xTuring
0.1.8


xTuring ให้การปรับแต่ง LLM แบบโอเพ่นซอร์สที่รวดเร็ว มีประสิทธิภาพ และง่ายดาย เช่น Mistral, LLaMA, GPT-J และอื่นๆ ด้วยการจัดเตรียมอินเทอร์เฟซที่ใช้งานง่ายสำหรับการปรับแต่ง LLM ให้กับข้อมูลและแอปพลิเคชันของคุณเอง xTuring ทำให้การสร้าง ปรับเปลี่ยน และควบคุม LLM เป็นเรื่องง่าย กระบวนการทั้งหมดสามารถทำได้ภายในคอมพิวเตอร์ของคุณหรือในระบบคลาวด์ส่วนตัวของคุณ เพื่อให้มั่นใจถึงความเป็นส่วนตัวและความปลอดภัยของข้อมูล
ด้วย xTuring คุณสามารถ
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))คุณสามารถค้นหาโฟลเดอร์ข้อมูลได้ที่นี่
เรารู้สึกตื่นเต้นที่จะประกาศการปรับปรุงล่าสุดให้กับไลบรารี xTuring ของเรา:
LLaMA 2 - คุณสามารถใช้และปรับแต่งโมเดล LLaMA 2 ได้ในการกำหนดค่าที่แตกต่างกัน: มีจำหน่ายทั่วไป , มีจำหน่ายทั่วไปด้วยความแม่นยำ INT8 , การปรับแต่ง LoRA อย่างละเอียด , การปรับแต่ง LoRA อย่างละเอียดด้วยความแม่นยำ INT8 และ LoRA ละเอียด ปรับแต่งด้วยความแม่นยำ INT4 โดยใช้ wrapper GenericModel และ/หรือคุณสามารถใช้คลาส Llama2 จาก xturing.models เพื่อทดสอบและปรับแต่งโมเดล from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation - ตอนนี้คุณสามารถประเมิน Causal Language Model บนชุดข้อมูลใดก็ได้ ตัวชี้วัดที่รองรับในปัจจุบันคือ perplexity # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4 Precision - ตอนนี้คุณสามารถใช้และปรับแต่ง LLM ใด ๆ ด้วย INT4 Precision โดยใช้ GenericLoraKbitModel ได้แล้ว # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )แนะนำให้สำรวจตัวอย่างการทำงานของ Llama LoRA INT4 เพื่อทำความเข้าใจการใช้งาน
หากต้องการข้อมูลเชิงลึกเพิ่มเติม ให้พิจารณาตรวจสอบตัวอย่างการทำงานของ GenericModel ที่มีอยู่ในพื้นที่เก็บข้อมูล

$ xturing chat -m " <path-to-model-folder> "
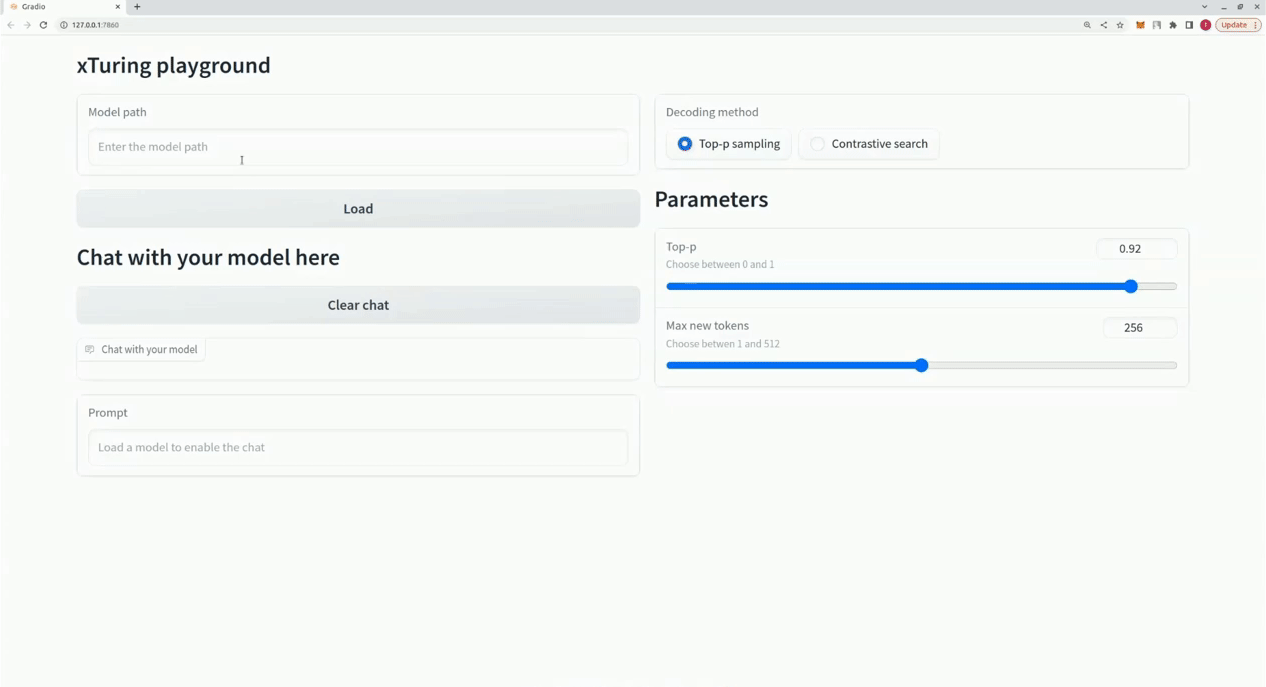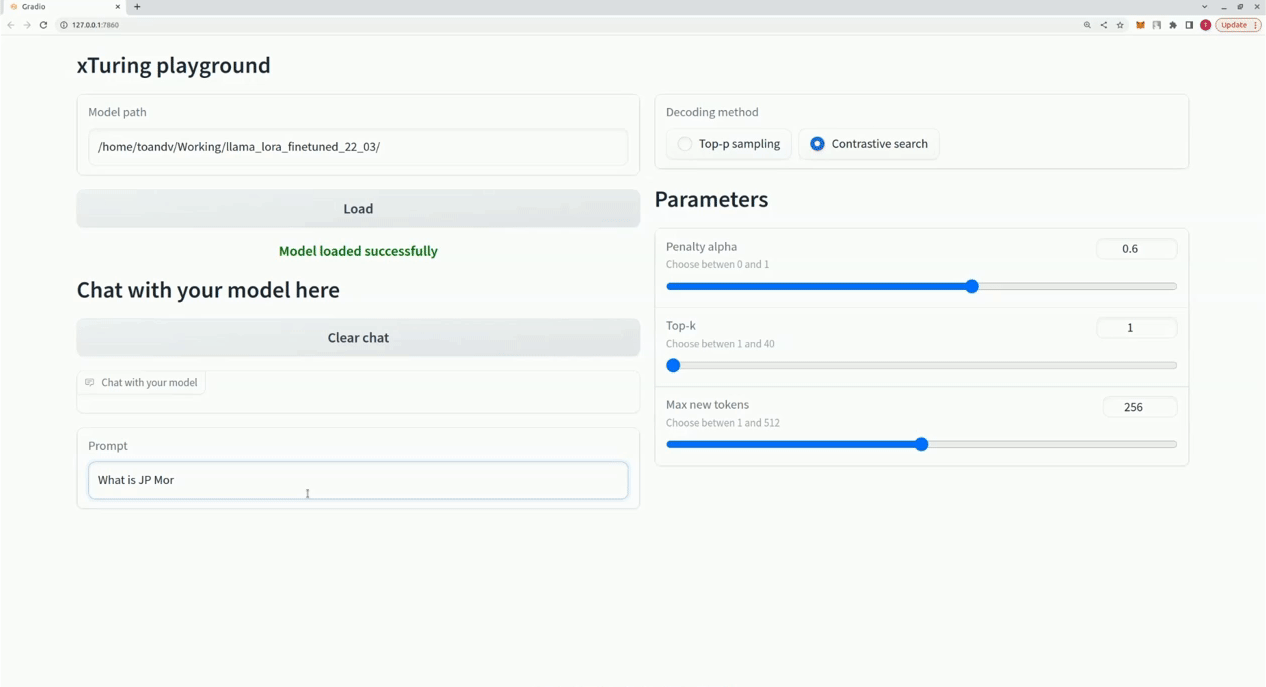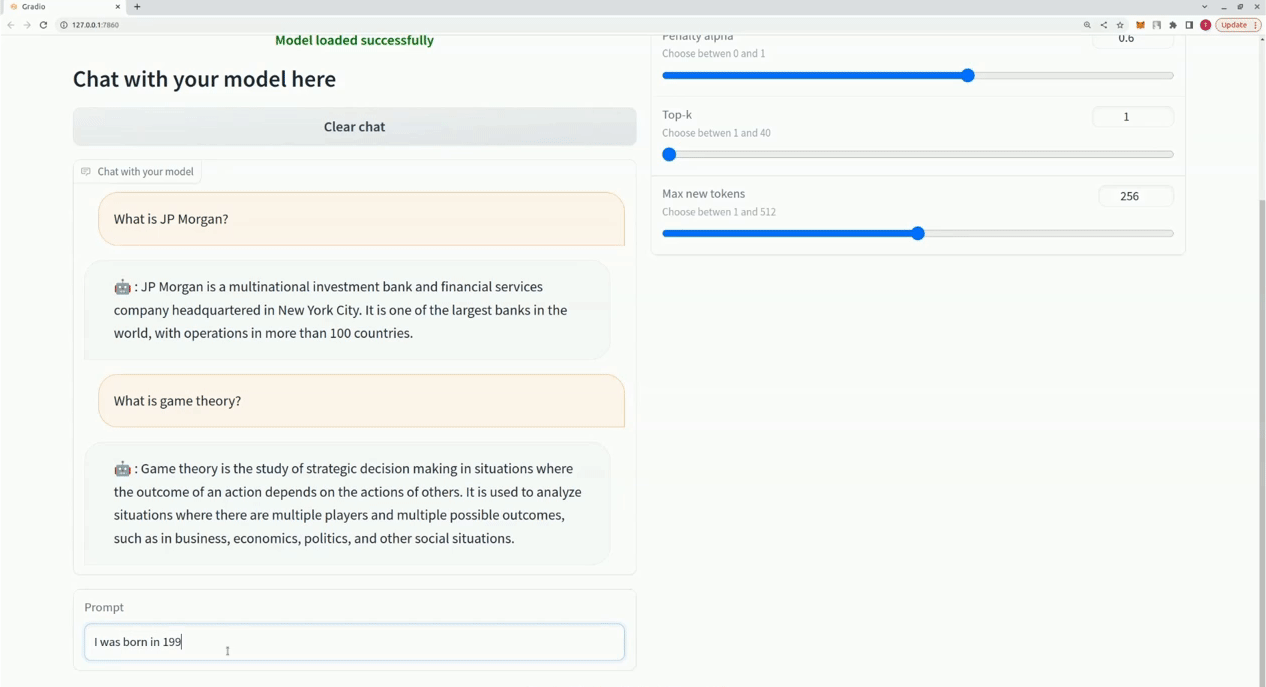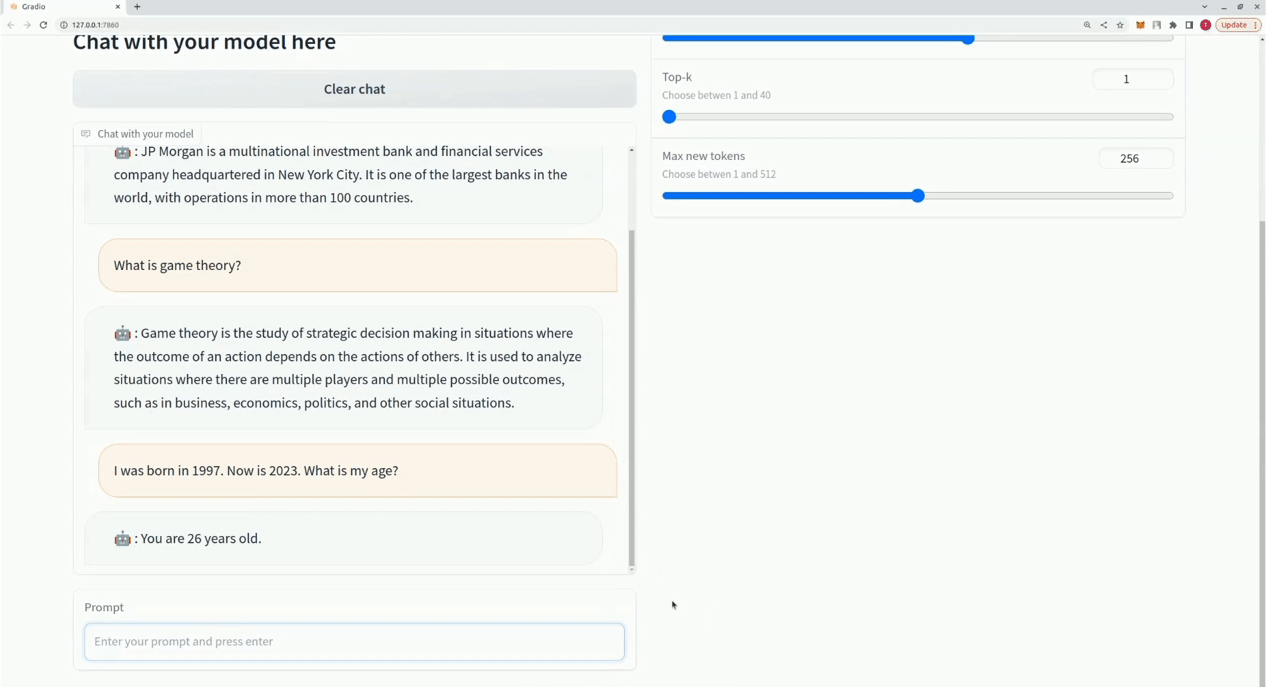
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI นี่คือการเปรียบเทียบประสิทธิภาพของเทคนิคการปรับแต่งแบบละเอียดต่างๆ ในรุ่น LLaMA 7B เราใช้ชุดข้อมูล Alpaca เพื่อการปรับแต่งอย่างละเอียด ชุดข้อมูลประกอบด้วยคำสั่ง 52K
ฮาร์ดแวร์:
4xA100 GPU 40GB, ซีพียูแรม 335GB
พารามิเตอร์การปรับแต่งแบบละเอียด:
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| ลามา-7บี | DeepSpeed + การถ่าย CPU | LoRA + ดีพสปีด | LoRA + DeepSpeed + การถ่าย CPU |
|---|---|---|---|
| จีพียู | 33.5GB | 23.7GB | 21.9GB |
| ซีพียู | 190GB | 10.2GB | 14.9GB |
| เวลา/ยุค | 21 ชม | 20 นาที | 20 นาที |
สนับสนุนเรื่องนี้ด้วยการส่งผลการปฏิบัติงานของคุณบน GPU อื่นๆ โดยสร้างปัญหาเกี่ยวกับข้อกำหนดฮาร์ดแวร์ การใช้หน่วยความจำ และเวลาต่อยุค
เราได้ปรับแต่งโมเดลบางรุ่นที่คุณสามารถใช้เป็นฐานหรือเริ่มเล่นได้อย่างละเอียดแล้ว นี่คือวิธีที่คุณจะโหลด:
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| แบบอย่าง | ชุดข้อมูล | เส้นทาง |
|---|---|---|
| กลั่น GPT-2 LoRA | เนื้ออัลปาก้า | x/distilgpt2_lora_finetuned_alpaca |
| ลามา ลอรา | เนื้ออัลปาก้า | x/llama_lora_finetuned_alpaca |
ด้านล่างนี้คือรายการรุ่นที่รองรับทั้งหมดผ่านคลาส BaseModel ของ xTuring และคีย์ที่เกี่ยวข้องในการโหลด
| แบบอย่าง | สำคัญ |
|---|---|
| บลูม | บานสะพรั่ง |
| สมอง | สมอง |
| กลั่น GPT-2 | กลั่นกรอง2 |
| ฟอลคอน-7บี | เหยี่ยว |
| กาแลกติกา | กาแลกติกา |
| GPT-เจ | gptj |
| GPT-2 | GPT2 |
| ลามะ | ลามะ |
| ลามา2 | ลามะ2 |
| OPT-1.3B | เลือก |
สิ่งที่กล่าวมาข้างต้นเป็นตัวแปรพื้นฐานของ LLM ด้านล่างนี้คือเทมเพลตสำหรับรับเวอร์ชัน LoRA , INT8 , INT8 + LoRA และ INT4 + LoRA
| เวอร์ชัน | แม่แบบ |
|---|---|
| โลรา | <model_key>_lora |
| INT8 | <model_key>_int8 |
| INT8 + ลอร่า | <model_key>_lora_int8 |
** ในการโหลดเวอร์ชัน INT4+LoRA ของโมเดลใดๆ คุณจะต้องใช้คลาส GenericLoraKbitModel จาก xturing.models ด้านล่างนี้เป็นวิธีการใช้งาน:
model = GenericLoraKbitModel ( '<model_path>' ) model_path สามารถแทนที่ได้ด้วยไดเร็กทอรีในเครื่องของคุณหรือโมเดลไลบรารี HuggingFace เช่น facebook/opt-1.3b
LLaMA , GPT-J , GPT-2 , OPT , Cerebras-GPT , Galactica และ Bloom Generic model Falcon-7B หากคุณมีคำถามใดๆ คุณสามารถสร้างปัญหาในพื้นที่เก็บข้อมูลนี้ได้
คุณยังสามารถเข้าร่วมเซิร์ฟเวอร์ Discord ของเราและเริ่มการสนทนาในช่อง #xturing ได้
โครงการนี้ได้รับอนุญาตภายใต้ Apache License 2.0 - ดูรายละเอียดในไฟล์ LICENSE
ในฐานะโครงการโอเพ่นซอร์สในสาขาที่มีการพัฒนาอย่างรวดเร็ว เรายินดีรับการมีส่วนร่วมทุกประเภท รวมถึงคุณสมบัติใหม่และเอกสารประกอบที่ดีกว่า โปรดอ่านคู่มือการมีส่วนร่วมของเราเพื่อเรียนรู้วิธีการมีส่วนร่วม


