Python 3.8 和 conda,如果想使用 GPU 环境,请获取 Conda CUDA
conda create -n $YOUR_PY38_ENV_NAME python=3.8
conda activate $YOUR_PY38_ENV_NAME
pip install -r requirements.txt
对于我们的项目,输入采用形状为 (B, T, C, H, W) 的数组形式,其中数组中的每个帧的固定大小为 128x128。每个视频中的帧数为 30,从而形成 (B, 30, 3,128, 128) 的形状。在使用这个项目之前,您可能需要对视频数据进行相应的预处理。在代码中,我们提供了一个形状为(46,30,3,128,128)的示例数组“city_bonn.npy”。该数组包含 Cityscape 数据集中来自波恩市的 46 个视频。下面是一个示例命令。
您可以通过选择 start_idx 和 end_idx 的值来控制要处理的视频。确保所选范围不超过 B 的值(数据集中的视频数量)。
python city_sender.py --data_npy "data_npy/city_bonn.npy" --output_path "your path" --start_idx 0 --end_idx 1
在基准部分,我们提供了计算 H.264 和 H.265 压缩指标的代码。此代码的输入应该是 30 帧 128x128 图像帧,最好以“frame%d”格式命名。
数据集的文件夹结构如下
/your path/
- frame0.png
- frame1.png
- ...
- frame29.png
对于project_str,这只是一个用于区分数据的字符串。这里我们使用“uvg”。
python bench.py --dataset "your path" --output_path "your path" --project_str uvg
关于检查点,我们使用两组。一组包括“checkpoint_900000.pt”,用于视频生成部分。另一组包含六组检查点,这些检查点将用于图像压缩部分,对应六种不同的压缩质量。
这六个权重需要移动到“checkpoints/neural network”文件夹中。
| 拉姆达 | 质量 |
|---|---|
| 0.45 | q5 |
| 0.15 | q4 |
| 0.032 | q3 |
| 0.015 | q2 |
| 0.008 | q1 |
| 0.004 | q0 |
这个单独的权重需要移动到“checkpoints/sender”文件夹中。
| 扩散模型的检查点 |
|---|
| 扩散模型的检查点 |
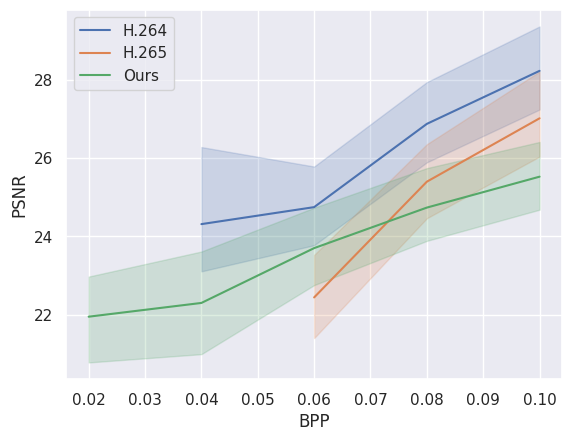
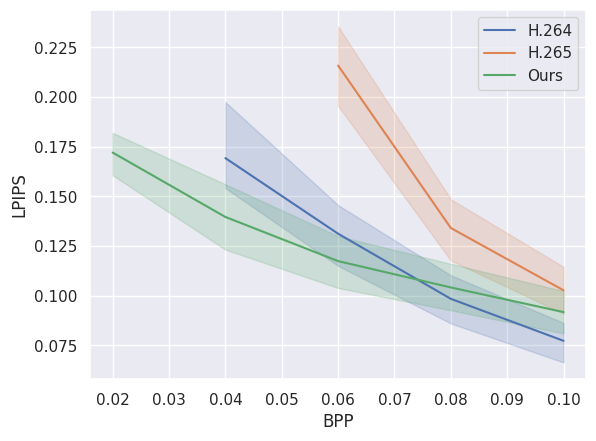
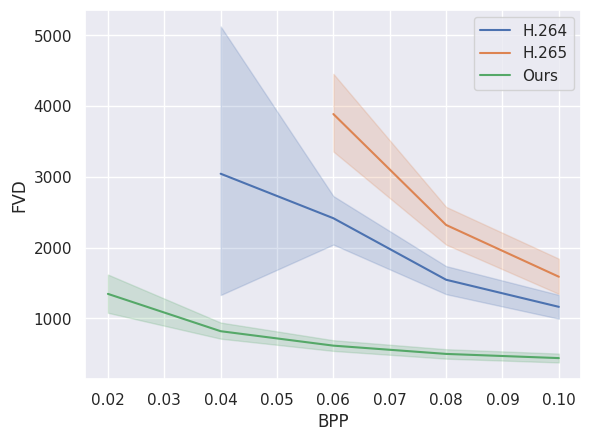
下图将我们的模型的压缩性能与传统视频压缩标准 H.264 和 H.265 进行了比较。可以看出,我们的模型在低比特率(bpp)下优于它们。这些数据是根据 city_bonn.npy 的前 24 个视频计算得出的。