ComfyUI N Nodes
1.0.0
ชุดโหนดที่กำหนดเองสำหรับ ComfyUI ที่ประกอบด้วยโหนดตัวแปรจำนวนเต็ม สตริงและโฟลต โหนด GPT และโหนดวิดีโอ
สำคัญ
โหนดเหล่านี้ได้รับการทดสอบเป็นหลักใน Windows ในสภาพแวดล้อมเริ่มต้นที่ ComfyUI มอบให้ และในสภาพแวดล้อมที่สร้างโดยโน้ตบุ๊กสำหรับพื้นที่กระดาษโดยเฉพาะกับ cyberes/gradient-base-py3.10:latest docker image สภาพแวดล้อมอื่นๆ ยังไม่ได้รับการทดสอบ
โคลนพื้นที่เก็บข้อมูล: git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
ไปยังไดเร็กทอรี ComfyUI custom_nodes ของคุณ
สำคัญ: หากคุณต้องการให้โหนด GPT บน GPU คุณจะต้องเรียกใช้ ไฟล์ค้างคาว install_dependency มี 2 เวอร์ชัน: install_dependency_ggml_models.bat สำหรับโมเดล ggmlv3 เก่า และ install_dependency_gguf_models.bat สำหรับโมเดลใหม่ทั้งหมด (GGUF) คุณสามารถใช้ได้ครั้งละหนึ่งรายการเท่านั้น! เนื่องจากจำเป็นต้องคอมไพล์ llama-cpp-python จากซอร์สโค้ดเพื่อให้สามารถใช้งาน GPU ได้ ก่อนอื่นคุณจะต้องติดตั้ง CUDA และ Visual Studio 2019 หรือ 2022 (ในกรณีของค้างคาว) เพื่อคอมไพล์ สำหรับรายละเอียดและคำแนะนำฉบับเต็มคุณสามารถไปได้ที่นี่
หากคุณตั้งใจจะใช้ GPTLoaderSimple กับโมเดล Moondream คุณจะต้องรันสคริปต์ 'install_extra.bat' ซึ่งจะติดตั้ง Transformers เวอร์ชัน 4.36.2
รีบูต ComfyUI
ในกรณีที่คุณต้องการคืนค่าการเปลี่ยนแปลงเหล่านี้ (เนื่องจากไม่เข้ากันกับโหนดอื่น) คุณสามารถใช้สคริปต์ 'remove_extra.bat'
ComfyUI จะโหลดสคริปต์และโหนดที่กำหนดเองทั้งหมดโดยอัตโนมัติเมื่อเริ่มต้น
บันทึก
สคริปต์จะติดตั้ง llama-cpp-python โดยอัตโนมัติ หากคุณมี NVIDIA GPU ไม่จำเป็นต้องสร้าง CUDA อีกต่อไป ต้องขอบคุณ jllllll repo ฉันยังได้ยกเลิกการรองรับรุ่น GGMLv3 เนื่องจากรุ่นที่โดดเด่นทั้งหมดควรเปลี่ยนไปใช้ GGUF เวอร์ชันล่าสุดแล้ว
บันทึก
ตั้งแต่วันที่ 14/02/2024 โหนดได้รับการเขียนใหม่ครั้งใหญ่ ซึ่งนำไปสู่การเปลี่ยนชื่อโหนดทั้งหมดเพื่อหลีกเลี่ยงข้อขัดแย้งกับส่วนขยายอื่นๆ ในอนาคต (หรืออย่างน้อยฉันก็หวังเช่นนั้น) ด้วยเหตุนี้ เวิร์กโฟลว์เก่าจึงเข้ากันไม่ได้อีกต่อไป และจำเป็นต้องเปลี่ยนแต่ละโหนดด้วยตนเอง เพื่อหลีกเลี่ยงปัญหานี้ ฉันได้สร้างเครื่องมือที่ช่วยให้สามารถเปลี่ยนอัตโนมัติได้ บน Windows เพียงลากเวิร์กโฟลว์ *.json ใดๆ ลงบนไฟล์ movege.bat ที่อยู่ใน (custom_nodes/ComfyUI-N-Nodes) จากนั้นเวิร์กโฟลว์อื่นที่มีคำต่อท้าย _migrated จะถูกสร้างขึ้นในโฟลเดอร์เดียวกันกับเวิร์กโฟลว์ปัจจุบัน บน Linux คุณสามารถใช้สคริปต์ในลักษณะต่อไปนี้: python libs/migrate.py path/to/Original/workflow/ ด้วยเหตุผลด้านความปลอดภัย เวิร์กโฟลว์ดั้งเดิมจะไม่ถูกลบ" สำหรับการติดตั้งเวอร์ชันล่าสุดของที่เก็บนี้ก่อนที่การเปลี่ยนแปลงนี้จาก Comfyui-N-Suite จะรัน git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083
ComfyUI-N-Nodes ใน custom_nodescomfyui-n-nodes ใน ComfyUIwebextensionsn-styles.csv และ n-styles.csv.backup ใน ComfyUIstylesGPTcheckpoints ใน ComfyUImodelscustom_nodes/ComfyUI-N-Nodesgit pull
โหนด LoadVideoAdvanced อนุญาตให้โหลดไฟล์วิดีโอและแยกเฟรมออกมาได้ ชื่อถูกเปลี่ยนจาก LoadVideo เป็น LoadVideoAdvanced เพื่อหลีกเลี่ยงความขัดแย้งกับโหนด LoadVideo Animatediff
video : เลือกไฟล์วิดีโอที่จะโหลดframerate : เลือกว่าจะคงอัตราเฟรมเดิมหรือลดความเร็วลงเหลือครึ่งหรือสี่ส่วนresize_by : เลือกวิธีปรับขนาดเฟรม - 'ไม่มี', 'ความสูง' หรือ 'ความกว้าง'size : ขนาดเป้าหมายหากปรับขนาดตามความสูงหรือความกว้างimages_limit : จำกัดจำนวนเฟรมที่จะแยกbatch_size : ขนาดแบทช์สำหรับการเข้ารหัสเฟรมstarting_frame : เลือกเฟรมที่จะเริ่มต้นautoplay : เลือกว่าจะเล่นวิดีโออัตโนมัติหรือไม่use_ram : ใช้ RAM แทนดิสก์เพื่อขยายขนาดเฟรมวิดีโอ IMAGES : ภาพเฟรมที่แยกออกมาเป็น PyTorch tensorsLATENT : เวกเตอร์แฝงที่ว่างเปล่าMETADATA : ข้อมูลเมตาของวิดีโอ - FPS และจำนวนเฟรมWIDTH: ความกว้างของเฟรมHEIGHT : ความสูงของเฟรมMETA_FPS : อัตราเฟรมMETA_N_FRAMES : จำนวนเฟรมโหนดแยกเฟรมจากวิดีโออินพุตที่อัตราเฟรมที่ระบุ มันจะปรับขนาดเฟรมหากเลือก และส่งคืนเป็นชุดของเทนเซอร์รูปภาพ PyTorch พร้อมด้วยเวกเตอร์แฝง ข้อมูลเมตา และขนาดเฟรม
โหนด SaveVideo จะใช้เฟรมที่แยกออกมาและบันทึกกลับเป็นไฟล์วิดีโอ 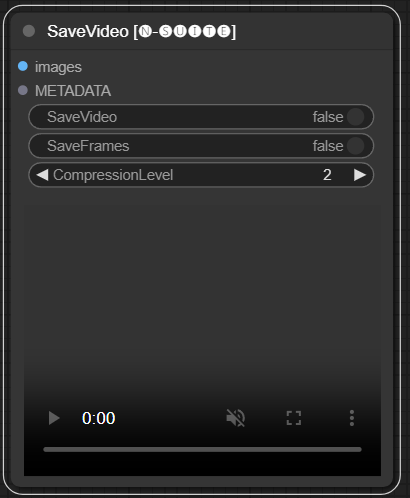
images : ใส่กรอบรูปภาพเป็นเทนเซอร์METADATA : ข้อมูลเมตาจากโหนด LoadVideoSaveVideo : สลับการบันทึกไฟล์วิดีโอเอาต์พุตSaveFrames : สลับการบันทึกเฟรมไปยังโฟลเดอร์CompressionLevel : ระดับการบีบอัด PNG สำหรับการบันทึกเฟรม บันทึกไฟล์วิดีโอเอาต์พุตและ/หรือเฟรมที่แยกออกมา
โหนดใช้เฟรมและข้อมูลเมตาที่แยกออกมา และสามารถบันทึกเป็นไฟล์วิดีโอใหม่และ/หรือรูปภาพแต่ละเฟรมได้ สามารถกำหนดค่าการบีบอัดวิดีโอและการบีบอัดเฟรม PNG ได้ หมายเหตุ: หากคุณใช้ LoadVideo เป็นแหล่งที่มาของเฟรม เสียงของไฟล์ต้นฉบับจะยังคงอยู่ แต่เฉพาะในกรณีที่ images_limit และ beginning_frame มีค่าเท่ากับศูนย์
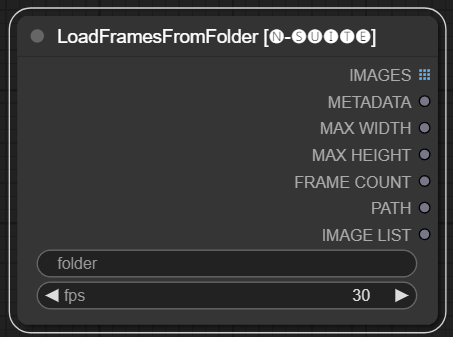
โหนด LoadFramesFromFolder อนุญาตให้โหลดเฟรมรูปภาพจากโฟลเดอร์และส่งคืนเป็นชุด
folder : พาธไปยังโฟลเดอร์ที่มีเฟรมรูปภาพ ต้องเป็นรูปแบบ PNG ตั้งชื่อด้วยตัวเลข (เช่น 1.png หรือ 0001.png) รูปภาพจะถูกโหลดตามลำดับfps : เฟรมต่อวินาทีเพื่อกำหนดให้กับเฟรมที่โหลด IMAGES : ชุดของภาพเฟรมที่โหลดเป็น PyTorch tensorsMETADATA : ข้อมูลเมตาที่มีค่า FPS ที่ตั้งไว้MAX_WIDTH : ความกว้างเฟรมสูงสุดMAX_HEIGHT : ความสูงสูงสุดของเฟรมFRAME COUNT : จำนวนเฟรมในโฟลเดอร์PATH : เส้นทางไปยังโฟลเดอร์ที่มีภาพเฟรมIMAGE LIST : รายการรูปภาพเฟรมในโฟลเดอร์ (ไม่ใช่รายการจริงเพียงสตริงหารด้วย n)โหนดโหลดไฟล์รูปภาพทั้งหมดจากโฟลเดอร์ที่ระบุ แปลงเป็น PyTorch tensors และส่งคืนเป็นเทนเซอร์แบบแบตช์พร้อมกับข้อมูลเมตาอย่างง่ายที่มีค่า FPS ที่ตั้งไว้
ซึ่งช่วยให้โหลดชุดเฟรมที่แยกและบันทึกไว้ก่อนหน้านี้ได้อย่างง่ายดาย เช่น โหลดซ้ำและประมวลผลอีกครั้ง ด้วยการตั้งค่า FPS เฟรมจึงสามารถตีความได้อย่างเหมาะสมว่าเป็นลำดับวิดีโอ
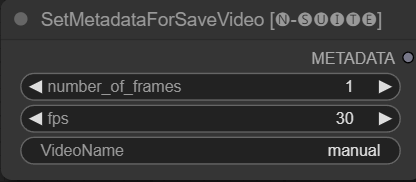
โหนด SetMetadataForSaveVideo อนุญาตให้ตั้งค่าข้อมูลเมตาสำหรับโหนด SaveVideo
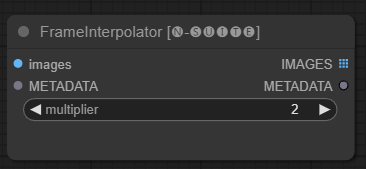
โหนด FrameInterpolator ช่วยให้สามารถแทรกระหว่างเฟรมวิดีโอที่แยกออกมาเพื่อเพิ่มอัตราเฟรมและการเคลื่อนไหวที่ราบรื่น
images : ภาพเฟรมที่แยกออกมาเป็นเทนเซอร์METADATA : ข้อมูลเมตาจากวิดีโอ - FPS และจำนวนเฟรมmultiplier : ปัจจัยในการเพิ่มอัตราเฟรม IMAGES : เฟรมที่สอดแทรกเป็นเทนเซอร์รูปภาพMETADATA : อัปเดตข้อมูลเมตาด้วยอัตราเฟรมใหม่โหนดใช้เฟรมและข้อมูลเมตาที่แยกออกมาเป็นอินพุต ใช้โมเดลการแก้ไข (RIFE) เพื่อสร้างเฟรมเพิ่มเติมที่อยู่ระหว่างเฟรมด้วยอัตราเฟรมที่สูงขึ้น
อัตราเฟรมเดิมในข้อมูลเมตาจะคูณด้วยค่า multiplier เพื่อให้ได้อัตราเฟรมที่สอดแทรกใหม่
เฟรมที่สอดแทรกจะถูกส่งกลับเป็นชุดของเทนเซอร์รูปภาพ พร้อมด้วยข้อมูลเมตาที่อัปเดตซึ่งมีอัตราเฟรมใหม่
ซึ่งช่วยเพิ่มอัตราเฟรมของวิดีโอที่มีอยู่เพื่อให้การเคลื่อนไหวราบรื่นขึ้นและการเล่นช้าลง โมเดลการประมาณค่าจะสร้างเฟรมที่เหมือนจริงขึ้นมาใหม่เพื่อเติมเต็มช่องว่าง แทนที่จะแค่ทำซ้ำเฟรมที่มีอยู่
รหัสต้นฉบับถูกนำมาจาก ที่นี่
เนื่องจากโหนดดั้งเดิมมีข้อจำกัดในลิงก์ (เช่น ในขณะที่ฉันกำลังเขียน คุณไม่สามารถลิงก์ "start_at_step" และ "ขั้นตอน" ของ ksampler อื่นเข้าด้วยกันได้) ฉันจึงตัดสินใจสร้างตัวแปรโหนดแบบง่ายเหล่านี้เพื่อหลีกเลี่ยงข้อจำกัดนี้ โหนด- ตัวแปรคือ:
โหนดที่กำหนดเองเหล่านี้ได้รับการออกแบบมาเพื่อเพิ่มขีดความสามารถของกรอบงาน ConfyUI โดยเปิดใช้งานการสร้างข้อความโดยใช้โมเดล GGUF GPT README นี้ให้ภาพรวมของโหนดแบบกำหนดเองสองโหนดและการใช้งานภายใน ConfyUI
คุณสามารถเพิ่ม extra_model_paths.yaml เส้นทางที่โมเดล GGUF ของคุณอยู่ในลักษณะนี้ (ตัวอย่าง):
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
มิฉะนั้นจะสร้างโฟลเดอร์ GPTcheckpoints ในโฟลเดอร์ model ของ ComfyUI ซึ่งคุณสามารถวางโมเดล .gguf ของคุณได้
มีการสร้างสองโฟลเดอร์ภายในไดเรกทอรี 'Llava' ในโฟลเดอร์ 'GPTcheckpoints' สำหรับรุ่น LLava:
clips : โฟลเดอร์นี้ถูกกำหนดไว้สำหรับจัดเก็บคลิปสำหรับโมเดล LLava ของคุณ (โดยปกติจะเป็นไฟล์ที่ขึ้นต้นด้วย mm ในพื้นที่เก็บข้อมูล) models : โฟลเดอร์นี้ถูกกำหนดไว้สำหรับจัดเก็บโมเดล LLava
โหนดนี้รองรับ 4 รุ่นที่แตกต่างกัน:
สามารถดาวน์โหลดโมเดล GGUF ได้จาก Huggingface Hub
นี่คือวิดีโอตัวอย่างวิธีใช้โมเดล GGUF โดย boricuapab
นี่คือรายการโมเดลเล็กๆ น้อยๆ ที่โหนดนี้รองรับ:
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 วิสัยทัศน์
####ตัวอย่างโมเดล Llava: 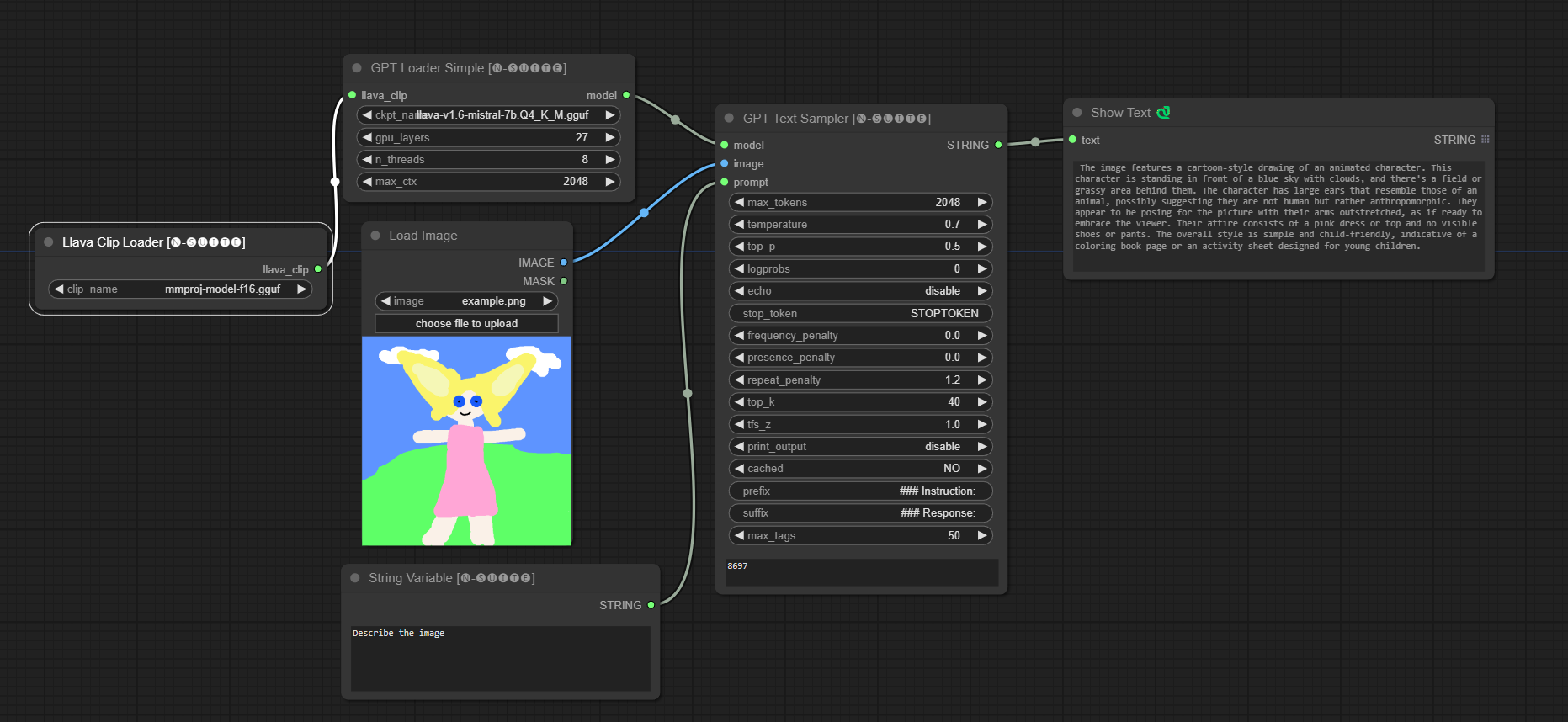
โมเดลจะถูกดาวน์โหลดโดยอัตโนมัติเมื่อคุณเรียกใช้ครั้งแรก อย่างไรก็ตาม มีให้ที่นี่ รหัสที่นำมาจากพื้นที่เก็บข้อมูลนี้
####ตัวอย่างกับรุ่น Moondream: 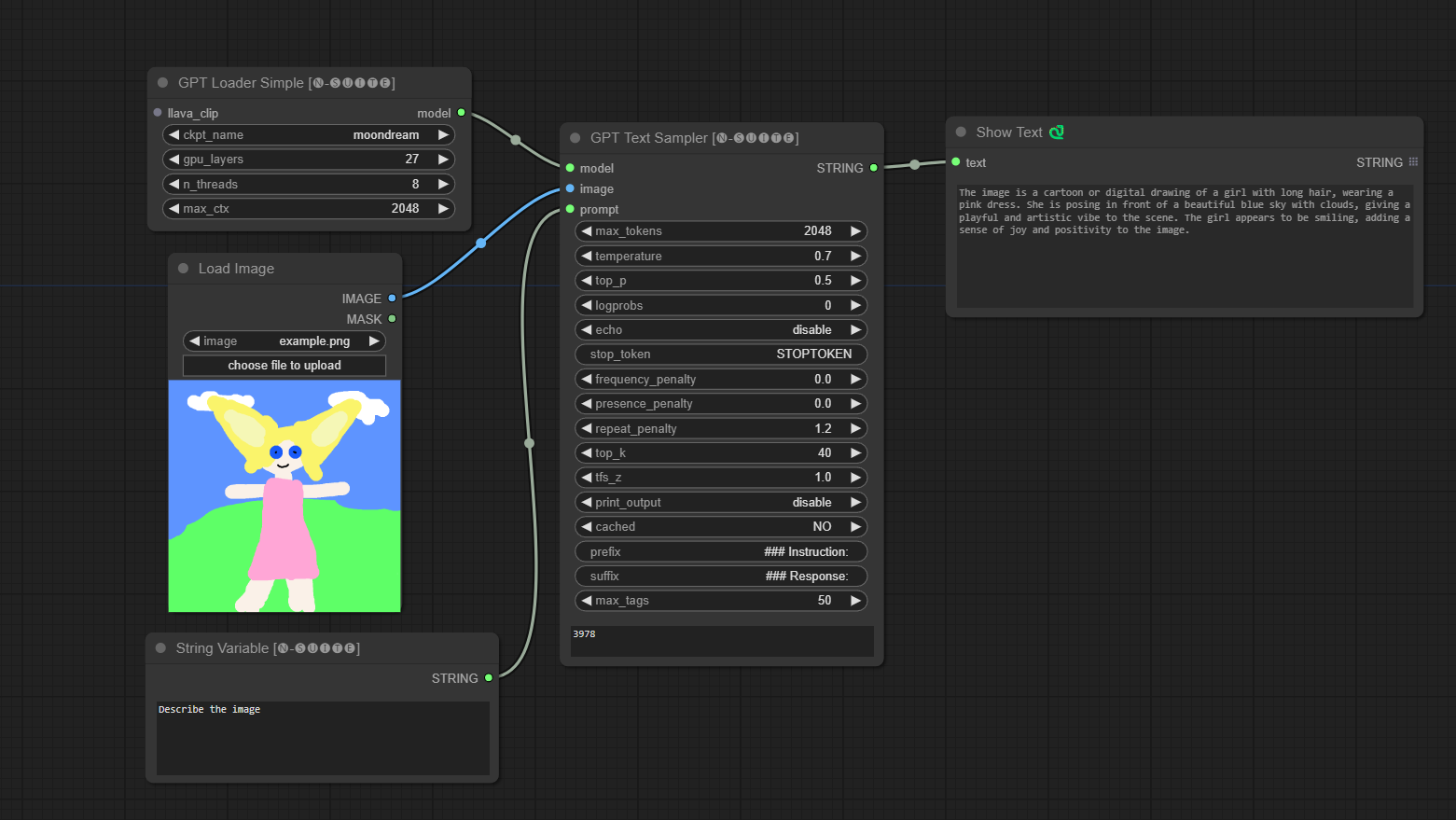
โมเดลจะถูกดาวน์โหลดโดยอัตโนมัติเมื่อคุณเรียกใช้ครั้งแรก อย่างไรก็ตาม มีให้ที่นี่ รหัสที่นำมาจากพื้นที่เก็บข้อมูลนี้
####ตัวอย่างกับรุ่น Joytag: 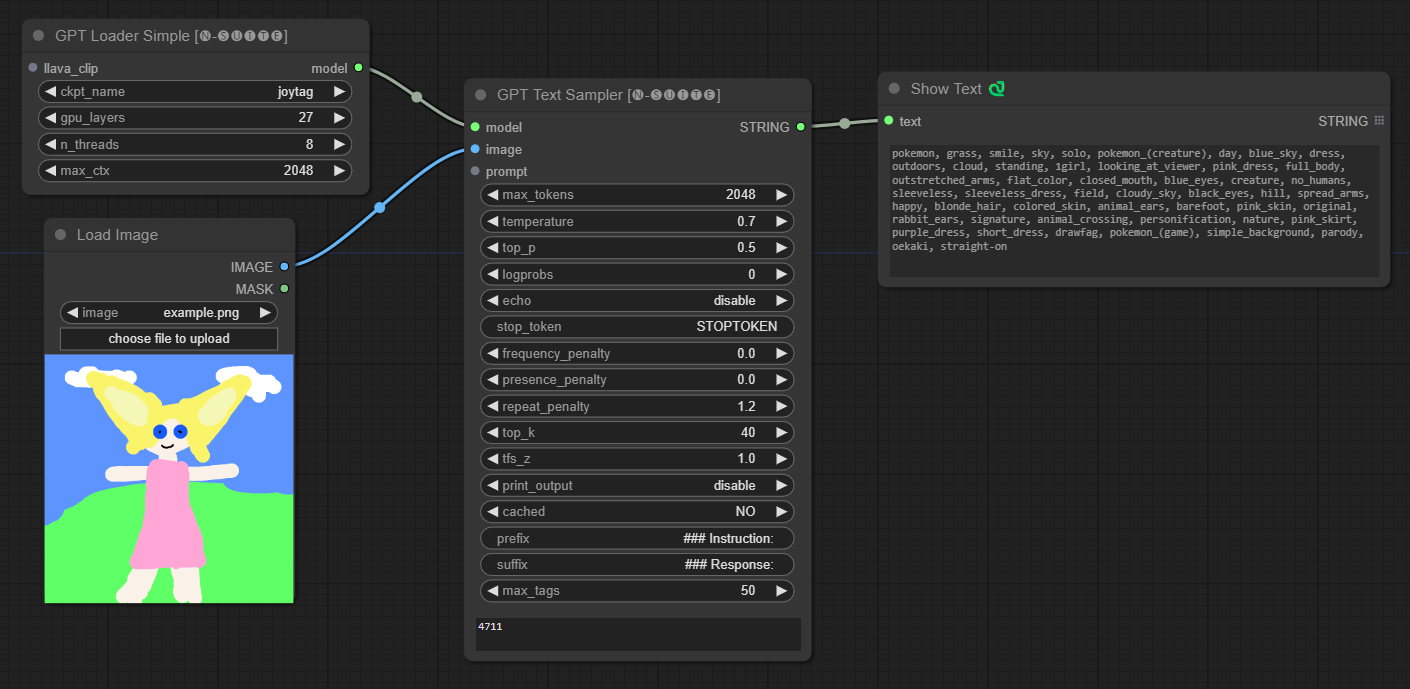
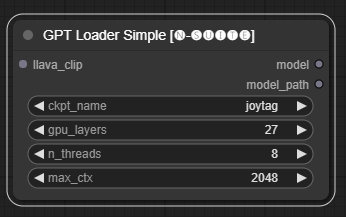
โหนด GPTLoaderSimple มีหน้าที่โหลดจุดตรวจสอบโมเดล GPT และสร้างอินสแตนซ์ของไลบรารี Llama สำหรับการสร้างข้อความ มีอินเทอร์เฟซสำหรับกำหนดค่าเลเยอร์ GPU จำนวนเธรด และบริบทสูงสุดสำหรับการสร้างข้อความ
ckpt_name : เลือกชื่อจุดตรวจ GPT จากตัวเลือกที่มีอยู่ (joytag และ moondream จะถูกดาวน์โหลดอัตโนมัติในครั้งแรก)gpu_layers : ระบุจำนวนเลเยอร์ GPU ที่จะใช้ (ค่าเริ่มต้น: 27)n_threads : ระบุจำนวนเธรดสำหรับการสร้างข้อความ (ค่าเริ่มต้น: 8)max_ctx : ระบุความยาวบริบทสูงสุดสำหรับการสร้างข้อความ (ค่าเริ่มต้น: 2048) โหนดส่งคืนอินสแตนซ์ของไลบรารี Llama (MODEL) และเส้นทางไปยังจุดตรวจสอบที่โหลด (STRING)
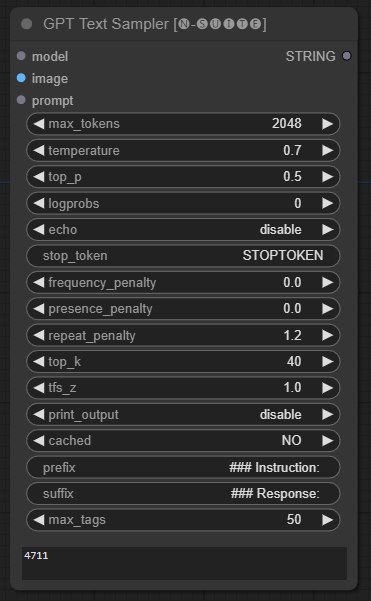
โหนด GPTSampler อำนวยความสะดวกในการสร้างข้อความโดยใช้โมเดล GPT โดยอิงตามพร้อมท์อินพุตและพารามิเตอร์การสร้างต่างๆ ช่วยให้คุณสามารถควบคุมแง่มุมต่างๆ เช่น อุณหภูมิ การสุ่มตัวอย่างด้านบน บทลงโทษ และอื่นๆ อีกมากมาย
prompt : ป้อนพร้อมท์อินพุตสำหรับการสร้างข้อความimage : อินพุตรูปภาพสำหรับรุ่น Joytag, moondream และ llavamodel : เลือกโมเดล GPT เพื่อใช้ในการสร้างข้อความmax_tokens : ตั้งค่าจำนวนโทเค็นสูงสุดในข้อความที่สร้างขึ้น (ค่าเริ่มต้น: 128)temperature : ตั้งค่าพารามิเตอร์อุณหภูมิสำหรับการสุ่ม (ค่าเริ่มต้น: 0.7)top_p : ตั้งค่าความน่าจะเป็น top-p สำหรับการสุ่มตัวอย่างนิวเคลียส (ค่าเริ่มต้น: 0.5)logprobs : ระบุจำนวนความน่าจะเป็นของบันทึกที่จะส่งออก (ค่าเริ่มต้น: 0)echo : เปิดหรือปิดการพิมพ์พรอมต์อินพุตข้างข้อความที่สร้างขึ้นstop_token : ระบุโทเค็นที่การสร้างข้อความหยุดfrequency_penalty , presence_penalty , repeat_penalty : ควบคุมบทลงโทษในการสร้างคำtop_k : ตั้งค่าโทเค็น top-k ที่ต้องพิจารณาระหว่างการสร้าง (ค่าเริ่มต้น: 40)tfs_z : ตั้งค่าปัจจัยการปรับขนาดอุณหภูมิสำหรับตัวอย่างที่พบบ่อยที่สุด (ค่าเริ่มต้น: 1.0)print_output : เปิดหรือปิดการพิมพ์ข้อความที่สร้างขึ้นไปยังคอนโซลcached : เลือกว่าจะใช้การสร้างแคชหรือไม่ (ค่าเริ่มต้น: NO)prefix , suffix : ระบุข้อความที่จะเติมหน้าและต่อท้ายพรอมต์max_tags : สิ่งนี้มีผลกับจำนวนแท็กสูงสุดที่สร้างโดย joydag เท่านั้น โหนดส่งคืนข้อความที่สร้างขึ้นพร้อมกับการแสดงที่เป็นมิตรกับ UI
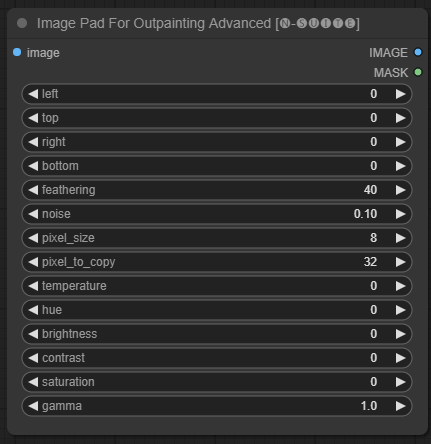
โหนด ImagePadForOutpaintingAdvanced เป็นทางเลือกแทนโหนด ImagePadForOutpainting ที่ใช้เทคนิคที่เห็นในวิดีโอนี้ภายใต้มาสก์การทาสีภายนอก ส่วนการแก้ไขสีถูกนำมาจากโหนดแบบกำหนดเองนี้จาก Sipherxyz
image : อินพุตรูปภาพleft : พิกเซลที่จะขยายจากซ้ายtop : พิกเซลที่จะขยายจากด้านบนright : พิกเซลที่จะขยายจากขวาbottom : พิกเซลที่จะขยายจากด้านล่างfeathering : ความแข็งแรงของขนนกnoise : ผสมผสานความแข็งแกร่งจากเสียงรบกวนและเส้นขอบที่คัดลอกมาpixel_size : พิกเซลในเอฟเฟกต์แบบพิกเซลจะใหญ่แค่ไหนpixel_to_copy : จำนวนพิกเซลที่จะคัดลอก (จากแต่ละด้าน)temperature : การตั้งค่าการแก้ไขสีที่ใช้กับส่วนมาส์กเท่านั้นhue : การตั้งค่าการแก้ไขสีที่ใช้กับส่วนมาส์กเท่านั้นbrightness : การตั้งค่าการแก้ไขสีที่ใช้กับส่วนมาส์กเท่านั้นcontrast : การตั้งค่าการแก้ไขสีที่ใช้กับส่วนมาส์กเท่านั้นsaturation : การตั้งค่าการแก้ไขสีที่ใช้เฉพาะกับส่วนมาส์กเท่านั้นgamma : การตั้งค่าการแก้ไขสีที่ใช้กับส่วนมาส์กเท่านั้น โหนดส่งคืนรูปภาพที่ประมวลผลและมาสก์

โหนด DynamicPrompt สร้างพรอมต์โดยการรวมพรอมต์คงที่เข้ากับการเลือกแท็กแบบสุ่มจากพรอมต์ตัวแปร ช่วยให้สามารถสร้างพร้อมท์ได้อย่างยืดหยุ่นและไดนามิกสำหรับกรณีการใช้งานต่างๆ
variable_prompt : ป้อนพรอมต์ตัวแปรสำหรับการเลือกแท็กcached : เลือกว่าจะแคชพรอมต์ที่สร้างขึ้นหรือไม่ (ค่าเริ่มต้น: NO)number_of_random_tag : เลือกระหว่าง "คงที่" และ "สุ่ม" สำหรับจำนวนแท็กสุ่มที่จะรวมfixed_number_of_random_tag : ถ้า number_of_random_tag ถ้า "Fixed" ระบุจำนวนแท็กสุ่มที่จะรวม (ค่าเริ่มต้น: 1)fixed_prompt (ไม่บังคับ): ป้อนพรอมต์คงที่สำหรับการสร้างพรอมต์สุดท้าย โหนดส่งคืนพรอมต์ที่สร้างขึ้น ซึ่งเป็นการรวมกันของพรอมต์คงที่และแท็กสุ่มที่เลือก
variable_prompt โดยคั่นด้วยเครื่องหมายจุลภาค คุณจะระบุ fixed_prompt หรือไม่ก็ได้ 
โหนด CLIP Text Encode Advanced เป็นทางเลือกแทนโหนด CLIP Text Encode มาตรฐาน ให้การสนับสนุนรูปแบบเพิ่ม/แทนที่/ลบ เพื่อให้สามารถรวมพรอมต์ทั้งเชิงบวกและเชิงลบภายในโหนดเดียว
ไฟล์สไตล์พื้นฐานเรียกว่า n-styles.csv และอยู่ในโฟลเดอร์ ComfyUIstyles ไฟล์สไตล์เป็นไปตามรูปแบบเดียวกับไฟล์ styles.csv ปัจจุบันที่ใช้ใน A1111 (ในขณะที่เขียน)
หมายเหตุ: หมายเหตุนี้เป็นการทดลองและยังมีข้อบกพร่องอยู่มาก
clip : อินพุตคลิปstyle : มันจะเติมข้อความแจ้งเชิงบวกและเชิงลบโดยอัตโนมัติตามสไตล์ที่เลือก positive : เงื่อนไขเชิงบวกnegative : เงื่อนไขเชิงลบ รู้สึกอิสระที่จะมีส่วนร่วมในโครงการนี้โดยการรายงานปัญหาหรือเสนอแนะการปรับปรุง เปิดปัญหาหรือส่งคำขอดึงบนพื้นที่เก็บข้อมูล GitHub
โครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT ดูไฟล์ใบอนุญาตสำหรับรายละเอียด


