ที่เก็บประกอบด้วย VQ-VAE ที่ดำเนินการใน Pytorch และได้รับการฝึกฝนในชุดข้อมูล MNIST
VQ-vae ทำตามแนวคิดพื้นฐานเดียวกันกับเบื้องหลังการเข้ารหัสอัตโนมัติ Variational (VAE) VQ-VAE ใช้ การฝังแฝงแบบไม่ต่อเนื่องสำหรับการเข้ารหัสอัตโนมัติ Variational นั่นคือแต่ละมิติของ Z (เวกเตอร์แฝง) เป็นจำนวนเต็มแบบแยกส่วนแทนการแจกแจงแบบปกติอย่างต่อเนื่องโดยทั่วไปใช้ในขณะที่เข้ารหัสอินพุต
Vaes ประกอบด้วย 3 ส่วน:
คุณอาจถามเกี่ยวกับความแตกต่าง VQ-VAES นำมาที่โต๊ะ มาแสดงรายการกันเถอะ:
วัตถุที่สำคัญในโลกแห่งความเป็นจริงหลายแห่งไม่ต่อเนื่อง ตัวอย่างเช่นในภาพเราอาจมีหมวดหมู่เช่น "แมว", "รถยนต์" ฯลฯ และอาจไม่สมเหตุสมผลที่จะแทรกระหว่างหมวดหมู่เหล่านี้ การเป็นตัวแทนที่ไม่ต่อเนื่องก็ง่ายต่อการสร้างแบบจำลอง
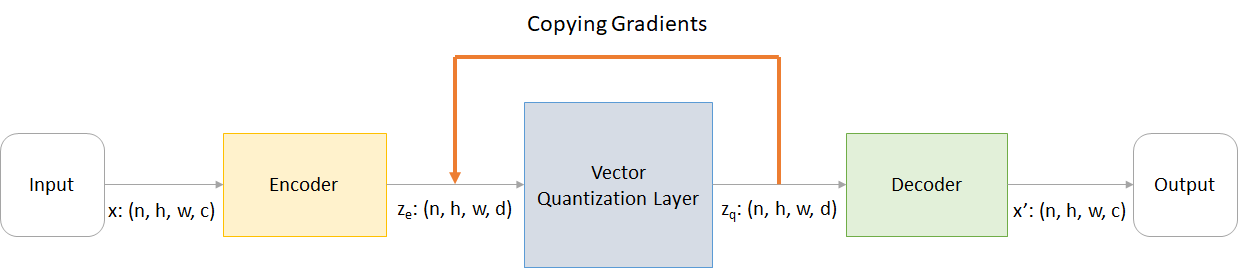
ที่ไหน:
n : ขนาดแบทช์h : ความสูงของภาพw : ความกว้างของภาพc : จำนวนช่องในภาพอินพุตd : จำนวนช่องในสถานะที่ซ่อนอยู่ นี่คือภาพรวมโดยย่อของการทำงานของเครือข่าย VQ-VAE:
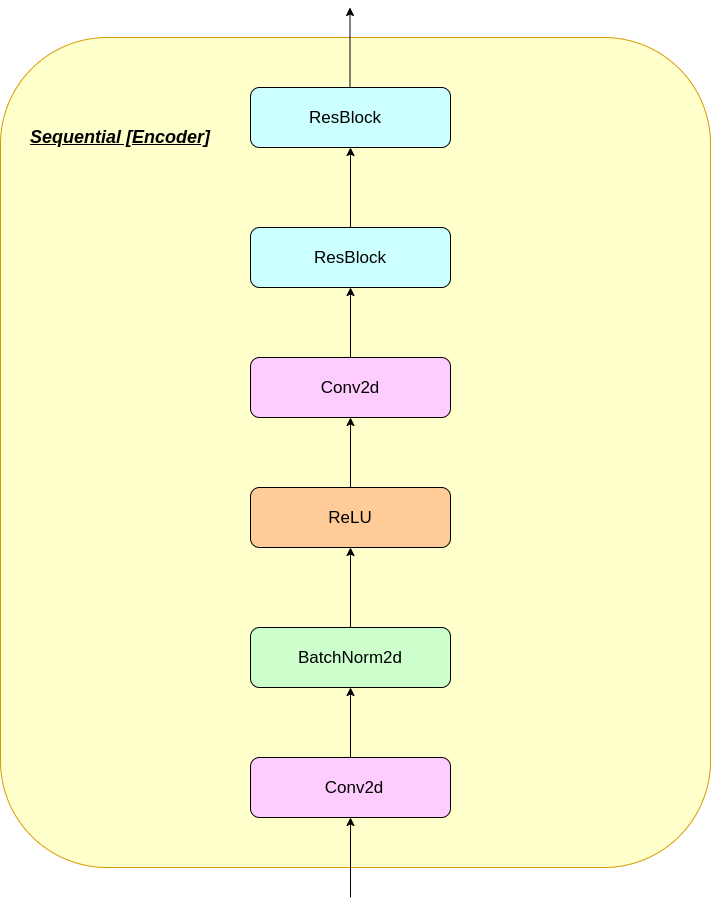
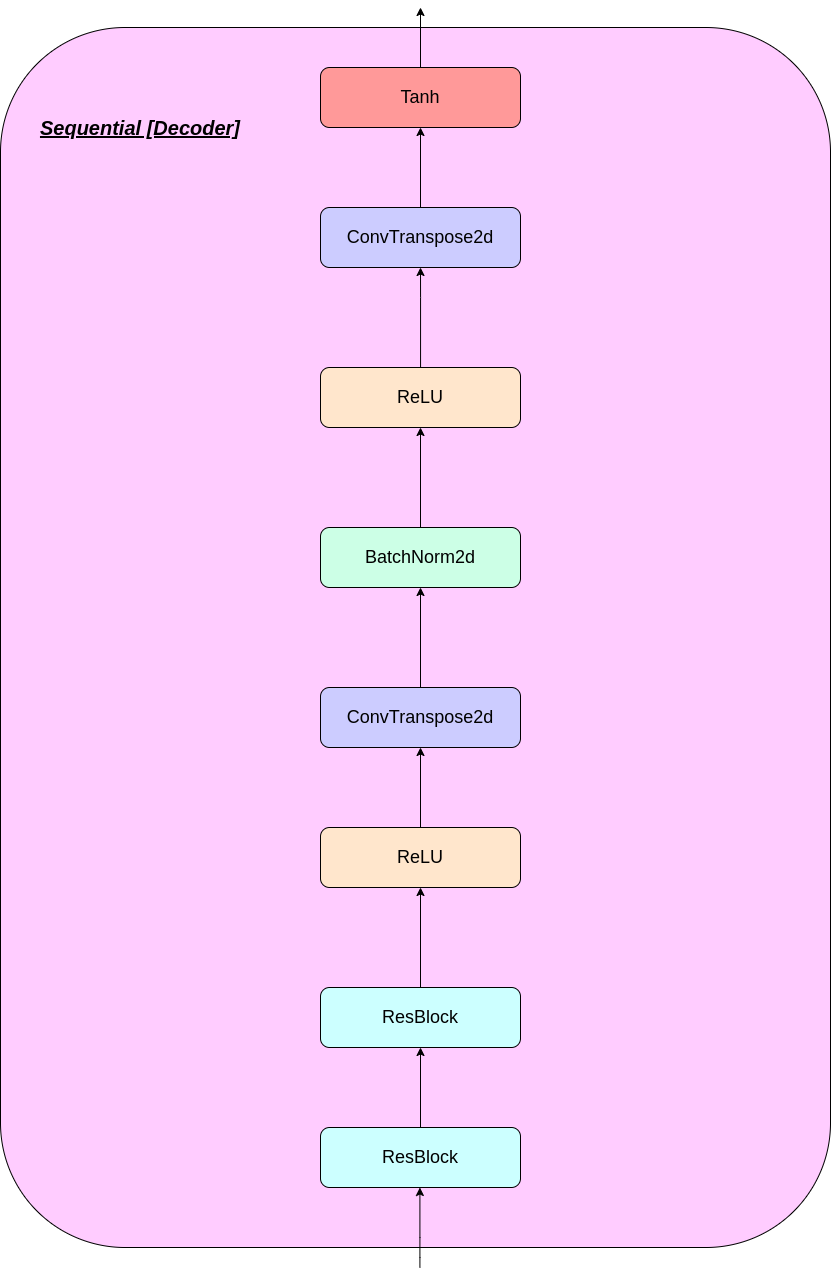
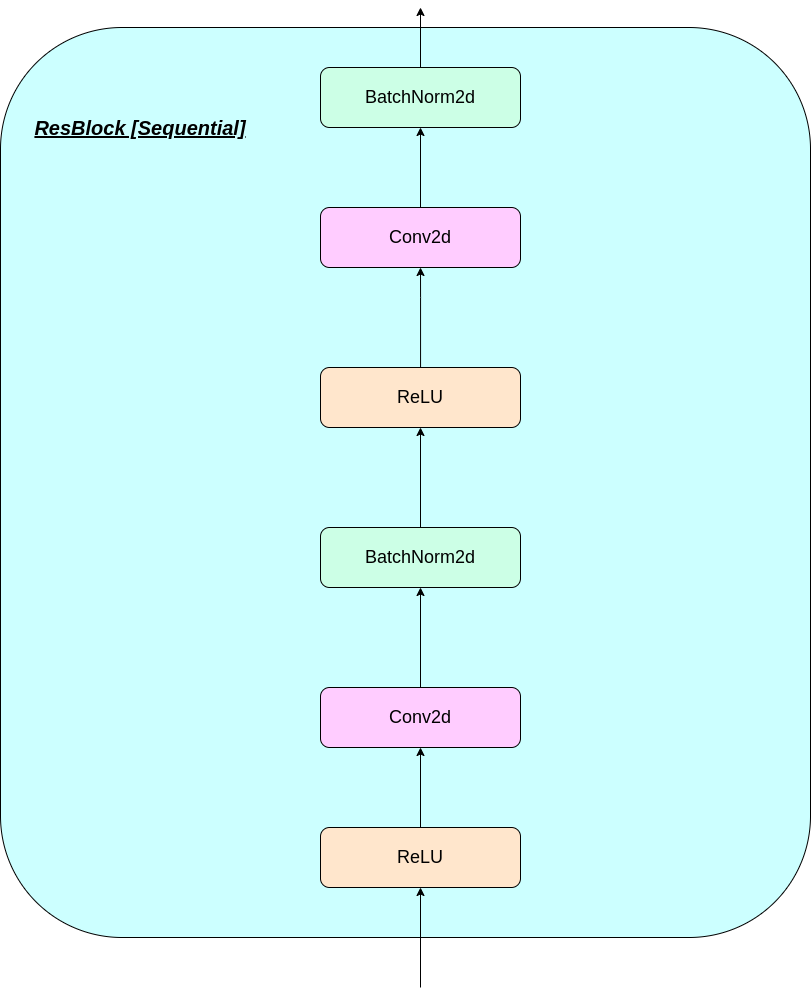
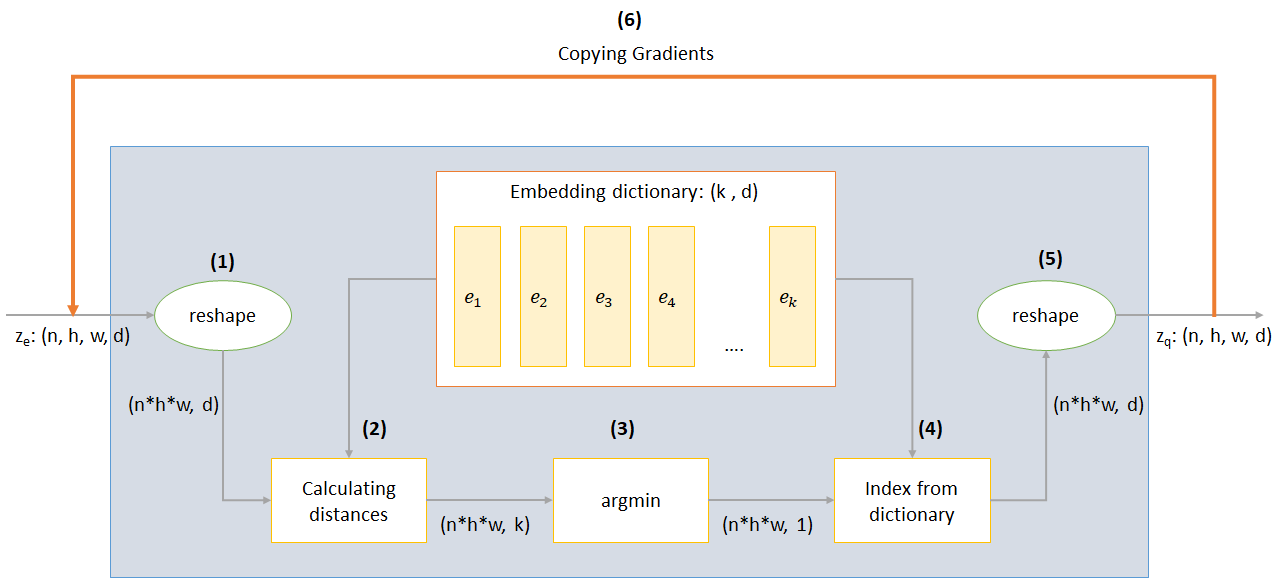
การทำงานของชั้น VQ สามารถอธิบายได้ในหกขั้นตอนตามหมายเลขในรูป:
VQ-VAE ใช้การสูญเสีย 3 ครั้งเพื่อคำนวณการสูญเสียทั้งหมดในระหว่างการฝึกอบรม:
การสูญเสียการสร้างใหม่: เพิ่มประสิทธิภาพตัวถอดรหัสและตัวเข้ารหัสเป็น VAE เช่นความแตกต่างระหว่างภาพอินพุตและการสร้างใหม่:
reconstruction_loss = -log( p(x|z_q) )
การสูญเสียรหัส: เนื่องจากความจริงที่ว่าการไล่ระดับสีผ่านการฝังระบบอัลกอริทึมการเรียนรู้พจนานุกรมซึ่งใช้ข้อผิดพลาด L2 เพื่อย้ายเวกเตอร์ฝังตัว E_I ไปยังเอาต์พุตตัวเข้ารหัส
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG หมายถึงตัวดำเนินการไล่ระดับสีแบบหยุดหมายความว่าไม่มีการไล่ระดับสีไหลผ่านสิ่งที่มันใช้กับอะไร)
การสูญเสียความมุ่งมั่น: เนื่องจากปริมาณของพื้นที่ฝังตัวไม่มีมิติมันสามารถเติบโตได้โดยพลการหาก Embeddings E_I ไม่ฝึกเร็วเท่ากับพารามิเตอร์ของตัวเข้ารหัส
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(βเป็นไฮเปอร์พารามิเตอร์ที่ควบคุมจำนวนเงินที่เราต้องการชั่งน้ำหนักการสูญเสียความมุ่งมั่นเมื่อเทียบกับส่วนประกอบอื่น ๆ )
คุณสามารถดาวน์โหลด repo หรือโคลนได้โดยเรียกใช้ต่อไปนี้ในพรอมต์ CMD
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
คุณสามารถฝึกอบรมโมเดลได้ตั้งแต่เริ่มต้นด้วยคำสั่งต่อไปนี้ (ใน Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - ชื่อของโฟลเดอร์ข้อมูลdata-folder - ชื่อของโฟลเดอร์ข้อมูลdevice - ตั้งค่าอุปกรณ์ (CPU หรือ CUDA, ค่าเริ่มต้น: CPU)hidden-size - ขนาดของเวกเตอร์แฝง (ค่าเริ่มต้น: 40)k - จำนวนเวกเตอร์แฝง (ค่าเริ่มต้น: 512)batch-size - ขนาดแบทช์ (ค่าเริ่มต้น: 128)num-epochs - จำนวนยุค (ค่าเริ่มต้น: 10)lr - อัตราการเรียนรู้สำหรับ Adam Optimizer (ค่าเริ่มต้น: 2E -4)beta - การมีส่วนร่วมของการสูญเสียความมุ่งมั่นระหว่าง 0.1 ถึง 2.0 (ค่าเริ่มต้น: 1.0)num-workers - จำนวนคนงานสำหรับการสุ่มตัวอย่างวิถี (ค่าเริ่มต้น: cpu_count () - 1) โปรแกรมจะดาวน์โหลดชุดข้อมูล MNIST โดยอัตโนมัติและบันทึกไว้ในโฟลเดอร์ PATH_TO_MNIST_dataset (คุณต้องสร้างโฟลเดอร์นี้) สิ่งนี้เกิดขึ้นเพียงครั้งเดียว
นอกจากนี้ยังสร้างโฟลเดอร์ logs และ models โฟลเดอร์และภายในพวกเขาจะสร้างโฟลเดอร์ที่มีชื่อที่คุณส่งผ่านเพื่อบันทึกบันทึกและจุดตรวจสอบรุ่นภายในตามลำดับ
ในการสร้างภาพใหม่จาก Z สุ่มตัวอย่างจากหน่วยเกาส์เซียนเรียกใช้คำสั่งต่อไปนี้ (ใน Google Colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - ชื่อไฟล์ที่มีโมเดลinput - MNIST หรือแบบสุ่มdevice - ตั้งค่าอุปกรณ์ (CPU หรือ CUDA, ค่าเริ่มต้น: CPU)hidden-size - ขนาดของเวกเตอร์แฝง (ค่าเริ่มต้น: 40)k - จำนวนเวกเตอร์แฝง (ค่าเริ่มต้น: 512)filename - ชื่อที่จะบันทึกไฟล์ใด มันสร้างภาพ 10*10 กริดซึ่งบันทึกไว้ในโฟลเดอร์ชื่อ generatedImages
คุณสามารถใช้โมเดลที่ผ่านการฝึกอบรมมาก่อนโดยดาวน์โหลดจากลิงค์ใน model.txt
ที่เก็บมีไฟล์ต่อไปนี้
modules.py - มีโมดูลต่าง ๆ ที่ใช้ในการสร้างแบบจำลองของเราVQ-VAE.py มีฟังก์ชั่นและรหัสสำหรับการฝึกอบรมโมเดล vq-vae ของเราvector_quantizer.py - คลาส quantization เวกเตอร์ถูกกำหนดไว้ในไฟล์นี้generate-py สร้างภาพใหม่จากรุ่นที่ผ่านการฝึกอบรมมาก่อนmodel.txt - มีลิงก์ไปยังรุ่นที่ผ่านการฝึกอบรมมาก่อนREADME.md - readme ให้ภาพรวมของ reporeferences.txt - การอ้างอิงที่ใช้ในขณะสร้าง repo นี้readme_images - มีภาพต่าง ๆ สำหรับ readmeMNIST - มีชุดข้อมูล MNIST ซิป (แม้ว่าจะถูกดาวน์โหลดโดยอัตโนมัติหากจำเป็น)Training track for VQ-VAE.txt มีค่าการสูญเสียในระหว่างการฝึกอบรมโมเดล VQ-VAE ของเราlogs_VQ-VAE มีบันทึก Tensorboard ซิปสำหรับรุ่น VQ-VAE ของเรา (สร้างโดยโปรแกรมโดยอัตโนมัติ)testers.py - มีฟังก์ชั่นบางอย่างเพื่อทดสอบโมดูลที่กำหนดไว้ของเราคำสั่งให้เรียกใช้ Tensorboard (ใน Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
ภาพฝึกซ้อม
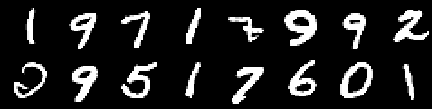
ภาพจากยุค 0th

ภาพจากยุคที่ 2
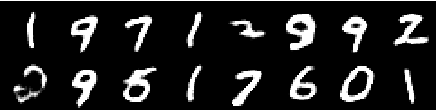
ภาพจากยุคที่ 4
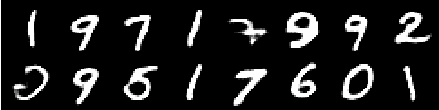
ภาพจากยุค 6
ภาพจากยุค 8
ภาพจากยุคที่ 10
การสร้างใหม่ยังคงปรับปรุงและในตอนท้ายเกือบจะคล้ายกับภาพการฝึกอบรม _set ซึ่งสะท้อนให้เห็นในค่าการสูญเสีย (เช็คอินแท Training track for VQ-VAE.txt )
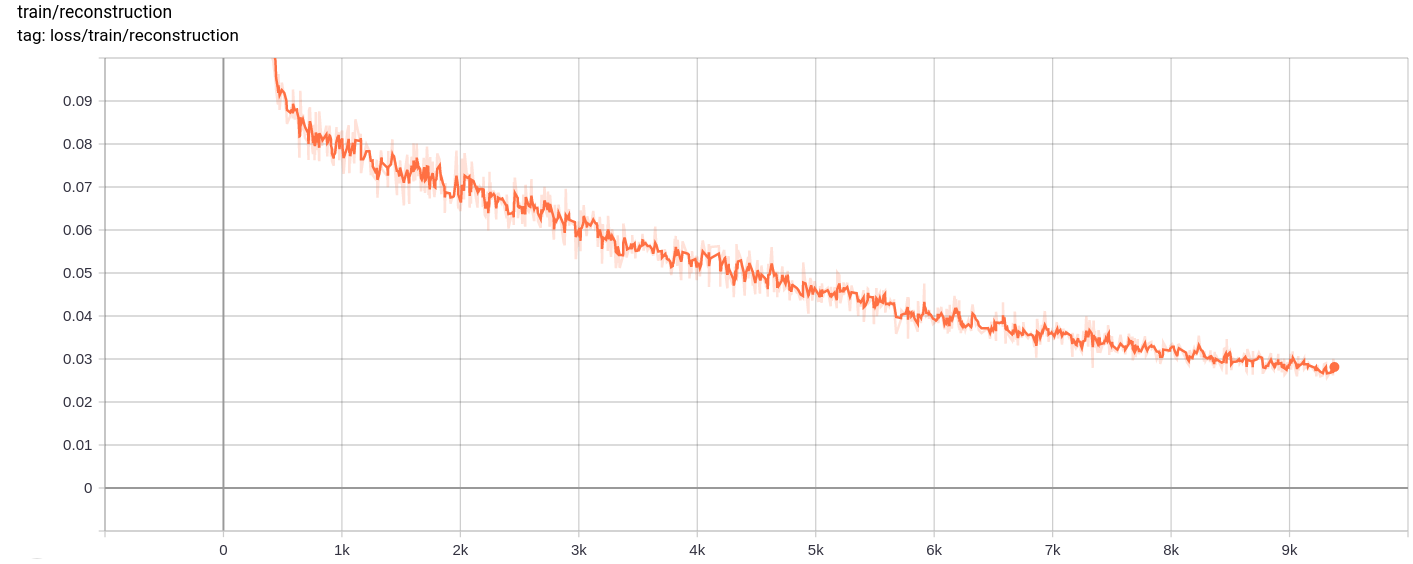
การสูญเสียการฟื้นฟู
การสูญเสียปริมาณ
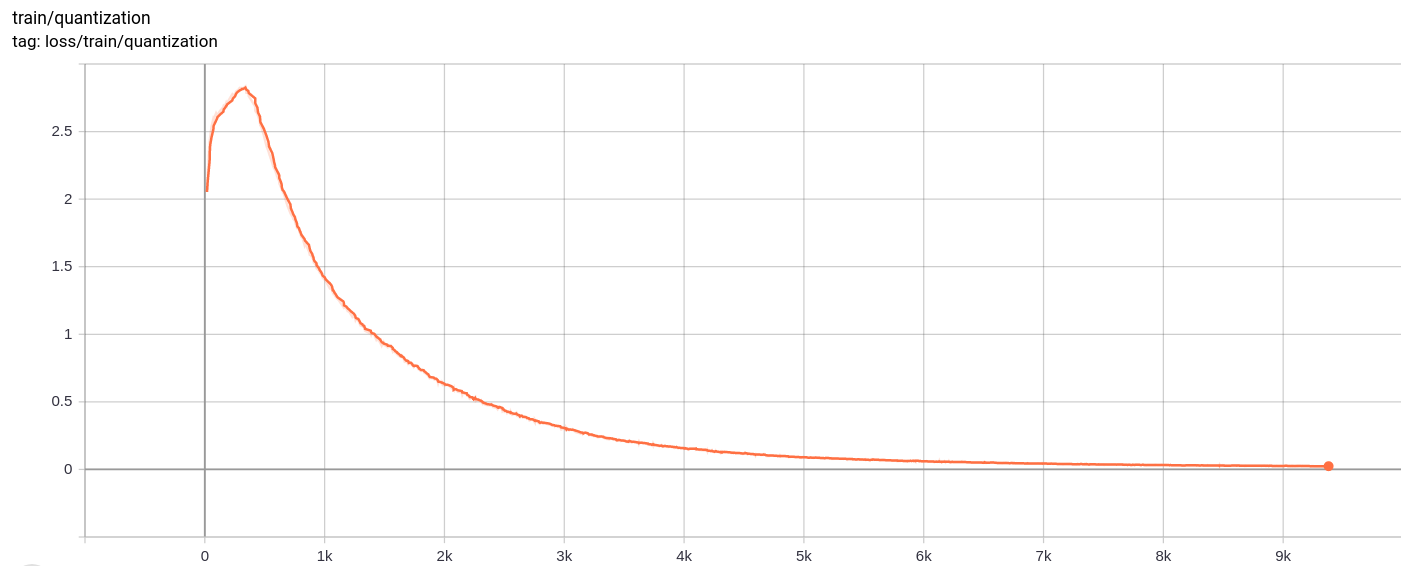
total_loss
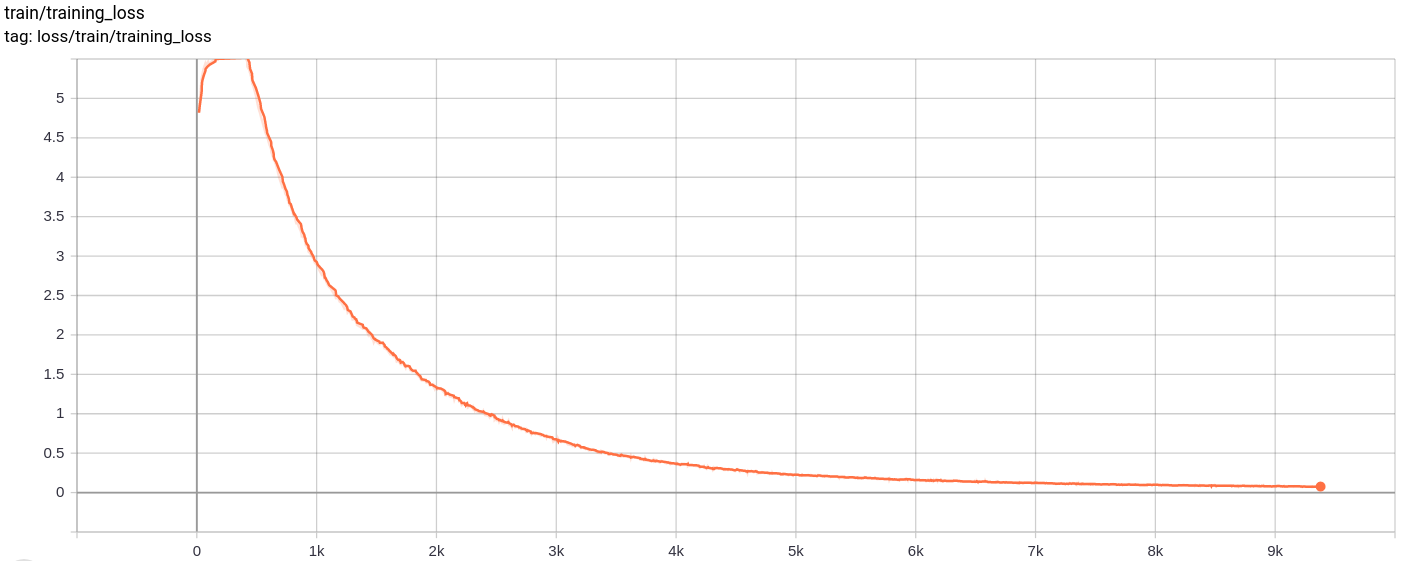
การสูญเสียทั้งหมดการสูญเสียการฟื้นฟูและการสูญเสียปริมาณลดลงอย่างสม่ำเสมอตามที่คาดไว้
testing_loss
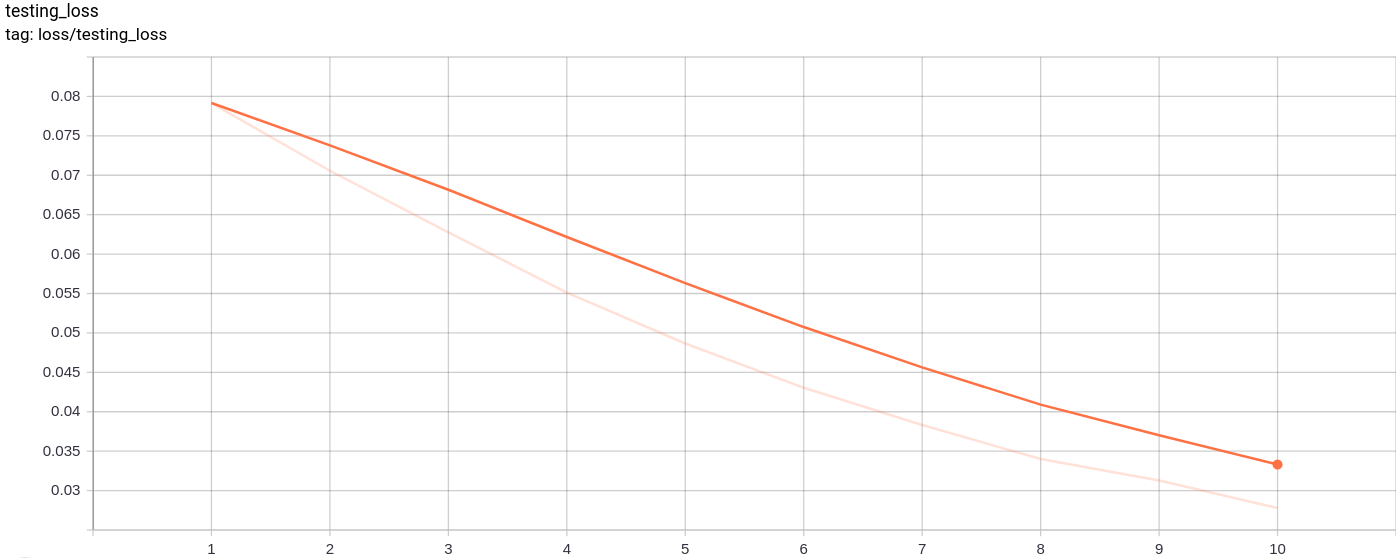
การสูญเสียการทดสอบลดลงอย่างสม่ำเสมอตามที่คาดไว้
กริดภาพต่อไปนี้ถูกสร้างขึ้นหลังจากผ่านภาพ MNIST เป็นอินพุต:

รุ่นค่อนข้างดี
กริดภาพต่อไปนี้ถูกสร้างขึ้นหลังจากผ่าน AZ ตัวอย่างแบบสุ่มจากหน่วยเกาส์เซียนเป็นอินพุตไปยังแบบจำลองแล้วผ่านตัวถอดรหัส


ภาพไม่ได้ดูสมบูรณ์แบบ การปรับแต่งขนาดของพื้นที่แฝงจำนวนเวกเตอร์ฝัง ฯลฯ สามารถช่วยในการสร้างภาพสุ่มที่ดีขึ้น
โมเดลได้รับการฝึกฝนบน Google Colab เป็นเวลา 10 ยุคโดยมีขนาดแบทช์ 128
หลังจากการฝึกอบรมโมเดลก็สามารถสร้างภาพอินพุตได้ค่อนข้างดีและยังสามารถสร้างภาพใหม่ได้แม้ว่าภาพที่สร้างขึ้นจะไม่ดีนัก
การฝึกอบรมเช่นเดียวกับการสูญเสียการทดสอบยังลดลงเกือบ monotonically
ฉันสังเกตเห็นว่าการฝึกอบรมแบบจำลองสำหรับยุคมากกว่า 10-20 นั้นให้ผลลัพธ์ที่แนะนำสัญญาณที่เป็นไปได้ของการ overfitting ในโมเดล นอกจากนี้ฉันยังทดลองกับมิติที่แตกต่างกันของพื้นที่ latednt และใน dimension = 40 ให้ผลลัพธ์ที่ดีที่สุด ช่วงที่ดีที่สุดสำหรับมิติออกมาอยู่ระหว่าง 16-42
แหล่งข้อมูลต่อไปนี้ช่วยให้พื้นที่เก็บข้อมูลนี้ได้มาก


