ssebowa
1.0.0
Ssebowa เป็นไลบรารี Python แบบโอเพ่นซอร์สที่ให้โมเดล AI เชิงสร้างสรรค์ ได้แก่:
ssebowa-llm: โมเดลภาษาขนาดใหญ่ (LLM) สำหรับการสร้างข้อความssebowa-vllm: โมเดลภาษาภาพ (VLLM) เพื่อการทำความเข้าใจด้วยภาพssebowa-imagen: การสร้างภาพและโมเดลการปรับแต่งแบบละเอียดที่ปรับแต่งเองSsebowa-vigen: โมเดลการสร้างวิดีโอด้วย Ssebowa คุณสามารถสร้างข้อความ แปลภาษา เขียนเนื้อหาสร้างสรรค์ประเภทต่างๆ การสร้างภาพในแบบของคุณ และตอบคำถามของคุณในลักษณะที่ให้ข้อมูลได้อย่างง่ายดาย
สำหรับข้อมูลการใช้งานโดยละเอียดเพิ่มเติม โปรดดูที่: เอกสารทางเทคนิคของ Ssebowa
ก่อนที่จะรันสคริปต์ ตรวจสอบให้แน่ใจว่าได้ติดตั้งไลบรารีที่จำเป็นแล้ว คุณสามารถทำได้โดยดำเนินการคำสั่งต่อไปนี้:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .จากนั้นติดตั้ง Ssebova
pip install ssebowaหากคุณกำลังเรียกใช้คำสั่งนี้ในสมุดบันทึก colab หรือ jupyter โปรดใช้สิ่งนี้
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaตอนนี้คุณสามารถเข้าถึงโมเดลต่างๆ ได้โดยการนำเข้าจากไลบรารี:
Ssebowa-Imagen เป็นแบบจำลองการสังเคราะห์ภาพแบบโอเพ่นซอร์สที่ใช้การผสมผสานระหว่าง diffusion modeling และ generative adversarial networks (GANs) เพื่อสร้างภาพคุณภาพสูงจาก text descriptions และยังช่วยให้เปลี่ยนภาพถ่ายสองสามภาพของคุณให้เป็น custom model ที่สามารถสร้างได้ ภาพที่น่าทึ่งของ chosen subject โดยใช้ประโยชน์จาก 100 billion dataset ชุด ช่วยให้สามารถจับภาพความแตกต่างของภาพในโลกแห่งความเป็นจริงได้อย่างแม่นยำ และแปลคำอธิบายข้อความให้เป็นการแสดงภาพที่น่าสนใจได้อย่างมีประสิทธิภาพ
10-20 high-quality (jpg or png) เช่น ภาพของคุณ เพื่อน ผลิตภัณฑ์ หรือสัตว์เลี้ยง ฯลฯ แล้วใส่ไว้ในไดเร็กทอรีเฉพาะ16GB or more (หากคุณปรับแต่ง SDXL อย่างละเอียด คุณจะต้องมี VRAM ขนาด 24GB) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()ไลค์ให้สร้าง "แมวนั่งอยู่บนชั้นหนังสือ"
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm คือ Visual Large Language Model (VLLM) แบบโอเพ่นซอร์สที่พัฒนาโดย Ssebowa AI เป็นเครื่องมืออันทรงพลังที่สามารถใช้เพื่อทำความเข้าใจภาพ Ssebowa-vllm มีพารามิเตอร์ภาพ 11 พันล้านพารามิเตอร์และพารามิเตอร์ภาษา 7 พันล้านรายการ รองรับการทำความเข้าใจรูปภาพที่ความละเอียด 1120*1120
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)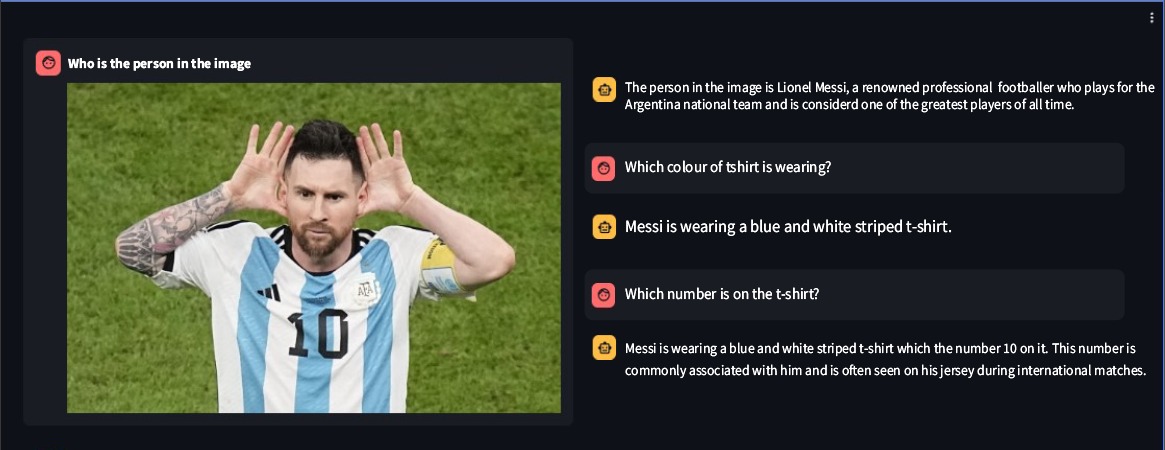
Ssebowa เปิดรับการสนับสนุน! อยู่ระหว่างดำเนินการแนวทาง..
Ssebowa เปิดตัวภายใต้ Apache License 2.0
หากคุณมีคำถามหรือข้อเสนอแนะ โปรดอย่าลังเลที่จะเปิดปัญหาบน GitHub หรือติดต่อเราที่ [email protected]


