SDV
v1.17.2 - 2024-11-18
พื้นที่เก็บข้อมูลนี้เป็นส่วนหนึ่งของโครงการ Synthetic Data Vault ซึ่งเป็นโครงการจาก DataCebo



Synthetic Data Vault (SDV) คือไลบรารี Python ที่ออกแบบมาให้เป็นร้านค้าครบวงจรสำหรับการสร้างข้อมูลสังเคราะห์แบบตาราง SDV ใช้อัลกอริธึมการเรียนรู้ของเครื่องที่หลากหลายเพื่อเรียนรู้รูปแบบจากข้อมูลจริงของคุณและจำลองข้อมูลเหล่านั้นในข้อมูลสังเคราะห์
- สร้างข้อมูลสังเคราะห์โดยใช้การเรียนรู้ของเครื่อง SDV นำเสนอโมเดลหลายรูปแบบ ตั้งแต่วิธีการทางสถิติแบบคลาสสิก (GaussianCopula) ไปจนถึงวิธีการเรียนรู้เชิงลึก (CTGAN) สร้างข้อมูลสำหรับตารางเดี่ยว ตารางที่เชื่อมต่อหลายตาราง หรือตารางตามลำดับ
ประเมินและแสดงภาพข้อมูล เปรียบเทียบข้อมูลสังเคราะห์กับข้อมูลจริงกับการวัดผลต่างๆ วินิจฉัยปัญหาและสร้างรายงานคุณภาพเพื่อรับข้อมูลเชิงลึกเพิ่มเติม
ประมวลผลล่วงหน้า ไม่ระบุชื่อ และกำหนดข้อจำกัด ควบคุมการประมวลผลข้อมูลเพื่อปรับปรุงคุณภาพของข้อมูลสังเคราะห์ เลือกประเภทต่างๆ ของการไม่ระบุชื่อ และกำหนดกฎเกณฑ์ทางธุรกิจในรูปแบบของข้อจำกัดเชิงตรรกะ
| ลิงค์ที่สำคัญ | |
|---|---|
 บทช่วยสอน บทช่วยสอน | สัมผัสประสบการณ์ตรงกับ SDV เปิดสมุดบันทึกบทช่วยสอนและรันโค้ดด้วยตัวเอง |
| เอกสาร | เรียนรู้วิธีใช้ไลบรารี SDV พร้อมคู่มือผู้ใช้และข้อมูลอ้างอิง API |
| - บล็อก | รับข้อมูลเชิงลึกเพิ่มเติมเกี่ยวกับการใช้ SDV การปรับใช้โมเดล และชุมชนข้อมูลสังเคราะห์ของเรา |
 ชุมชน ชุมชน | เข้าร่วมพื้นที่ทำงาน Slack ของเราเพื่อรับประกาศและการสนทนา |
| เว็บไซต์ | ตรวจสอบเว็บไซต์ SDV สำหรับข้อมูลเพิ่มเติมเกี่ยวกับโครงการ |
SDV เผยแพร่ต่อสาธารณะภายใต้ Business Source License ติดตั้ง SDV โดยใช้ pip หรือ conda เราขอแนะนำให้ใช้สภาพแวดล้อมเสมือนจริงเพื่อหลีกเลี่ยงความขัดแย้งกับซอฟต์แวร์อื่นบนอุปกรณ์ของคุณ
pip install sdvconda install -c pytorch -c conda-forge sdvโหลดชุดข้อมูลสาธิตเพื่อเริ่มต้น ชุดข้อมูลนี้เป็นตารางเดี่ยวที่อธิบายแขกที่มาพักที่โรงแรมสมมติ
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )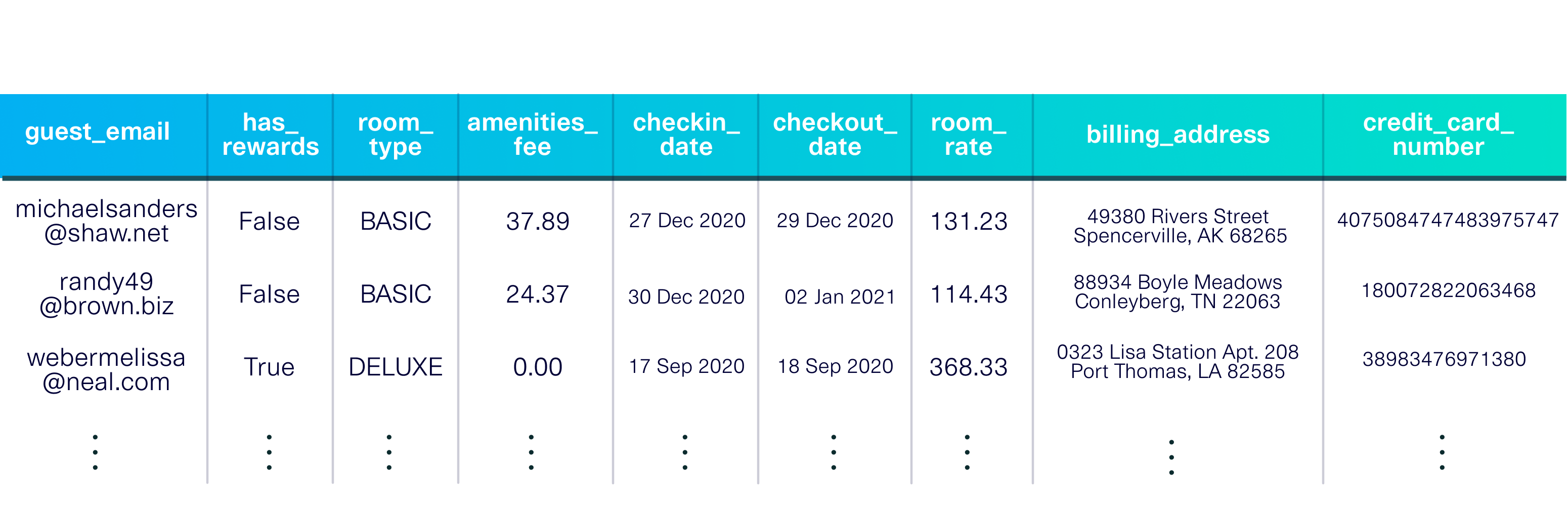
การสาธิตยังรวมถึง ข้อมูลเมตา คำอธิบายของชุดข้อมูล รวมถึงประเภทข้อมูลในแต่ละคอลัมน์และคีย์หลัก ( guest_email )
ต่อไป เราสามารถสร้าง SDV ซินธิไซเซอร์ ซึ่งเป็นออบเจ็กต์ที่คุณสามารถใช้เพื่อสร้างข้อมูลสังเคราะห์ได้ เรียนรู้รูปแบบจากข้อมูลจริงและทำซ้ำเพื่อสร้างข้อมูลสังเคราะห์ ลองใช้ GaussianCopulaSynthesizer กัน
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )และตอนนี้ซินธิไซเซอร์ก็พร้อมที่จะสร้างข้อมูลสังเคราะห์แล้ว!
synthetic_data = synthesizer . sample ( num_rows = 500 )ข้อมูลสังเคราะห์จะมีคุณสมบัติดังต่อไปนี้:
ไลบรารี SDV ช่วยให้คุณสามารถประเมินข้อมูลสังเคราะห์โดยเปรียบเทียบกับข้อมูลจริง เริ่มต้นด้วยการสร้างรายงานคุณภาพ
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
ออบเจ็กต์นี้จะคำนวณคะแนนคุณภาพโดยรวมในระดับ 0 ถึง 100% (100 คือดีที่สุด) ตลอดจนรายละเอียดต่างๆ หากต้องการข้อมูลเชิงลึกเพิ่มเติม คุณยังสามารถแสดงภาพข้อมูลสังเคราะห์เทียบกับข้อมูลจริงได้
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()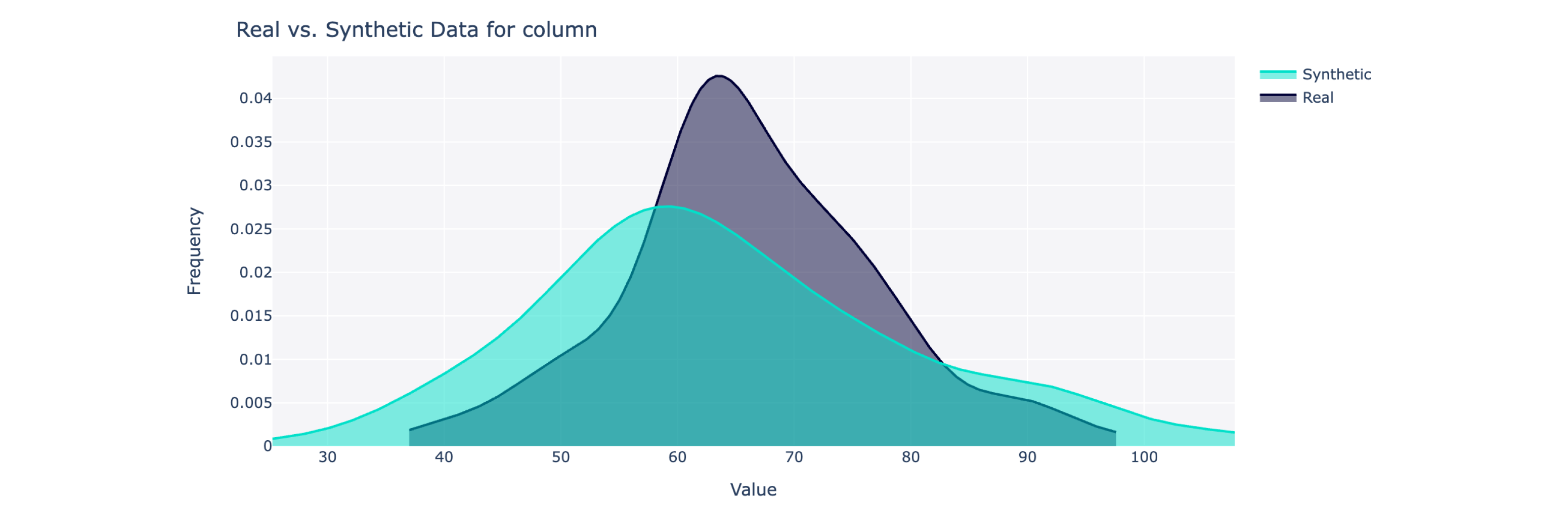
การใช้ไลบรารี SDV คุณสามารถสังเคราะห์ตารางเดี่ยว หลายตาราง และข้อมูลตามลำดับได้ คุณยังสามารถปรับแต่งเวิร์กโฟลว์ข้อมูลสังเคราะห์แบบเต็ม รวมถึงการประมวลผลล่วงหน้า การลบข้อมูลระบุตัวตน และการเพิ่มข้อจำกัด
หากต้องการเรียนรู้เพิ่มเติม โปรดไปที่หน้าสาธิต SDV
ขอขอบคุณทีมงานผู้มีส่วนร่วมของเราที่สร้างและดูแลรักษาระบบนิเวศ SDV ตลอดหลายปีที่ผ่านมา!
ดูผู้มีส่วนร่วม
หากคุณใช้ SDV สำหรับการวิจัยของคุณ โปรดอ้างอิงรายงานต่อไปนี้:
เนฮา แพตกี, รอย เวดจ์, กัลยัน วีรมชาเนนี . ห้องนิรภัยข้อมูลสังเคราะห์ IEEE DSAA 2016
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
โครงการ Synthetic Data Vault ถูกสร้างขึ้นครั้งแรกที่ Data to AI Lab ของ MIT ในปี 2559 หลังจาก 4 ปีของการวิจัยและความร่วมมือกับองค์กร เราได้สร้าง DataCebo ในปี 2020 โดยมีเป้าหมายในการขยายโครงการ ปัจจุบัน DataCebo เป็นผู้พัฒนา SDV ซึ่งเป็นระบบนิเวศที่ใหญ่ที่สุดสำหรับการสร้างและประเมินข้อมูลสังเคราะห์ เป็นที่ตั้งของไลบรารีหลายแห่งที่รองรับข้อมูลสังเคราะห์ รวมถึง:
เริ่มต้นใช้งานแพ็คเกจ SDV ซึ่งเป็นโซลูชันแบบครบวงจรและแหล่งรวมข้อมูลสังเคราะห์ในที่เดียว หรือใช้ไลบรารีแบบสแตนด์อโลนสำหรับความต้องการเฉพาะ


