AttackVLM
1.0.0
[หน้าโครงการ] | [สไลด์] | [arXiv] | [พื้นที่เก็บข้อมูล]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

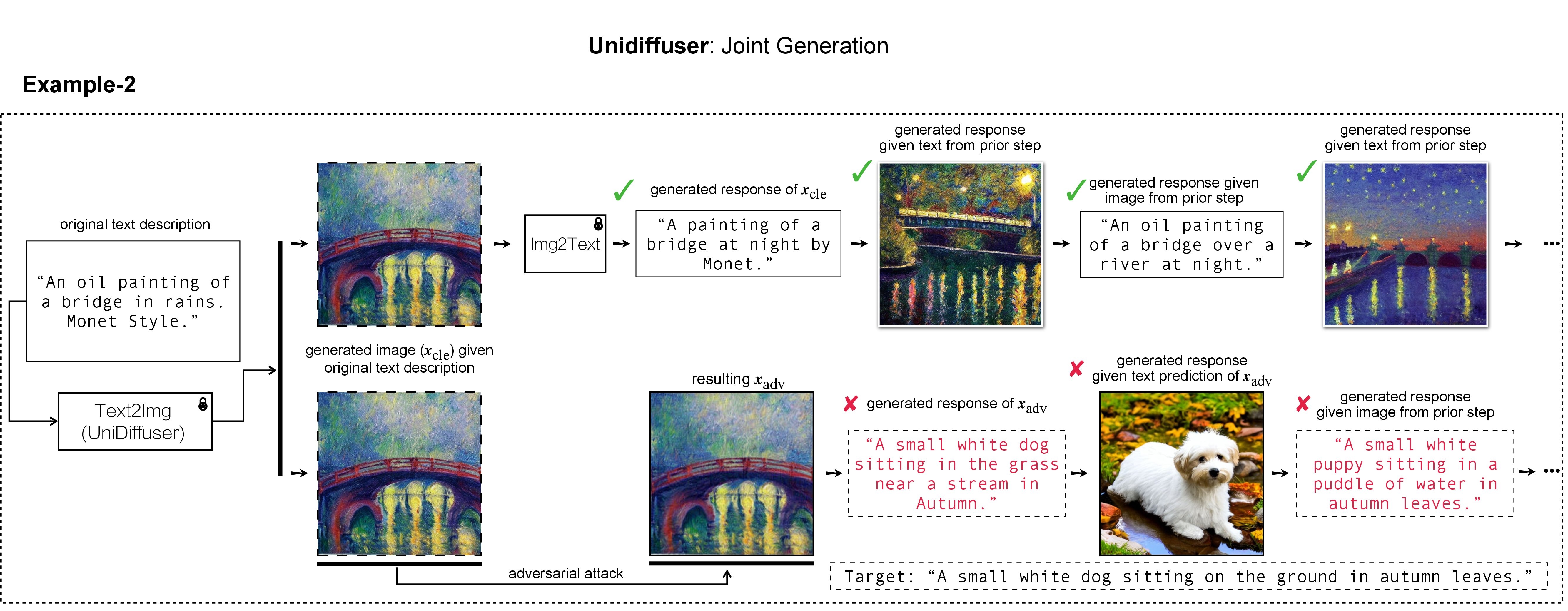
ในงานของเรา เราใช้ DALL-E, Midjourney และ Stable Diffusion สำหรับการสร้างและการสาธิตภาพเป้าหมาย สำหรับการทดลองขนาดใหญ่ เราใช้ Stable Diffusion สำหรับการสร้างภาพเป้าหมาย ในการติดตั้ง Stable Diffusion เราจะเริ่มต้นสภาพแวดล้อม conda ตาม Latent Diffusion Models สภาพแวดล้อม conda ฐานที่เหมาะสมชื่อ ldm สามารถสร้างและเปิดใช้งานได้ด้วย:
conda env create -f environment.yaml
conda activate ldm
โปรดทราบว่าสำหรับโมเดลเหยื่อที่แตกต่างกัน เราจะติดตามการใช้งานอย่างเป็นทางการและสภาพแวดล้อม conda
 ตามที่กล่าวไว้ในรายงานของเรา เพื่อให้บรรลุการโจมตีแบบกำหนดเป้าหมายที่ยืดหยุ่น เราใช้โมเดลข้อความเป็นรูปภาพที่ได้รับการฝึกอบรมมาล่วงหน้าเพื่อสร้างรูปภาพเป้าหมายโดยมีคำบรรยายเดียวเป็นข้อความเป้าหมาย ด้วยเหตุนี้คุณจึงสามารถระบุคำบรรยายเป้าหมายสำหรับการโจมตีได้ด้วยตัวเอง!
ตามที่กล่าวไว้ในรายงานของเรา เพื่อให้บรรลุการโจมตีแบบกำหนดเป้าหมายที่ยืดหยุ่น เราใช้โมเดลข้อความเป็นรูปภาพที่ได้รับการฝึกอบรมมาล่วงหน้าเพื่อสร้างรูปภาพเป้าหมายโดยมีคำบรรยายเดียวเป็นข้อความเป้าหมาย ด้วยเหตุนี้คุณจึงสามารถระบุคำบรรยายเป้าหมายสำหรับการโจมตีได้ด้วยตัวเอง!
เราใช้ Stable Diffusion, DALL-E หรือ Midjourney เป็นตัวสร้างข้อความเป็นรูปภาพในการทดลองของเรา ที่นี่เราใช้ Stable Diffusion เพื่อการสาธิต (ขอบคุณสำหรับโอเพ่นซอร์ส!)
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
จากนั้น เตรียมคำบรรยายเป้าหมายแบบเต็มจาก MS-COCO หรือดาวน์โหลดเวอร์ชันที่ประมวลผลและล้างแล้วของเรา:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
และย้ายไปที่ ./stable-diffusion/ / ในการทดลอง เราสามารถสุ่มตัวอย่างชุดย่อยของคำบรรยาย COCO (เช่น 10 , 100 , 1K , 10K , 50K ) สำหรับการโจมตีฝ่ายตรงข้าม ตัวอย่างเช่น สมมติว่าเราสุ่มตัวอย่างคำบรรยาย COCO 10K เป็นข้อความเป้าหมาย c_tar และจัดเก็บไว้ในไฟล์ต่อไปนี้:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
สามารถรับรูปภาพเป้าหมาย h_ξ(c_tar) ผ่าน Stable Diffusion โดยการอ่านข้อความแจ้งจากคำอธิบายภาพ COCO ตัวอย่าง พร้อมด้วยสคริปต์ด้านล่างและ txt2img_coco.py (โปรดย้าย txt2img_coco.py ไปที่ ./stable-diffusion/ -diffusion/ โปรดทราบว่าไฮเปอร์พารามิเตอร์สามารถเป็นได้ ปรับตามความต้องการของคุณ):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
โดยที่ ckpt มาจาก Stable Diffusion v1 และสามารถดาวน์โหลดได้ที่นี่: sd-v1-4-full-ema.ckpt
รายละเอียดการใช้งานเพิ่มเติมของการสร้างข้อความเป็นรูปภาพโดย Stable Diffusion มีอยู่ที่นี่
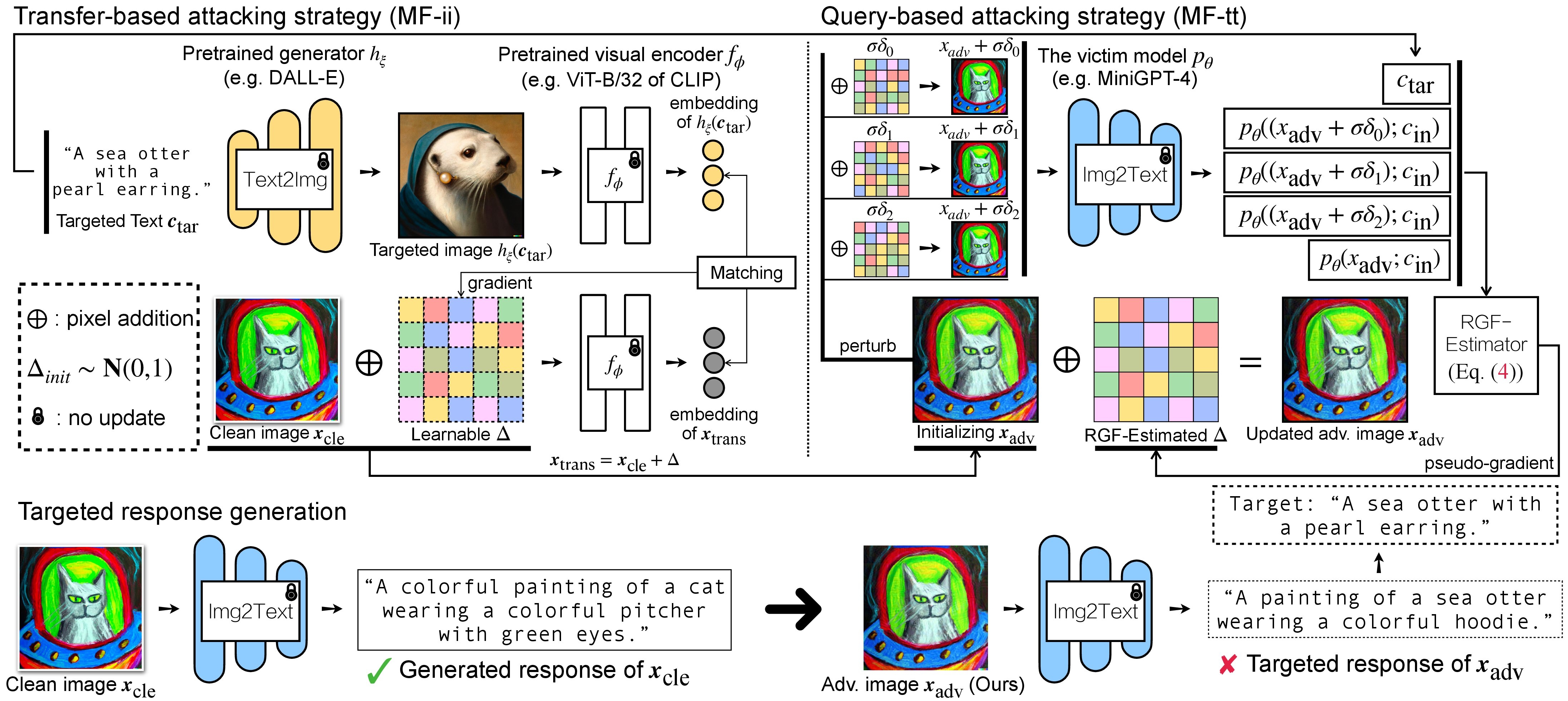
การโจมตีฝ่ายตรงข้ามสำหรับ VLM มีสองขั้นตอน: (1) กลยุทธ์การโจมตีแบบถ่ายโอนข้อมูล และ (2) กลยุทธ์การโจมตีแบบสืบค้นโดยใช้ (1) เป็นการเริ่มต้น สำหรับรุ่น BLIP/BLIP-2/Img2Prompt โปรดดูที่ ./LAVIS_tool LAVIS_tool ในที่นี้ เราใช้ Unidiffuser เป็นตัวอย่าง
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
จากนั้น สร้างสภาพแวดล้อม conda ที่เหมาะสมชื่อ unidiffuser โดยทำตามขั้นตอน ที่นี่ และเตรียมน้ำหนักโมเดลที่เกี่ยวข้อง (เราใช้ uvit_v1.pth เป็นน้ำหนักของ U-ViT)
conda activate unidiffuser
bash _train_adv_img_trans.sh
รูปภาพ adv ที่สร้างขึ้น x_trans จะถูกเก็บไว้ใน dir of white-box transfer images ที่ระบุใน --output จากนั้น เราทำการแสดงรูปภาพเป็นข้อความและจัดเก็บการตอบสนองที่สร้างขึ้นของ x_trans ซึ่งสามารถทำได้โดย:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
โดยที่การตอบกลับที่สร้างขึ้นจะถูกจัดเก็บไว้ใน dir of white-box transfer captions ในรูปแบบ . .txt เราจะใช้มันสำหรับการประมาณค่าหลอกแบบไล่ระดับโดยใช้ตัวประมาณค่า RGF
MF-ii + MF-tt (เช่น 8 px) bash _train_trans_and_query_fixed_budget.sh
ในทางกลับกัน หากคุณต้องการดำเนินการโจมตีแบบโอน+สืบค้นโดยมี งบประมาณก่อกวนแยกต่างหาก เราก็จัดเตรียมสคริปต์เพิ่มเติมให้:
bash _train_trans_and_query_more_budget.sh
ที่นี่ เราใช้ wandb เพื่อตรวจสอบค่าเฉลี่ยเคลื่อนที่ของคะแนน CLIP แบบไดนามิก (เช่น RN50, ViT-B/32, ViT-L/14 เป็นต้น) เพื่อประเมินความคล้ายคลึงกันระหว่าง (a) การตอบสนองที่สร้างขึ้น (ของ trans/ ค้นหารูปภาพ) และ (b) ข้อความเป้าหมายที่กำหนดไว้ล่วงหน้า c_tar
ตัวอย่างที่แสดงด้านล่าง โดยที่เส้นประแสดงถึงค่าเฉลี่ยเคลื่อนที่ของคะแนน CLIP (ของคำบรรยายภาพ) หลังจากการสืบค้น: 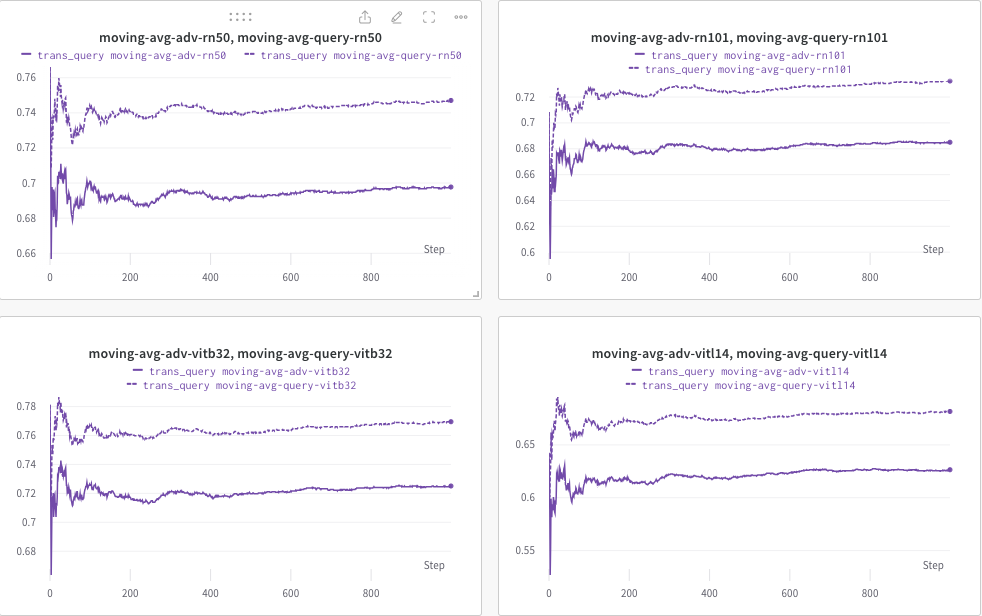
ในขณะเดียวกัน คำบรรยายภาพหลังจากการสืบค้นจะถูกจัดเก็บและสามารถระบุไดเร็กทอรีได้ด้วย --output
หากคุณพบว่าโครงการนี้มีประโยชน์ในการวิจัยของคุณ โปรดพิจารณาอ้างอิงรายงานของเรา:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
ในขณะเดียวกัน งานวิจัยที่เกี่ยวข้องซึ่งมีจุดมุ่งหมายเพื่อฝังลายน้ำให้กับแบบจำลองการแพร่กระจาย (หลายรูปแบบ):
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
เราขอขอบคุณการใช้งาน MiniGPT-4, LLaVA, Unidiffuser, LAVIS และ CLIP ที่ยอดเยี่ยม นอกจากนี้เรายังขอขอบคุณ @MetaAI สำหรับการเปิดแหล่งตรวจสอบ LLaMA ของพวกเขา เราขอขอบคุณ SiSi ที่ได้มอบภาพที่สนุกสนานและสวยงามซึ่งสร้างโดย @Midjourney ในการวิจัยของเรา


