ข้อความฝังไปป์ไลน์สำหรับผ้าขี้ริ้ว
1.0.0
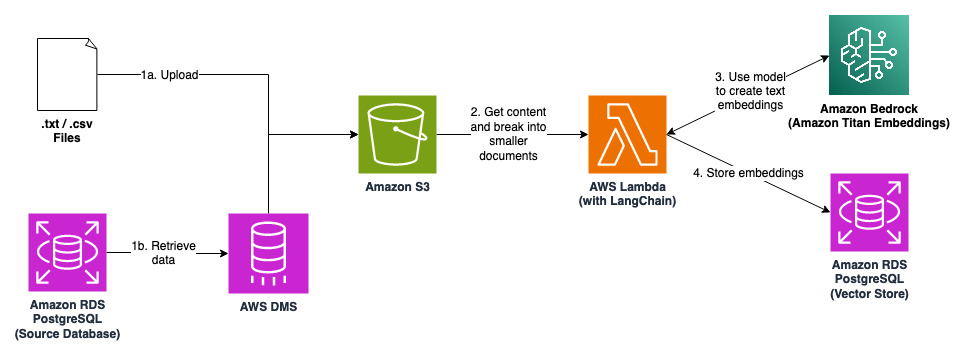
โซลูชันนี้เป็นไปป์ไลน์ในการแปลงความรู้ตามบริบทที่จัดเก็บไว้ในเอกสารและฐานข้อมูลเป็นการฝังข้อความ และจัดเก็บไว้ในที่เก็บเวกเตอร์ แอปพลิเคชันที่สร้างด้วยโมเดลภาษาขนาดใหญ่ (LLM) สามารถทำการค้นหาความคล้ายคลึงกันบนร้านค้าเวกเตอร์เพื่อดึงความรู้ตามบริบทก่อนที่จะสร้างการตอบกลับ เทคนิคนี้เรียกว่า Recoveryal Augmented Generation (RAG) และมักใช้เพื่อปรับปรุงคุณภาพและความแม่นยำของการตอบสนอง
ตรวจสอบและเปลี่ยนแปลงการกำหนดค่าก่อนใช้งานจริง : ไม่ควรใช้การกำหนดค่าปัจจุบันสำหรับการผลิตโดยไม่มีการตรวจสอบและดัดแปลงเพิ่มเติม มีการนำรูปแบบการต่อต้านหลายรูปแบบมาใช้เพื่อประหยัดค่าใช้จ่าย เช่น การปิดใช้งานการสำรองข้อมูลและหลาย AZ
คำนึงถึงต้นทุนที่เกิดขึ้น : แม้ว่าโซลูชันนี้ได้รับการพัฒนาให้มีความคุ้มค่า แต่โปรดคำนึงถึงต้นทุนที่เกิดขึ้นด้วย

โคลนที่เก็บนี้
สร้างคู่คีย์ EC2 ชื่อ "EC2DefaultKeyPair" ในบัญชี AWS ของคุณ
ติดตั้งการพึ่งพา
npm installcdk bootstrapฟังก์ชัน Package Lambda และการขึ้นต่อกัน
sh prepare-lambda-package.sh.prepare-lambda-package.ps1ปรับใช้สแต็ก CDK
cdk deploy --all --require-approval neverมีสองวิธีในการอัปโหลดข้อมูลไปยังบัคเก็ต S3
(ก) อัปโหลดไฟล์ .txt ที่มีเนื้อหาบางส่วน (ตัวอย่าง.txt เป็นตัวอย่าง) ไปยังบัคเก็ต S3 ที่สร้างโดยหนึ่งในสแต็ก
(b) เริ่มงานการจำลอง DMS ในคอนโซลการจัดการ AWS ข้อมูลจากฐานข้อมูลต้นทางจะถูกจำลองไปยังบัคเก็ต S3 และจัดเก็บไว้ในไฟล์ .csv

ฟังก์ชัน Lambda จะสร้างการฝังข้อความของเนื้อหาในไฟล์ .txt / .csv และจัดเก็บไว้ในร้านค้าเวกเตอร์
เชื่อมต่อ (SSH หรือการเชื่อมต่ออินสแตนซ์) กับโฮสต์ป้อมปราการ รันคำสั่งต่อไปนี้ (และระบุรหัสผ่าน) เพื่อตรวจสอบสิทธิ์ ข้อมูลรับรองสามารถพบได้ในส่วนลับ "text-embeddings-pipeline-vector-store" ใน AWS Secrets Manager
psql --port=5432 --dbname=postgres --username=postgres --host= < RDS instance DNS name >dt เพื่อแสดงรายการตารางฐานข้อมูล ตารางที่มีชื่อขึ้นต้นด้วยคำนำหน้า "langchain" จะถูกสร้างขึ้นโดย LangChain โดยอัตโนมัติในขณะที่สร้างและจัดเก็บการฝัง List of relations
Schema | Name | Type | Owner
--------+-------------------------+-------+----------
public | langchain_pg_collection | table | postgres
public | langchain_pg_embedding | table | postgres
public | upsertion_record | table | postgres
(3 rows)
เอกสารและการฝังจะถูกจัดเก็บไว้ในตาราง "langchain_pg_embedding" คุณสามารถดูค่าที่ถูกตัดทอน (ค่าจริงยาวเกินไป) ได้โดยการรันคำสั่งต่อไปนี้
SELECT embedding::varchar(80) FROM langchain_pg_embedding; embedding
----------------------------------------------------------------------------------
[-0.005340576,-0.61328125,0.13769531,0.7890625,0.4296875,-0.13671875,-0.01379394 ...
[0.59375,-0.23339844,0.45703125,-0.14257812,-0.18164062,0.0030517578,-0.00933837 ...
(2 rows)
SELECT document::varchar(80) FROM langchain_pg_embedding; document
----------------------------------------------------------------------------------
What is text embeddings pipeline?,Text embeddings pipeline allows you to create ...
AWS Health provides improved visibility into planned lifecycle events ...
(2 rows)
cdk destroy --allดูการมีส่วนร่วมสำหรับข้อมูลเพิ่มเติม
ห้องสมุดนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT-0 ดูไฟล์ใบอนุญาต