LipGER
Initial Release
นี่คือการดำเนินการอย่างเป็นทางการสำหรับรายงานของเรา LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition ที่ InterSpeech 2024 ซึ่งได้รับการเลือกสำหรับ การนำเสนอด้วยวาจา
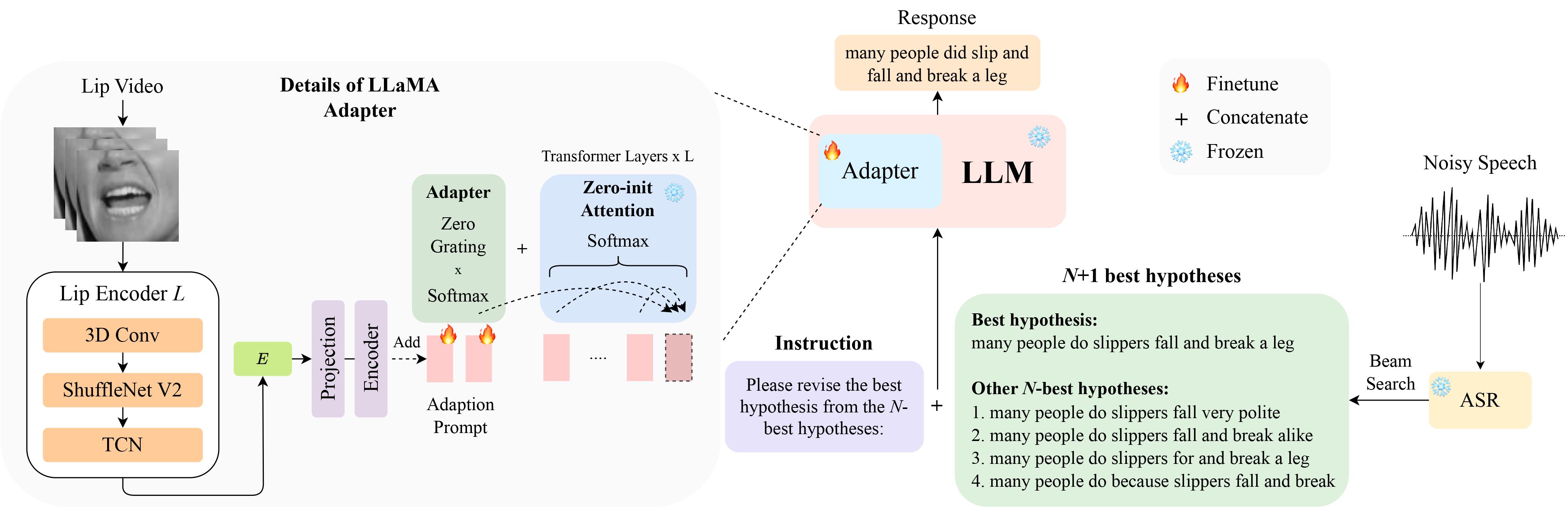
คุณสามารถดาวน์โหลดข้อมูล LipHyp ได้จากที่นี่!
pip install -r requirements.txt
ขั้นแรกให้เตรียมจุดตรวจโดยใช้:
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfหากต้องการดูจุดตรวจสอบที่มีอยู่ทั้งหมด ให้รัน:
python scripts/download.py | grep Llama-2สำหรับรายละเอียดเพิ่มเติม คุณสามารถดูได้จากลิงก์นี้ ซึ่งคุณสามารถเตรียมจุดตรวจสอบอื่นๆ สำหรับรุ่นอื่นๆ ได้ด้วย โดยเฉพาะเราใช้ TinyLlama สำหรับการทดลองของเรา
มีจุดตรวจอยู่ที่นี่ หลังจากดาวน์โหลดแล้วให้เปลี่ยนเส้นทางของด่านที่นี่
LipGER คาดว่าไฟล์ train, val และ test ทั้งหมดจะอยู่ในรูปแบบ example_data.json อินสแตนซ์ในไฟล์ดูเหมือนว่า:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
คุณต้องส่งไฟล์คำพูดผ่านโมเดล ASR ที่ผ่านการฝึกอบรมซึ่งสามารถสร้างสมมติฐานที่ดีที่สุด N ได้ เรามี 2 วิธีใน Repo นี้เพื่อช่วยให้คุณบรรลุเป้าหมายนี้ อย่าลังเลที่จะใช้วิธีการอื่น
pip install whisper แล้วรัน nhyps.py จากโฟลเดอร์ data คุณควรจะดี! โปรดทราบว่าสำหรับทั้งสองวิธี วิธีแรกในรายการคือสมมติฐานที่ดีที่สุด และวิธีอื่นๆ เป็นสมมติฐานที่ดีที่สุด N (จะถูกส่งผ่านเป็นรายการฟิลด์ nhyps_base ของ JSON และใช้ในการสร้างพร้อมท์ในขั้นตอนถัดไป)
นอกจากนี้ วิธีการที่ให้มาจะใช้เฉพาะคำพูดเป็นอินพุตเท่านั้น สำหรับการสร้างสมมติฐานที่ดีที่สุดด้านภาพและเสียง เราใช้ Auto-AVSR หากคุณต้องการความช่วยเหลือเกี่ยวกับโค้ด โปรดแจ้งปัญหา!
สมมติว่าคุณมีวิดีโอที่เกี่ยวข้องสำหรับไฟล์คำพูดทั้งหมดของคุณ ให้ทำตามขั้นตอนเหล่านี้เพื่อครอบตัด ROI จากวิดีโอ
python crop_mouth_script.py
python covert_lip.py
สิ่งนี้จะแปลง mp4 ROI เป็น hdf5 รหัสจะเปลี่ยนเส้นทางของ mp4 ROI เป็น hdf5 ROI ในไฟล์ json เดียวกัน คุณสามารถเลือกจากเครื่องตรวจจับ "mediapipe" และ "retinaface" ได้โดยเปลี่ยน "เครื่องตรวจจับ" ใน default.yaml
หลังจากที่คุณมีสมมติฐานที่ดีที่สุด N แล้ว ให้สร้างไฟล์ JSON ในรูปแบบที่ต้องการ เราไม่ได้ให้รหัสเฉพาะสำหรับส่วนนี้เนื่องจากการจัดเตรียมข้อมูลอาจแตกต่างกันสำหรับทุกคน แต่รหัสควรจะเรียบง่าย โปรดแจ้งปัญหาอีกครั้งหากคุณมีข้อสงสัย!
สคริปต์การฝึกอบรมของ LipGER ไม่ใช้ JSON ในการฝึกอบรมหรือการประเมินผล คุณต้องแปลงให้เป็นไฟล์ pt คุณสามารถเรียกใช้ Convert_to_pt.py เพื่อให้บรรลุเป้าหมายนี้ได้! เปลี่ยน model_name ตามความต้องการของคุณในบรรทัด 27 และเพิ่มเส้นทางไปยัง JSON ของคุณในบรรทัด 58
หากต้องการปรับแต่ง LipGER เพียงเรียกใช้:
sh finetune.sh
โดยที่คุณต้องตั้งค่า data ด้วยตนเอง (ด้วยชื่อชุดข้อมูล), --train_path และ --val_path (พร้อมเส้นทางที่แน่นอนในการฝึกอบรมและไฟล์ .pt ที่ถูกต้อง)
สำหรับการอนุมาน ขั้นแรกให้เปลี่ยนพาธตามลำดับใน lipger.py ( exp_path และ checkpoint_dir ) จากนั้นจึงรัน (ด้วยอาร์กิวเมนต์พาธข้อมูลทดสอบที่เหมาะสม):
sh infer.sh
รหัสสำหรับ ROI ของครอบตัดปากได้รับแรงบันดาลใจจาก Visual_Speech_Recognition_for_Multiple_Languages
รหัสของเราสำหรับ LipGER ได้รับแรงบันดาลใจจาก RobustGER โปรดอ้างอิงรายงานของพวกเขาด้วยหากคุณพบว่าเอกสารหรือรหัสของเรามีประโยชน์
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


