ฟังก์ชั่นและปลั๊กอิน | รองรับและให้ความสามารถในการขยายที่หลากหลาย แต่ผลการใช้งานขึ้นอยู่กับความสามารถของตัวเองของรุ่นขนาดใหญ่ | ใช้งานได้กับโมเดลขนาดใหญ่ที่ใช้ข้อกำหนด Function Call ของ OpenAI |
| ตัวแทนและเชน | รองรับและให้ความสามารถในการขยายที่หลากหลาย แต่ผลการใช้งานขึ้นอยู่กับความสามารถของตัวเองของรุ่นขนาดใหญ่ | ไม่ได้รับการสนับสนุน เราวางแผนที่จะเปิดโครงการอื่นเพื่อดำเนินการ หรือเราสามารถขยายและพัฒนาด้วยตนเองตามกรอบปัจจุบัน |
| ฟังก์ชั่นอื่นๆ | รองรับฟังก์ชันอื่นๆ มากมาย เช่น การแยกเอกสาร (การฝังเสร็จสิ้นหลังจากการแยก ใช้ในการปรับใช้ chatpdf และฟังก์ชันอื่นที่คล้ายคลึงกัน) | ขณะนี้ไม่มีฟังก์ชันอื่นใด หากมีการเพิ่ม ฟังก์ชันเหล่านี้จะถูกนำไปใช้โดยการเปิดโปรเจ็กต์ใหม่ที่เข้ากันได้ ในปัจจุบัน สามารถนำไปใช้งานโดยใช้ความสามารถร่วมกันที่ได้รับจากผลิตภัณฑ์อื่น |
| ประสิทธิภาพการดำเนินงาน | นักพัฒนาหลายรายรายงานว่าช้ากว่าการเรียก API โดยตรง และไม่ทราบสาเหตุ | โดยจะสรุปเฉพาะกระบวนการเรียกและรวมอินเทอร์เฟซการโทรเข้าด้วยกัน และประสิทธิภาพก็ไม่แตกต่างจากการเรียก API โดยตรง |
ในฐานะโครงการโอเพ่นซอร์สชั้นนำในอุตสาหกรรม langchain ได้มีส่วนสนับสนุนอย่างมากในการโปรโมตโมเดลขนาดใหญ่และ AGI เรายังนำมันไปใช้ในโครงการด้วย ในเวลาเดียวกัน เรายังดึงเอาโมเดลและแนวคิดมากมายมาใช้ในการพัฒนา บิดะ. แต่ langchain ต้องการเป็นเครื่องมือที่มีขนาดใหญ่และครอบคลุมซึ่งนำไปสู่ข้อบกพร่องมากมายอย่างหลีกเลี่ยงไม่ได้ บทความต่อไปนี้มีความคิดเห็นที่คล้ายกัน: Max Woolf - ภาษาจีน, Hacker News - ภาษาจีน
คำพูดยอดนิยมในวงกลมสรุปได้ดีมาก: langchain เป็นตำราเรียนที่ทุกคนจะได้เรียนรู้ แต่ท้ายที่สุดก็จะทิ้งไป
ติดตั้ง bida ล่าสุดจาก pip หรือ pip3
pip install -U bidaรหัสโครงการโคลนจาก github ไปยังไดเร็กทอรีในเครื่อง:
git clone https://github.com/pfzhou/bida.git
pip install -r requirements.txtแก้ไขไฟล์ภายใต้ไดเรกทอรีรากของโค้ดปัจจุบัน: นามสกุลของ ".env.template" จะกลายเป็นไฟล์ตัวแปรสภาพแวดล้อม ".env" โปรดกำหนดค่า คีย์ของโมเดลที่ใช้ ตามคำแนะนำในไฟล์
โปรดทราบ : ไฟล์นี้ถูกเพิ่มเข้าไปในรายการละเว้น และจะไม่ถูกส่งไปยังเซิร์ฟเวอร์ git
ตัวอย่าง1.สภาพแวดล้อมการเริ่มต้น.ipynb
รหัสสาธิตต่อไปนี้จะใช้รุ่นต่างๆ ที่ bida รองรับ โปรดแก้ไขและแทนที่ค่า **[model_type]** ในรหัสด้วยชื่อบริษัทรุ่นที่เกี่ยวข้องตามรุ่นที่คุณซื้อ คุณสามารถสลับระหว่างรุ่นต่างๆ ได้อย่างรวดเร็ว สำหรับประสบการณ์:
# 更多信息参看bidamodels*.json中的model_type配置
# openai
llm = ChatLLM ( model_type = "openai" )
# baidu
llm = ChatLLM ( model_type = "baidu" )
# baidu third models(llama-2...)
llm = ChatLLM ( model_type = "baidu-third" )
# aliyun
llm = ChatLLM ( model_type = "aliyun" )
# minimax
llm = ChatLLM ( model_type = "minimax" )
# minimax ccp
llm = ChatLLM ( model_type = "minimax-ccp" )
# zhipu ai
llm = ChatLLM ( model_type = "chatglm2" )
# xunfei xinghuo
llm = ChatLLM ( model_type = "xfyun" )
# senstime
llm = ChatLLM ( model_type = "senstime" )
# baichuan ai
llm = ChatLLM ( model_type = "baichuan" )
# tencent ai
llm = ChatLLM ( model_type = "tencent" )โหมดแชท: ChatCompletion ซึ่งเป็นโหมดการโต้ตอบ LLM กระแสหลักในปัจจุบัน bida รองรับการจัดการเซสชัน การคงอยู่ และการจัดการหน่วยความจำ
from bida import ChatLLM
llm = ChatLLM ( model_type = 'baidu' )
result = llm . chat ( "你好呀,请问你是谁?" )
print ( result ) from bida import ChatLLM
# stream调用
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你好呀,请问你是谁?" ) from bida import ChatLLM
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
result = llm . chat ( "我的名字是?" )สำหรับโค้ดโดยละเอียดข้างต้นและตัวอย่างการทำงานเพิ่มเติม โปรดดูที่สมุดบันทึกด้านล่าง:
ตัวอย่าง2.1.โหมดแชท.ipynb
สร้างแชทบอทโดยใช้การไล่ระดับสี
Gradio เป็นเฟรมเวิร์กอินเทอร์เฟซการประมวลผลภาษาธรรมชาติที่ได้รับความนิยมอย่างมาก
bida + grario สามารถสร้างแอปพลิเคชันที่ใช้งานได้โดยใช้โค้ดเพียงไม่กี่บรรทัด
import gradio as gr
from bida import ChatLLM
llm = ChatLLM ( model_type = 'openai' )
def predict ( message , history ):
answer = llm . chat ( message )
return answer
gr . ChatInterface ( predict ). launch ()
สำหรับรายละเอียด โปรดดูที่การสาธิตแชทบอทของ bida+gradio
โหมดเสร็จสิ้น: Completions หรือ TextCompletions ซึ่งเป็นโหมดการโต้ตอบ LLM รุ่นก่อนหน้า รองรับเฉพาะการสนทนารอบเดียวเท่านั้น ไม่บันทึกบันทึกการแชท และการโทรแต่ละครั้งเป็นการสื่อสารใหม่
โปรดทราบ: ในบทความของ OpenAI เมื่อวันที่ 6 กรกฎาคม 2023 โมเดลนี้ระบุไว้อย่างชัดเจนว่าจะยุติการใช้งาน โดยพื้นฐานแล้วโมเดลใหม่จะไม่มีฟังก์ชันที่เกี่ยวข้อง แม้แต่โมเดลที่รองรับก็คาดว่าจะเป็นไปตาม OpenAI และคาดว่าจะค่อยๆ ยุติลงใน อนาคต. .
from bida import TextLLM
llm = TextLLM ( model_type = "openai" )
result = llm . completion ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
print ( result )สำหรับรายละเอียดโค้ดตัวอย่าง โปรดดูที่:
ตัวอย่าง2.2.โหมดสมบูรณ์.ipynb
คำว่า Prompt เป็นฟังก์ชันที่สำคัญที่สุดในโมเดลภาษาขนาดใหญ่ โดยจะล้มล้างโมเดลการพัฒนาเชิงวัตถุแบบดั้งเดิมและแปลงเป็น: Prompt project เฟรมเวิร์กนี้ใช้งานโดยใช้ "Prompt Templete" ซึ่งรองรับฟังก์ชันต่างๆ เช่น แท็กการแทนที่ การตั้งค่าคำพร้อมท์ที่แตกต่างกันสำหรับหลายรุ่น และการแทนที่อัตโนมัติเมื่อโมเดลดำเนินการโต้ตอบ
ปัจจุบัน PromptTemplate_Text มีให้: รองรับการใช้ข้อความสตริงเพื่อสร้างเทมเพลต Prompt, bida ยังรองรับเทมเพลตแบบกำหนดเองที่ยืดหยุ่น และแผนที่จะให้ความสามารถในการโหลดเทมเพลตจาก json และฐานข้อมูลในอนาคต
โปรดดูไฟล์ต่อไปนี้สำหรับโค้ดตัวอย่างโดยละเอียด:
ตัวอย่าง2.3.พร้อมท์พร้อมท์ word.ipynb
คำแนะนำที่สำคัญในคำพร้อมท์
โดยทั่วไป แนะนำให้ใช้คำพร้อมท์ตาม โครงสร้างสามย่อหน้า: การกำหนดบทบาท การชี้แจงภารกิจ และการให้บริบท (ข้อมูลหรือตัวอย่างที่เกี่ยวข้อง) คุณสามารถอ้างอิงถึงวิธีการเขียนได้ในตัวอย่าง
ชุดหลักสูตรของ Andrew Ng https://learn.deeplearning.ai/login ฉบับภาษาจีน การตีความ
ตำราอาหาร openai https://github.com/openai/openai-cookbook
เอกสาร Microsoft Azure: ความรู้เบื้องต้นเกี่ยวกับวิศวกรรมเคล็ดลับ เทคโนโลยีวิศวกรรมเคล็ดลับ
คู่มือวิศวกรรมพร้อมท์ที่ได้รับความนิยมมากที่สุดบน Github เวอร์ชันภาษาจีน
การเรียกใช้ฟังก์ชัน เป็นฟังก์ชันที่ OpenAI เปิดตัวในวันที่ 13 มิถุนายน 2023 เราทุกคนทราบดีว่าข้อมูลที่ฝึกโดย ChatGPT นั้นอิงจากก่อนปี 2021 หากคุณถามคำถามที่เกี่ยวข้องกับเรียลไทม์ เราจะไม่สามารถตอบคุณได้ และฟังก์ชัน การโทรช่วยให้เรียลไทม์ สามารถรับข้อมูลเครือข่ายได้ เช่น เช็คพยากรณ์อากาศ เช็คหุ้น แนะนำหนังล่าสุด เป็นต้น
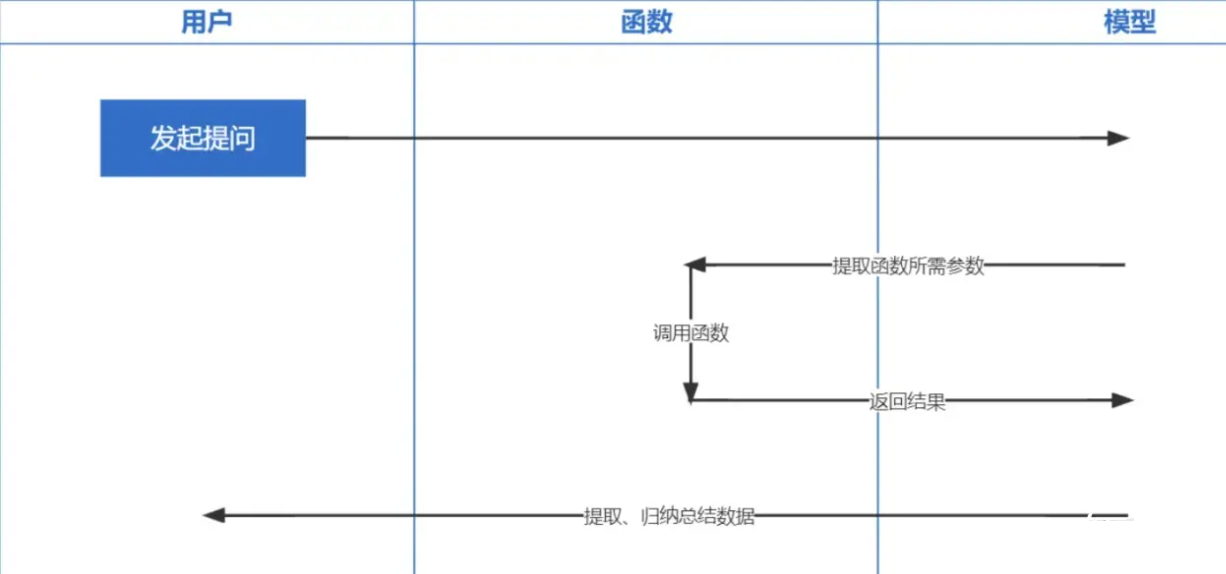
เทคโนโลยีการฝังเป็นเทคโนโลยีที่สำคัญที่สุดในการใช้ Prompt inContext Learning เมื่อเปรียบเทียบกับการดึงคำสำคัญก่อนหน้านี้ ถือเป็นอีกก้าวหนึ่ง
หมายเหตุ : ข้อมูลที่ฝังจากโมเดลที่แตกต่างกันไม่เป็นสากล ดังนั้น จึงต้องใช้โมเดลเดียวกันสำหรับการฝังคำถามระหว่างการดึงข้อมูล
| ชื่อรุ่น | ขนาดเอาต์พุต | จำนวนบันทึกแบทช์ | ขีดจำกัดโทเค็นข้อความเดียว |
|---|---|---|---|
| OpenAI | 1536 | ไม่มีขีดจำกัด | 8191 |
| ไป่ตู้ | 384 | 16 | 384 |
| อาลี | 1536 | 10 | 2048 |
| มินิแม็กซ์ | 1536 | ไม่มีขีดจำกัด | 4096 |
| AI สเปกตรัมแห่งปัญญา | 1,024 | เดี่ยว | 512 |
| ไอฟลายเทค สปาร์ค | 1,024 | เดี่ยว | 256 |
หมายเหตุ: อินเทอร์เฟซการฝังของ bida รองรับการประมวลผลแบบกลุ่ม หากเกินขีดจำกัดการประมวลผลแบบกลุ่ม โมเดลจะได้รับการประมวลผลเป็นชุดโดยอัตโนมัติและส่งคืนพร้อมกัน หากเนื้อหาของข้อความชิ้นเดียวเกินจำนวนโทเค็นที่จำกัด ขึ้นอยู่กับตรรกะของโมเดล บางส่วนจะรายงานข้อผิดพลาดและบางส่วนจะตัดทอน
สำหรับตัวอย่างโดยละเอียด โปรดดู: example2.6.Embeddingsembeddingmodel.ipynb
├─bida # bida框架主目录
│ ├─core # bida框架核心代码
│ ├─functions # 自定义function文件
│ ├─ *.json # function定义
│ ├─ *.py # 对应的调用代码
│ ├─models # 接入模型文件
│ ├─ *.json # 模型配置定义:openai.json、baidu.json等
│ ├─ *_api.py # 模型接入代码:openai_api.py、baidu_api.py等
│ ├─ *_sdk.py # 模型sdk代码:baidu_sdk.py等
│ ├─prompts # 自定义prompt模板文件
│ ├─*.py # 框架其他代码文件
├─docs # 帮助文档
├─examples # 演示代码、notebook文件和相关数据文件
├─test # pytest测试代码
│ .env.template # .env的模板
│ LICENSE # MIT 授权文件
│ pytest.ini # pytest配置文件
│ README.md # 本说明文件
│ requirements.txt # 相关依赖包
เราหวังว่าจะปรับตัวเข้ากับโมเดลต่างๆ ได้มากขึ้น และยินดีรับความคิดเห็นอันมีค่าของคุณเพื่อมอบผลิตภัณฑ์ที่ดีกว่าให้กับนักพัฒนาร่วมกัน!


