SynMeter
1.0.0

[24 พ.ย. 2024] เราเพิ่ม REaLTabFormer ซินธิไซเซอร์ SOTA HP ใหม่ให้กับ SynMeter! ลองดูสิ!
[18 ก.ย. 2024] เราเพิ่ม TabSyn ซินธิไซเซอร์ SOTA HP ใหม่ให้กับ SynMeter! ลองดูสิ!
สร้างสภาพแวดล้อมและการตั้งค่า conda ใหม่:
conda create -n synmeter python==3.9
conda activate synmeter
pip install -r requirements.txt # install dependencies
pip install -e . # package the library เปลี่ยนพจนานุกรมฐานใน ./lib/info/ROOT_DIR :
ROOT_DIR = root_to_synmeter
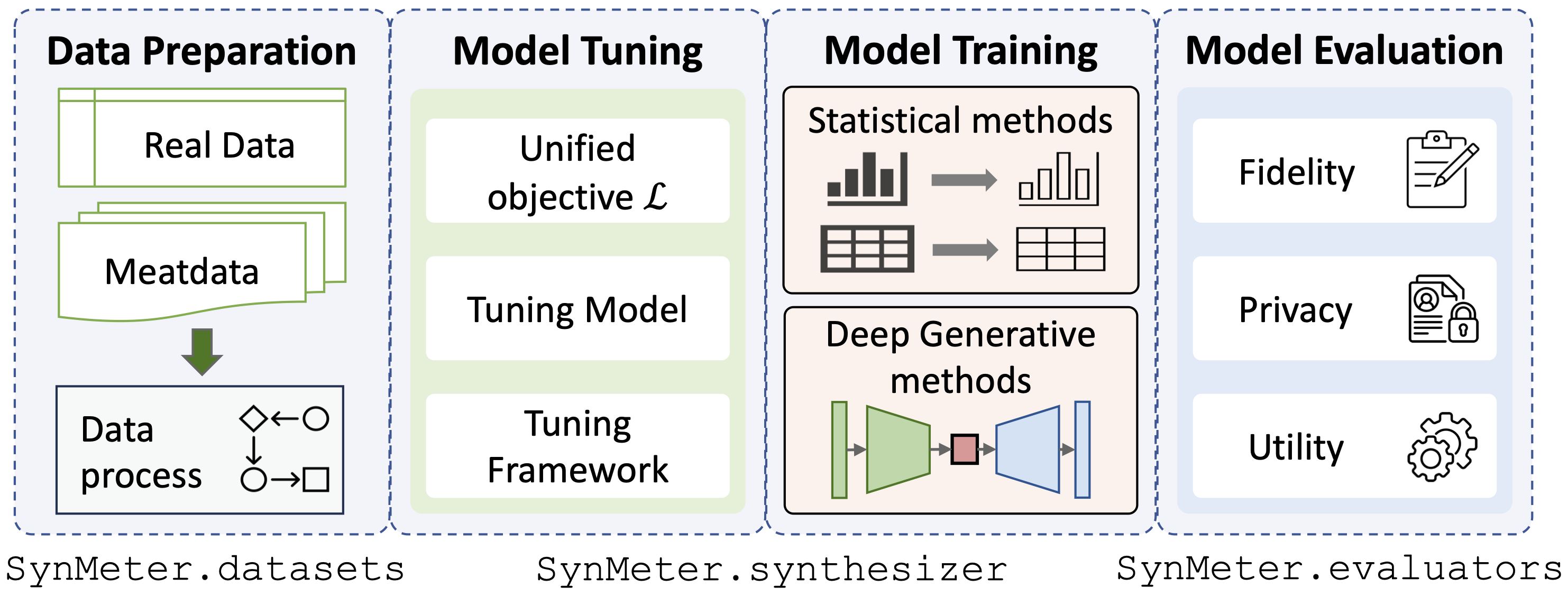
./dataset dataset./exp/evaluatorspython scripts/tune_evaluator.py -d [dataset] -c [cuda]เรามีวัตถุประสงค์ในการปรับแต่งแบบรวมศูนย์สำหรับการปรับแต่งโมเดล ดังนั้น ซินธิไซเซอร์ทุกประเภทจึงสามารถปรับแต่งได้ด้วยคำสั่งเดียว:
python scripts/tune_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda] หลังจากปรับแต่งแล้ว ควรบันทึกการกำหนดค่าลงใน /exp/dataset/synthesizer โดย SynMeter จะสามารถใช้เพื่อฝึกและจัดเก็บซินธิไซเซอร์ได้:
python scripts/train_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]การประเมินความเที่ยงตรงของข้อมูลสังเคราะห์:
python scripts/eval_fidelity.py -d [dataset] -m [synthesizer] -s [seed] -t [target] การประเมินความเป็นส่วนตัวของข้อมูลสังเคราะห์:
python scripts/eval_privacy.py -d [dataset] -m [synthesizer] -s [seed]การประเมินประโยชน์ของข้อมูลสังเคราะห์:
python scripts/eval_utility.py -d [dataset] -m [synthesizer] -s [seed] ผลลัพธ์ของการประเมินควรบันทึกไว้ในพจนานุกรม /exp/dataset/synthesizer ที่เกี่ยวข้อง
ข้อดีอย่างหนึ่งของ SynMeter คือการมอบวิธีที่ง่ายที่สุดในการเพิ่มอัลกอริธึมการสังเคราะห์ใหม่ โดยต้องมีสามขั้นตอน:
./synthesizer/my_synthesiszer./exp/base_config./synthesizer ซึ่งมี 3 ฟังก์ชัน: train , sample และ tuneจากนั้น คุณมีอิสระในการปรับแต่ง รัน และทดสอบซินธิไซเซอร์ตัวใหม่!
| วิธี | พิมพ์ | คำอธิบาย | อ้างอิง |
|---|---|---|---|
| วิทยาศาสตรมหาบัณฑิต | ดีพี | วิธีการนี้ใช้แบบจำลองกราฟิกที่น่าจะเป็นเพื่อเรียนรู้การพึ่งพาส่วนขอบมิติต่ำสำหรับการสังเคราะห์ข้อมูล | กระดาษ, รหัส |
| พริฟซิน | ดีพี | ซินธิไซเซอร์ DP แบบไม่มีพารามิเตอร์ ซึ่งจะอัปเดตชุดข้อมูลสังเคราะห์ซ้ำๆ เพื่อให้ตรงกับส่วนขอบของสัญญาณรบกวนเป้าหมาย | กระดาษ, รหัส |
| วิธี | พิมพ์ | คำอธิบาย | อ้างอิง |
|---|---|---|---|
| ซีทีแกน | เอชพี | เครือข่ายฝ่ายตรงข้ามที่สร้างเงื่อนไขที่สามารถจัดการข้อมูลแบบตารางได้ | กระดาษ, รหัส |
| ปาเต้-GAN | ดีพี | วิธีการนี้ใช้เฟรมเวิร์ก Private Aggregation of Teacher Ensembles (PATE) และนำไปใช้กับ GAN | กระดาษ, รหัส |
| วิธี | พิมพ์ | คำอธิบาย | อ้างอิง |
|---|---|---|---|
| ทีวีเออี | เอชพี | เครือข่าย VAE แบบมีเงื่อนไขซึ่งสามารถจัดการข้อมูลแบบตารางได้ | กระดาษ, รหัส |
| วิธี | พิมพ์ | คำอธิบาย | อ้างอิง |
|---|---|---|---|
| แท็บDDPM | เอชพี | ใช้แบบจำลองการแพร่กระจายสำหรับการสังเคราะห์ข้อมูลแบบตาราง | กระดาษ, รหัส |
| แท็บซิน | เอชพี | ใช้แบบจำลองการแพร่กระจายแฝงและ VAE สำหรับการสังเคราะห์ | กระดาษ, รหัส |
| ตารางการแพร่กระจาย | ดีพี | การสร้างชุดข้อมูลแบบตารางภายใต้ความเป็นส่วนตัวที่แตกต่างกัน | กระดาษ, รหัส |
| วิธี | พิมพ์ | คำอธิบาย | อ้างอิง |
|---|---|---|---|
| ยอดเยี่ยม | เอชพี | ใช้ LLM เพื่อปรับแต่งชุดข้อมูลแบบตาราง | กระดาษ, รหัส |
| REaLTabอดีต | เอชพี | ใช้ GPT-2 เพื่อเรียนรู้การพึ่งพาเชิงสัมพันธ์ของข้อมูลแบบตาราง | กระดาษ, รหัส |
ตัวชี้วัดความเที่ยงตรง : เราถือว่าระยะทาง Wasserstein เป็นตัวชี้วัดความเที่ยงตรงตามหลักการ ซึ่งคำนวณโดยระยะขอบด้านเดียวและสองทางทั้งหมด
ตัวชี้วัดความเป็นส่วนตัว : เรากำหนดคะแนนการเปิดเผยข้อมูลสมาชิก (MDS) เพื่อวัดความเสี่ยงความเป็นส่วนตัวของสมาชิกภาพของทั้งซินธิไซเซอร์ของ HP และ DP
ตัวชี้วัดยูทิลิตี้ : เราใช้ความสัมพันธ์ของการเรียนรู้ของเครื่องและข้อผิดพลาดในการสืบค้นเพื่อวัดยูทิลิตี้ของข้อมูลสังเคราะห์
โปรดดูเอกสารของเราสำหรับรายละเอียดและการใช้งาน
มีการใช้อัลกอริธึมการสังเคราะห์ที่ยอดเยี่ยมและไลบรารีโอเพ่นซอร์สจำนวนมากในโครงการนี้:


